Taurus Database: How to be Fast, Available, and Frugal in the Cloud
0x00 基本架构
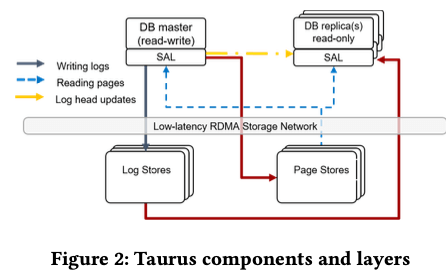
这篇是SIGMOD ‘20上面关于发表的关于分布式数据库的Paper,使用了今年来的分布式数据库的一种的经典架构。Taurus Database是一种类似于Aurora的架构,在一些地方进行了一些调整。总体的架构上面,前面的是Database front end,多使用改造之后的MySQL or PostgrSQL来实现,相当于一个计算层,一般都是一个主节点,若干的从节点。这里没有提到多主的内容。存储层分为LogStore和PageSroe。计算节点和存储节点沟通使用称之为Storage Abstraction Layer的Library。显然LogStore由于处理数据人日志的存取,而PageStore处理数据库Page的存取。LogStore在环境中作为集群来部署。
-
LogStore中一个写入Log的抽象称之为PLog,使用一个24byte的ID表示。在写入数据的时候,写入LogStore三个副本成功就相当于写入操作成功。如果写入失败,则会导致切换PLog的操作,选择集群中其它的节点来创建新的PLog再执行写入操作。PLog会设置有一个大小上面的限制。LogStore的读取操作主要来自两个地方,一个是读/从节点会从LogStore读取主最近写入LogStore的数据。所以为了加速读取,对于最近的数据LogStore会使用一个FIFO的方式来缓存。另外一个是数据库recovery的时候需要从中读取committed log records的数据。一个数据库对用的多个PLog的元数据信息被保存到另外一个PLog中,这些信息同时也会换成在数据库节点的内存中。
-
PageStore保存数据库的Page。主节点更新Page的时候,通过LSN来表示这个Page的版本。所以唯一表示一个Page使用其PageID+LSN。PageStore提供的API主要是下面几个,
(1) WriteLogs is used to ship a buffer with log records (2) ReadPage is used to read a specific version of a page (3) SetRecycleLSN is used to specify the oldest LSN of pages belonging to the same database that the front end might request (recycle LSN) (4) GetPersistentLSN returns the highest LSN that the Page Store can serve数据库在这里会被划分为Silces(Page Store servers are also located in the storage layer. Taurus database is divided into small fixed-size (10GB) sets of pages called slices. ),每个PageStore会保存来自多个数据的多个Silces。上面几个API对应的功能;1. WriteLogs用于写入日志,PageStore接受到日志之后,根据这些日志更新Page;2. ReadPage用于读取一个Page,需要传入LSN信息来制定读取的版本,根据LSN来保证此LSN之前的更新都已经引用到这个Page之上,这个LSN后面的更新不得引用到这次请求的Page版本上面;3. SetRecycleLSN用于告诉PageStore最来会使用的LSN,PageStore可以根据这个信息来回收不会再使用的Page;4. GetPersistentLSN获取PageStore已经处理的最新的LSN的信息。
-
Storage Abstraction Layer则是计算和存储沟通使用的一个Library。在SAL中保存的一个主要的信息是cluster visible (CV) LSN。
0x01 Replication and Recovery
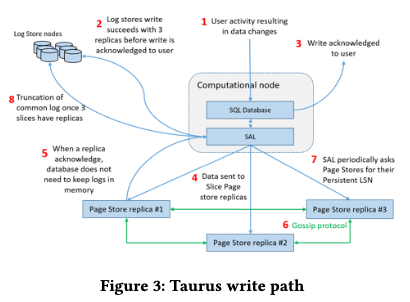
