Rosetta: A Robust Space-Time Optimized Range Filter for Key-Value Stores
0x00 基本思路
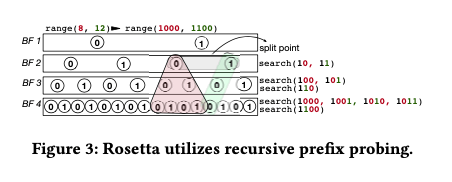
这篇Paper是关于LSM-tree中一个Range Filter的一个设计以及其数学方面的一些分析。目前LSM-tree使用Bloom Filter来优化查询一些不存在key的情况,而这个Bloom Filter只支持单点查询的Filter,不支持Range Filter,也就是一个范围内有木有数据存在这个KV Store。在SIGMOD ’18上面发表的一篇论文是基于Succinct的。这篇Paper则提出来一种基于Boom Filter来实现Range Filter的法案,和之前的一些统计方式类似,比如Persistent Filter,使用了层次式的结构。其基本结构如下,这里显示的不同层的Filter差距为一个bit,是一个示意。Paper中实际算法描述的时候为下一层的prefix长为前一层的两倍(最后一层应该特殊处理)。对于添加数据的时候,对应的filter构建就是以其不同长度的prefix来构建不同的Bloom Filter的过程。这里又有点Segment Tree的思路。

在这样的设计下面,查询的操作基本思路如下:1. 对应点查询,很简单的就是对应到最后一层的Bloom Filter的查询;2. 对应范围查询,基本的思路如下图,查询的思路和在Segment Tree类似结构中的查询类似。每次往下查询,都是选取更长的prefix,将以每个可能的prefix都查询一次。在一些情况下,结构可能不必要查询到最后面就可以返回。
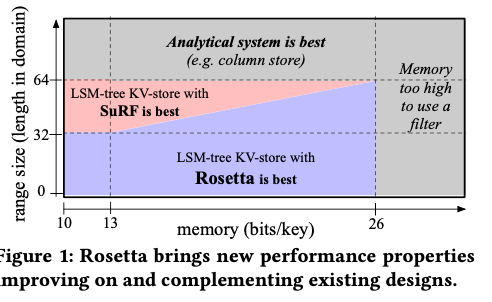
结构本身不是很复杂,Paper中对此进行了详细的数学方面特性的分析,涉及到不少的推导,和这个团队的其它论文的风格很相似呀。得出一个核心结论如下图:对应Paper中的分析,核心就是一般来说,对于Short and Medium Range Queries,Rosetta比现在的SuRF更加有优势,而更大的Range,则直接就是列存更好,SuRF更好的范围比较小。另外,在使用内存越多的时候,Rosetta比SuRF的优势家更加明显,大到一定程度的时候,两者的内存开心都显得划不来了。
0x01 评估
这里的具体内容可以参看[1].
EvenDB: Optimizing Key-Value Storage for Spatial Locality
0x10 基本思路
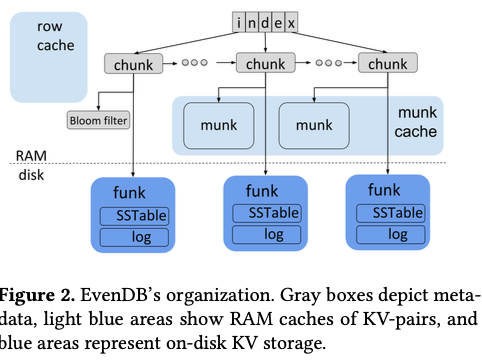
从将故事的角度来看,这篇Paper讨论的是KV Store在Spatial Locality上面的改进。总的来说,EvenDB的思路是一种单层的、range partition的LSM-tree的一种变体。基本结构如下图。整个的数据被分为一个个的chunk,就是一个range partition。一个chunk对于来磁盘上面的一个SSTable,以及一个log,另外在内存中可以存在一个munk,类似于buffer pool。在此基本结构上面的其它的一些设计:
- Chunk的信息在内存中排列卫一个有序的list,在此之上有一个index,用于加速查找。在主体的结构之外,row cache作为一个cache存在。另外bloom filters也从LSM-tree中借鉴。存在muck的时候,这个bloom filter不会存在,在muck从内存中驱逐的时候,这个bloom filter会被重新创建。
- 在写入操作的时候,数据先写入到对应chunk的log中。在log增长到一定大小的时候,会进行一个类似于compaction的操作,这里称之为rebalance。一个chunk的大小为1k pages左右,在什么样的程度进行rebalance涉及到各个方面的tradeoff。这样的设计处理不好的话容易造成性能的周期性变化和明显的抖动。
FlatStore: An Efficient Log-Structured Key-Value Storage Engine for Persistent Memory
0x20 基本思路
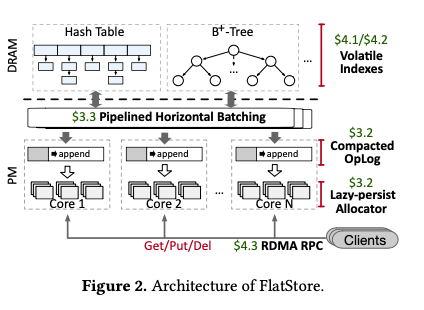
这篇Paper描述的FlatStore是一个为PM设计的Key-Value Store。FlatStore的基本思路是将KVS的操作作为OpLog保存到PM上面,而在DRAM中保存一个完整的数据结构。其基本的结构如下,在FlatStore之上的数据结构实现可以是多样的,比如Hash Table和B+tree。改动结构的操作作为OpLog在被Pipelined Horizontal Batching之后被作为Compacted OpLog写入到Log中。在此基本结构上面的几个功能的设计:
-
