Long-lived Transactions Made Less Harmful
0x00 基本思路
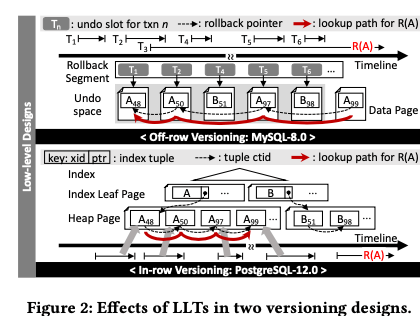
这篇Paper是关于如何处理数据看长事务的。在MVCC的系统中,数据以多版本的方式保存,一个版本的数据不会在有事务访问的时候,就可以进行回收操作。一般的系统就是以目前系统中活动的“最老”的事务来判断哪些版本的数据可以进行回收操作。这样的方式在有长事务的情况下会导致一些数据迟迟不能回收,对系统的正常运行影响比较大。这里提出的思路是Single In-row Remaining Off-row (SIRO) versioning,即只将一条记录目前的数据和其之前一个版本的数据放到数据Page中,另外的版本放到另外的一个地方来保存。SIRO的思路在两个场景的开源数据库MySQL和PostgreSQL中都实现了,而且测试的结果看来很不错。不同版本的数据存储使用的方式一般就是in-row的方式或者是off-row的方式,而如下图所示,MySQL使用的就是off row的方式,非当前的数据会被保存到undo space。而PostgreSQL使用的是in row的方式,旧的版本也会保存到一般的数据page中。这里的思路优点类似于两者思路的结合,又加上了其它的一些优化。对于PostgreSQL,这里分析认为PostgreSQL的方式会造成Repeated page splits would severely impinge on a degree of concurrency,而MySQL的方式 latch duration on a page increases as a version chain grows in MySQL, whereas travers ing an elongated version chain from the oldest version takes time in PostgreSQL。另外在存在实际运行的环境中,存在长事务的情况下,PostgreSQL花费在versionning scan和index reorganizing的时间会明显增大。而MySQL花费在page latch contention上面的时间占了很大的一个部分。
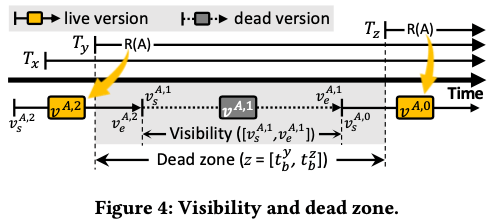
MVCC GC的方式在前面的SAP HANA一篇Paper中有比较好的优化思路。SAP HANA的思路是不是以最老的事务最为一个版本的数据可不可以回收来判断,而是引入了interval的概念。这样使得系统中即使存在长事务,也可以将这个上事务后面在产生的一些不会在访问的版本回收,这个思路后面在Hyper又被采用了。这里也采用了类似的思路来判断一个版本是否可以回收,描述方式存在一些区别,基本的思路如下图所示。Paper中描述的时候都是以timestamp来记录一个version,现在的数据一般也都是实际使用了时间戳的方式,但是是不一定的。这里理论上的描述如下,
- 一个数据有一个记录的集合R组成,R中的记录都是已经commited的。另外的一个集合V表示R中记录的所有的版本。对于一个记录的一个版本的数据,其时间上可见的范围用$V_s^{r,i}$,到$V_e^{r,i}$,V来表示,一般情况下$V_e^{r,i}$等于更新的一个版本的$V_s^{r,i-1}$,这里使用i来表示是一条记录的第几个版本,0表示最新的版本。而对于i=0的版本,其$V_e^{r,0}$为∞。有些地方将这段时间称之为 valid time。一般版本的数据对于一个事务可见的情况下要满足这个事务的begain timestamp,$t_b^k$,时这个事务已经提交,而且这个版本的数据的end timestamp不大于这个事务的start timestamp。一个dead version指的是不会在被运行的事务在访问的版本,而且得满足一旦成为了dead version,就不会变化了,即不能变得重新可见。如果对于目前运行中的时候,根据其start timestmap的信息就可以知道一个版本是否为dead version。
- 如果将运行的事务安装start timestamp排序,那么有效时间落在两个相邻事务中间的版本就是dead version。这里称之为dead zone(a time range 𝑧=[𝑧𝑠 , 𝑧𝑒 ] whose start (𝑧𝑠 ) and end (𝑧𝑒 ) times are set to the begin timestamps of two consecutive transactions)。有使用$Z_T$来表示dead zone的集合,即$Z_T={z^1(=[-∞,t_b^1),\cdots,z^m(=[t_b^{m-1},t_b^m),z^{m+1}(=t_b^m, C^T)}$,这里$C^T$表示目前的时间。给定一个$Z^T$和目前运行中的事务集合T,其可以被回收只有其可见时间,its visibility,在$Z^T$中的任意一个dead zone之内。另外这里一个可以用来优化系统实现的特性事,如果一个时刻中系统中没有运行中的事务,那么处理每个记录除了最后一个版本的数据,其余的版本都是处于dead zone中,可以被回收。