Taurus写入和读取路径和一般的MySQL/PostgreSQL改变比较大。其中写入路径比读取要复杂不少:接受到用户的写入请求的时候,数据产生的log records会通过SAL尝试写入三个副本。这里SAL将每个PLog的大小限制为64MB,在避免碎片化和load balance直接取得一个平衡。在写入了三个PLog副本的日志,这里就可以当作写入成功了,事务就可以执行提交操作。对于一个Page,其改动的相关的日志持久化之后,SAL会将其保存到一个write buffer,这个buffer对用到这个page所在的slice。
- 在buffer满了 or 设置的一个超时时间过了,SAL将buffer发送到保存了这个slice的Page Stores。每个buffer中会包含了slice ID以及序列号的信息,Page Store使用这些元数据信息来感知是否接受到了完整的数据。一个slice接受到的最大的LSN称之为flush LSN,保存了同一个slice的Page Store节点之间会使用gossip协议来交换其收到的改动的信息,可以发现没有正常收到的数据并尝试恢复。这里另外的一个设计是SAL写入数据到PageStore的时候,只会等待一个节点确认成功即可。这个设计会影响到后面的恢复逻辑。这样的设计Paper中总结为这样的几个优点:1. 对应小故障/临时故障容忍度高;2. 写入延迟更低;3. SAL需要处理的问题更少,消耗的资源就更少。这里有问题的情况下需要PageStore自己实现Re-sending log records的功能
- 现在的数据和存储设备之间处理数据的单位一般是Page,而计算节点处理数据之前需要将对应的pages读取到本机的buffer pool之中。Buffer pool满了的时候也会有一个page evict的逻辑。这里的一个逻辑上面的改动是,在一个dity page对应的改动写入到至少一个Page Store副本之前,这个page不能被evict。这样设计的考虑:“Thus, until the latest log record reaches a Page Store, the corresponding page is guaranteed to be available from the buffer pool. After that, the page can be read from a Page Store.”。主节点读取page的时候,就可以带上LSN的信息取读取,首先尝试选择其认为延迟最低的一个节点,在这个节点不可用 or 没有接受到最新更新的情况下,会再去读取其它的副本。
- 对于PageStore保存的每一个slice,会追踪其slice persistent LSN的信息。而SAL会追踪slice每个副本的 persistent LSN的信息。一个数据库的silces的副本中 persistent LSN最老的,称之为database persistent LSN,这个信息会被周期性的持久化。对于一个PLog保存的数据,如果其LSN都小于这个database persistent LSN,这个PLog就可以删除。
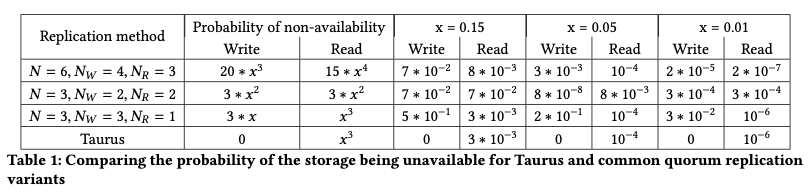
这种复制方式和Aurora的复制有写差别,Paper中也给出了一个表格来说明这种思路的优点。其中x表示单个节点故障的概率。
故障这里主要涉及到三个方面,对应到前面的三个主要的部分,即PageStore,LogStore和计算节点。其中LogStore恢复的处理这里是描述得比较简单的:对于单个节点的不可用,使用选择新节点创建新的PLog来解决,这个和现在的一些类似的分布式存储项目采用的方式类似。对于完全不可用的情况下,所有的PLogs都会停止写入操作,数据库成为read only的状态。PageStore的处理这里是描述的最多的。Paper中描述了几种case来说明其PageStore恢复的逻辑:
-
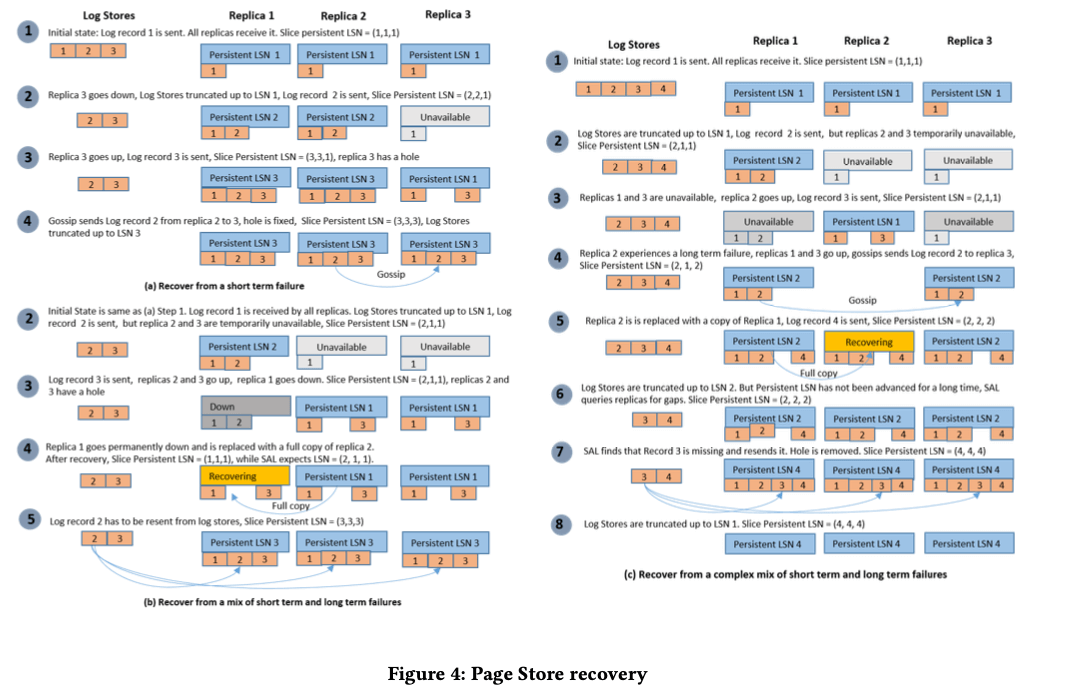
对于一个节点短时间不可用的情况,如下图的a,这个故障节点恢复之后,会通过grossip协议获知其确实的LSN,并从其它的节点补全数据。节点起来之后就会接受新的写入,这个时候可能之前缺失写入的部分还没有补全,造成“空洞”。对于长时间的不可用,直接起一个新的节点来替代,这个新的节点也是在起来之后就能处理写入,缺失的不同同时从其它的节点中获取;
-