Compacted OpLog and Lazy-Persist Allocator,在FlatStore的基本操作中,一个Put/Del操作会将改动的Key-Value信息直接写入到每个CPU-Core一个的CompactOpLog中,相当于记录下这个操作。后面会直接改动内存中index结构。这样涉及在实现持久化保存数据的基础之后能比较好的发挥读取性能和写入的性能。读取的性能依赖于内存中的index,而写入性能依赖于顺序写入OpLog。为减小OpLog的大小,只会包含最基本的几个部分的信息,
each log entry consists of five parts, among them, Op records the operation type (i.e., Put or Delete), Emd means whether the key-value item is placed at the end of the log entry, and Version is introduced to guarantee the correctness of log cleaning we use 8-byte keys. ... Ptr is used to point to the actual records when it is stored out of the OpLog. Otherwise, the value, as well as its size, are placed directly at the end of the log.这里的一个问题是Key都是8byte的,另外Value会根据其大小选择保存在log之中还是之外。Lazy-persist Allocator则是为了优化在PM上面优化内存分配。内存分配需要记录下关于内存使用、空闲情况的元数据,一般情况下需要在每次分配之后持久化这些信息。而这里则根据这些分配的信息会记录在OpLog中,而选择了Lazy-persist的方式。如果PM分配的信息在crash之前没有及时的持久化,可以从OpLog中恢复出来。所以这里一个PUT操作操作的基本流程如下:1. 从Lazy-persist Allocator分配对应保存value的空间,并写入数据,然后将这些数据持久化;2,持久化一个log entry,记录下这个操作和之前写入的数据的信息。然后写入log,确保持久化之后更新log的tail信息;3. 更新内存中的index。
-
Pipelined Horizontal Batching。批量处理是一个常见的优化方式。这里提出的批量处理的方式称之为Pipelined Horizontal Batching。其中Horizontal于一般的Vertical batching对应。一般的Vertical batching指的是每次Core操作其Log批量处理的方式,示意突下。Vertical batching可以将一些flush操作合并,并且更能发挥硬件的写入性能。Vertical batching带来的一个缺点是延迟的提高。延迟和带宽一直是相互掣肘的问题。这里提出的优化思路就是Horizontal Batching。基本思路是让一个Core可以窃取其它Core上面Log中to-be-persisted log entries来组织成为一个Batch。为了从其它Core窃取到log entries,一个Core会获取一个global lock,在获取到这个lock之后,一个Core成为一个leader,其它的核心成为follwer。leader从其它核心拉取log entries,然后批量处理。其它的follwer会等待leader操作。这里的思路和一些LSM-tree实现的思路类似。在此基础之上的继续优化就是Pipelined Horizontal Batching,即一个Core成为follwer之后,不是简单地等待,而是继续处理到来的请求,到达一种类似于异步等待的效果。
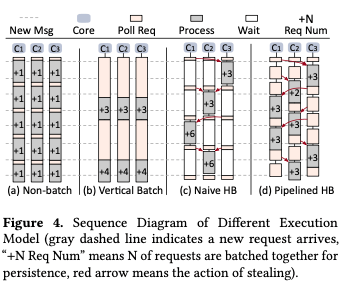
-
Log Cleaning and Recovery。有Log的系统都需要一些处理Log无限制增长的方式,
To recycle a NVM chunk, the cleaner first scans the chunk to determine the liveness of each log entry. This is achieved by comparing the Version of the log entry with the newest one in the in-memory index. Then, all the live log entries are copied to a newly allocated NVM chunk. Identifying the liveness of tombstones (for Del) is more complicated which can be safely reclaimed only after all the log entries related to this KV item have been reclaimed.FlatStore另外的一个问题就是Recovery,Paer中提出的思路就是简单地重放OpLog。在Paper中的数据是可以在40s内重放10亿个。为了缩短这个时间可以使用定期checkpoint index的方法,在paper中只是提了一下。