- 另外一个要处理的问题就是事务的时间戳和版本的时间戳的问题。前面讨论使用的是记录的一个版本中记录的时间戳是事务提交的时间戳,但是目前的一些数据库,包括这里提到的两个数据数据,其中保存的时间戳是事务开始的时间戳。计算可见性的时候就避免麻烦。解决这个问题的方式是使用一个read view的方式,记录下目前运行事务的start timestamp,这里将其表示为$T_k^{rv}$,即一个事务$T_k$的read view。对于一个事务,其访问到了一个版本的记录是一件提交了的,需要满足条件:一个是创建这个版本记录的事务的start timestamp,s-ts早于当前事务的start timestamp且s-ts不在这个事务的read-view中。一个版本$V^{r,t}$在事务$T_k$的snapshot read中要满足条件:创建这个版本的事务已经提交,且下一个版本没有被提交 or 没有下一个版本。而MySQL 和PostgreSQL都是使用类似的read view的方式。
0x01 基本架构
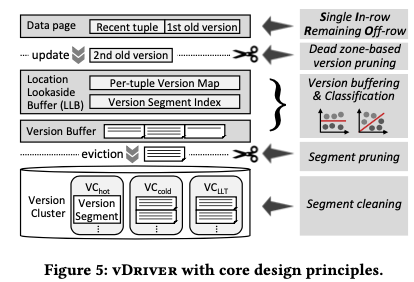
这里使用的实现single version in-row and remaining versions off-row的组件是vDriver,vDriver处理这样的几个基本任务:一个是以SIRO-versioning的规则来保存数据,将最近一个版本的数据保存到数据page中,将其它版本的数据保存到另外的一个分离的地方。这里off-row的版本在系统crash or reboot之后是不会被新的事务访问的;还有一个任务是在合适时候回收一些版本的数据;另外一个任务是管理一个buffer layer,用于加速访问一些数据,类似于buffer pool的功能。在一般的数据page下面,最近的一个版本的数据保存到这里,更旧的版本会转移到另外的地方。为了加速旧版本数据的访问,下面的一个是一个verion buffering layer,
Our version buffer layer is to serve reads with in-memory versions without being delayed by the modifications of vBuffer or LLB due to version insertions or deletions. For example, when versions are coming in and out, shared data structures change accordingly. Modifying such data structures while allowing concurrent transactions to access,
根据前面的理论访问,的出dead zone中的版本在实际中是比较麻烦的,开销也可能比较大。为了解决这个问题,这里使用了分类的思路,将就版本分为几种不同的类型,方便在合适的时候一起地处理一批的数据。整个数据回收发生在几个地方,一个是数据从数据pages转移到offet row version space中的时候。这里的回收的方式为 dead zone-based version pruning,这一部分在vBuffer中。这里没有回收的数据进入下面的流程,没有回收的会根据这里的分类器来保存到不同的segment,在vDriver要将一个segment的数据刷到磁盘上面的时候,会在进行一次回收操作,这个称之为zone-based segment pruning,也就是说这里的操作是批量处理的。经过这些回收操作还有不能回收的,会被写入到磁盘上面,最后被segment cleaning机制来回收。
vSorter
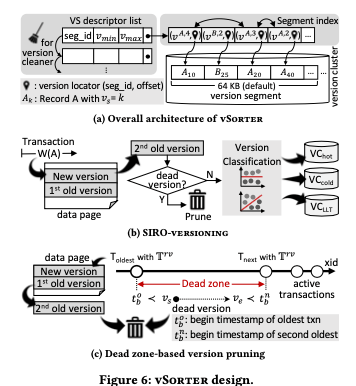
vSorter是vDriver的一个子组件,用于处理数据应该放到哪里的问题。基本的设计如下图。vSorter会处理一些数据的删除操作,另外对于需要保存的数据将其分为三种类型,称之为 version cluster。一个 version cluster的数据被保存为多个的segment。Version segments被创建的时候,先保存在内存中,由version buffer ing layer,即vBuffer来管理。在Version segments上面会构建一个segment index,由于加速查找。Segment实际上就是一个(version, locator, llink, rlink)四元组的数组。Version就是版本信息,locator记录在version segment上面的位置。而llink,rlink就是类似于双链表的指针,指向前一个和后一个版本索引在segment index中的位置,从而组成一个version chain。为了处理versio cleaning的工作,另外一个 VS descriptor的结构记录了segment的一些信息,比如seg id,最小和最大的版本,以及segment index的指针等。一个segment的版本都不会在访问时,就可以回收这个segment。
- 在一个事务更新一条记录的时候,如果这条记录已经保存了1st old version的时候。如下图所示。之前的1st old version就会变为2nd old version。在进行version分类前,会先判断其是否可以回收。如果可以回收则尽早地回收。能不能回收根据前面的dead zone理论来判断。对于date page的数据,使用一个toggle bit来标记哪一个是current record。如果2nd old version不能马上回收,分类的时候主要考量这样的一些因素:这个版本的一个是start和end tiemstamp,是否属于某个LLT,即长事务的clear sign of indicating。目前是分为了三种类型, (i) hot versions (VC-hot), (ii) cold versions (VC-cold), and (iii) versions belonging to the snapshots of LLTs (VC-llt )。
- 实际的系统中,精确地定位dead zone也是会比较麻烦,开销也比较大的。这里实现的时候对定位dead zone和在定位dead zone开销上面做了一个trade off。使用的是一种best-effort的策略,MySQL和PG都使用了某种数据结构来记录运行中的事务,所以得出dead zones是可能的。但是如果非常频繁的去更新这些信息,比如每次有事务启动 or 结束的时候更新,带来的开销是比较大的。这里使用的策略是周期性更新的策略。
- 版本分类的目的是方便批量地处理有类似性质的数据。在经过了第一次的dead version判断存活下来的版本会进行分类处理。首先判断是否为VC-llt类型,这种类型定义为至少可以被一个长事务snapshot read。长事务这里定义为其开始时间戳早于目前一个阈值。如果不是VC-llt类型,再去判断是VC-hot还是VC-cold,VC-hot的是有比较短的更新interval的,VC-cold则是更新interval比较长的。Hot会cold也是通过一个阈值来定义的,阈值为这个版本的结束时间和开始/创建时间戳的差值。
vCutter
vCutter就是处理segment的回收的问题,segment chain中可以回收的部分从这个chain中cut掉,回收空间。前面的结构描述提到了这里操作使用了 VS descriptor,记录下一个segment的一些元数据信息。如果[V-min ,V-max ] 在单个的dead zone中,就表明这个segment是可以回收的。这里实际上就是一种批量处理的方式,优点是回收操作的效率更高,缺点是一些数据可能不能及时回收。不过,Paper中认为,这些版本的数据回收不是非常紧急的任务,而且数据最终还是会被回收的。回收操作的基本示意如下图中的2,这个操作会在version chain中形成空洞/hole,不过即使存在这些空洞/hole,一个版本的数据还是可以访问的。只有一个hole的情况下,事务可能从version chain的head开始访问数据,也可以从tail开始。但是如果存在多个的hole,则可能造成一部分数据无法被访问到。为了解决这个问题,有避免总是维护完整的version chian,即没有hole的version chain带来的开销,这里给version chain加上了状态, 其可以在0-hole和1-hole中进行转化。cut操作也分为两种,Cut-I操作会cut一个 or多个连续的segment,最多造成一个hole,这种是非常更加频繁的操作,开销更低。而第二种Cut-II,可能造成多个的hole,这种情况下需要Fix-up的操作,即需要讲存在hole的version chian重新前后连接起来。
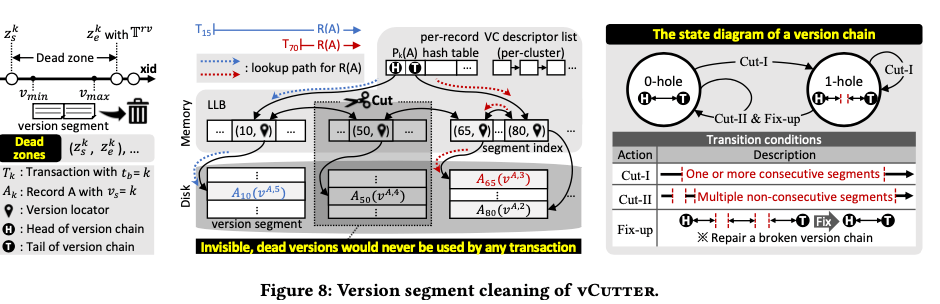