##UniKV: Toward High-Performance and Scalable KV Storage in Mixed Workloads via Unified Indexing
0x30 基本思路
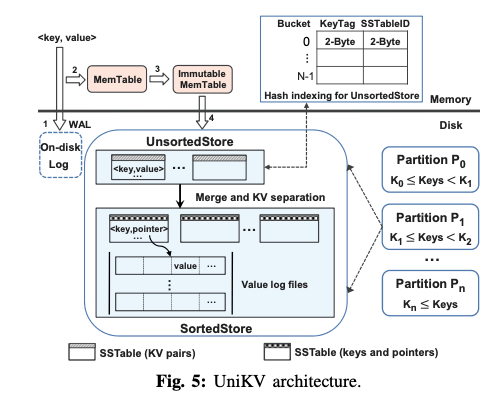
这篇Paper从title中看出的重点是如何使得KV Store适应Mixed Workloads,这里还是在LSM-tree的框架上面进行优化的。这篇Paper中前面的数据分析主要就是来表明不同类型的index适应不同的workload。总之UniKV这里设计的基本结构如下,主要的特点是磁盘上面的第一次是unsorted的。这个思路在前面的一些LSM-tree设计中也使用过,其基本思路是使用WAL直接作为L1的数据,来避免一些重复的数据写入,这样L1的数据也是没有排序的。这里从下面的架构中看得出这里的L1并不是直接使用了WAL。总结下来,这篇Paper主要是四个内容:
- Differentiated indexing,UniKV在LSM-tree的总体架构之上,将LSM-tree磁盘上面的结构分为sorted和unsorted两个部分。unsorted的部分使用hash index,这个index保存在内存之中。unsorted部分的数据还是以SSTable文件的格式保存,但是移除了Bloom Filter来节省内存空间和避免一些不必要的操作。这里去掉Bloom Filter主要是因为这里的索引还是都在内存里面的。Immutable Memtable的数据flush到L1的时候,以append only的方式写入,而hash index使用的是一种cuckoo hash table。
- Partial KV separation,这里的思路是在前面LSM-tree的一些针对大value的情况下,优化写入放大的一种优化的继续优化。unsorted部分merge到sorted部分的时候,会将value以append only的方式写入一个value log file中。
- Dynamic Range Partitioning。分区在Paper中描述是更好的expand storage in a scale-out manner,就是将原来的tree分为若干的range partition。partition分裂的时候,选择的是一个分裂为两个,这里会涉及到分裂unsorted和sorted的两个部分:分裂操作的时候,会请求一个锁,来停止写入操作,后面的操作需要将所有的keys都排序。操作首先会将memtable的数据flsuh到unsorted部分。然后对下面的SSTables进行merge操作,后面再将其分裂为两个相等的部分。得到分裂点的key K之后,会先将unsorted部分的分开写入到两个部分。sorted部分的key部分处理之后也会被重新写入。这部分操作完成之后,就可以重新写入操作。这里还有sorted部分的values没有处理,对于这部分的数据使用lazy的思路,即在GC的时候处理value的split。
- Scan optimizations and consistency,UniKV使用的Key Value分离策略以及unsorted+sorted思路一个缺点是scan性能会一般。为此UniKV正对这个进行了一些优化:在发现scan请求超过一个阈值scanMergeLimit的时候,,会将unsorted部分的sstable在后台整理为一个大的排序好的文件;对于SortedStore的部分,使用并发请求的策略利用好SSD的性能特点,另外就是利用OS预取的功能。在consistency上面,主要还是原来的WSL的思路,另外的hash index使用checkpoint的方式定期写入磁盘(It saves the hash index in a disk file when flushing every half of the UnsortedLimit SSTables from memory to the UnsortedStore)。重启之后hash index重建使用最后一些checkpoint的数据和后面写入的数据来一起重建。
参考
- Rosetta: A Robust Space-Time Optimized Range Filter for Key-Value Stores, SIGMOD ‘20.
- EvenDB: Optimizing Key-Value Storage for Spatial Locality, EuroSys ’20.
- FlatStore: An Efficient Log-Structured Key-Value Storage Engine for Persistent Memory,ASPLOS ’20.
- UniKV: Toward High-Performance and Scalable KV Storage in Mixed Workloads via Unified Indexing, ICDE ‘20.