另外在这种模式下面,会在数据Page中保存一条记录的最近两个版本,所以recovery在这里处理就是修改一些toggles bit来使得1st old version重新变为当前的版本。undo recovery的操作对于vDriver的数据处理根据不同的情况有不同的处理方式,如果是已经完成且是abort掉的事务,就是回滚之前的改动toggles bit的操作,不会影响到version segments and LLB。而如果是crash导致没有完成的事务,version segments中的数据都会变成过期的,因为一定经历了一个没有活跃事务的时期,这样就可以直接将vDriver这里清空处理。
0x02 实际运用
Paper中还讨论了在MySQL和PostgreSQL中如何实现SIRO的思路,以证明这种思路的可行性。在处理就版本的方式上面,MySQL和PostgreSQL是两种不同的方式。在MySQL和PostgreSQL中实现SIRO的时候,主要的改动一个是如果改动physical page layout,实现SIRI的保存思路,另外一个就是如何管理off-row的数据。
-
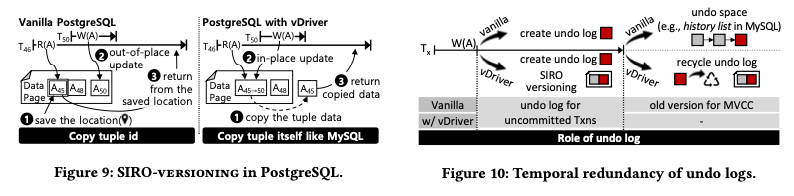
在PostgreSQL中实现的时候:PG使用的是in-row versioning with the out-of-place update的策略。这里要改变入下图所示,不在将所有版本的数据都保存在数据page中,而是先将之前的1st old version拷贝到保存旧版本数据的地方,然后写入新的数据,最后会将复制了的1st old version的位置返回。此外在PG实现还要另外保存旧版本数据的地方。
-
在MySQL中实现的时候:由于MySQL已经实现了undo log的空间来保存旧的数据,这里只要在undo log预留出空间即可。这里涉及到的一个问题就是数据看如果定位一个loser transaction。一种方式是在commit logs中检查事务的状态(e.g., ‘pg_xact’ in PostgreSQL and aborted transaction map in Azure SQL Database) ,另外的一种方式是扫描undo headers (e.g., ‘rollback segment’ in MySQL and Oracle)。前一方式实现vDriver简单一些,而后一方式就有一些麻烦,
The former type would have no difficulty in adopting vDriver, while the latter type must keep customized undo logs until transactions commit and then recycle logs since the undo log header should be used as an indicator for a loser until committed (see Figure 10.)MySQL在崩溃后的恢复active的事务利用到了undo log,所以相关的undo log需要保存到事务commit。在MySQL 上实现SIRO策略的时候,这里可能会造成在undo log和数据page中保存了一部分冗余的数据,因为SIRO的策略可能在page中保存两个版本,而MySQL更新记录的时候又会将之前的一些信息写到undo log中。但是这里认为这点冗余的影响不是很大。Paper中的下面的描述是???,eliminate the redundancy?,
Another issue is the deletion of ghost records in MySQL; stock MySQL removes ghosts when purging delete undo logs by using the tracking information. Since we eliminate the redundancy of MySQL’s undo space, we change the role of MySQL purging in that it fulfills the job of deleting ghosts and modifying the affected B-tree index in the background by scanning the entire user table, like PostgreSQL.
0x03 评估
这里的具体内容可以参看[1].
参考
- Long-lived Transactions Made Less Harmful, SIGMOD ‘20