对于一些更加复杂的例子,比如b为短时间故障和长时间故障一起发生的情况。2、3节点短时间不可用之后,马上恢复。这个时候1节点有变得完全不可用。这个时候存活的节点都存在缺失的数据,而且log的一部分已经被删除了。1节点恢复/新的1节点起来之后,会使用从其它节点copy数据来“追赶”。这个时候还是会存在所有的节点都有缺失的数据。所有只能从LogStore中恢复。
-
在PageStore推进persistent LSN需要接受到完整的这个部分的日志。为了解决结束到的日志有空洞时候的一些问题,这里SAL会周期性地询问slice副本persistent LSN的信息。如果发现这个persistent LSN比flush LSN要小,SAL则回去获取PageStore节点没有接受到的log recrods的信息。如果SAL发现所有的PageStore的副本缺失一个信息,比如图c中6的情况,SAL会从LogStore中读取缺失的数据并重新发送到PageStore。
-
计算节点的恢复包含SAL的恢复和database front的恢复。SAL恢复操作在前面,其先读取database persistent LSN的信息,然后从这个点开始恢复操作,所有的slice副本都不包含的记录会被重新发送到PageStore。这一部分类似redo,redo的部分完成之后才能接受新的请求,
Only log records that are missing from all slice replicas are sent again to the corresponding slices. Some log records may be resent even though some Page Stores contain them, but this is safe as Page Stores disregard log records that they have already received. This step is equivalent to the redo phase in traditional database recovery.
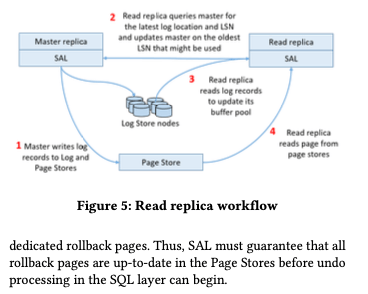
0x02 只读节点
只读节点读取数据也要先将数据读取到buffer pool。在架构下面,读节点需要从写节点来获取最新的log的位置,之前取LogStore中读取对应的日志记录,来更新buffer pool的page。Page也可能会从PageStore直接读取。这里的设计Paper中提到另外的一种可能方式,即直接由写节点将日志发送到读节点,但是这样的一个确定是写节点会发送大量的数据,在读副本比较多的时候有一个明显的放大。而这里只是告诉读节点的一些元数据信息,数据量会小很多。另外这里要解决的一个问题就是读节点对于数据库的consistent view的问题,涉及到几个方面,
- Physical consistency,即对数据看内部节点的consistent view。比如Btree的结构,一个改动可能涉及到多个pages的变化,一个操作的现场需要看到一个操作所有的改动,就好似这个操作为原子完成的一样。在一个节点上面的数据可以通过锁来解决,在多个节点的时候这种方式的开销会太大了。这里使用的方式是写节点group的方式写入log,设置为这个group boundary的为一个consistent point。读节点重放log的时候,也是以group来重放。最近重放的一个log group的最后一个LSN称之为replica visible LSN。这个replica visible LSN总是一个group boundary,以此保持一个physically consistent的database view。
- 读节点从LogStore读取log,识别其中的group boundary,重放log group,推进replica visible LSN。这里还要注意另外的一个问题:只是这样操作的话replica visible LSN可能早于一个slice的slice persistent LSN,而这里设置为避免这种情况下,这样来避免PageStore无法响应一个读节点的read page requests。对于一个读事务,当前节点的replica visible LSN称之为transaction visible LSN (TV-LSN)。事务运行的时候节点会进行推进这个replica visible LSN,所以TV-LSN可能对于replica visible LSN是落后的。读节点会追踪最小的TV-LSN的信息,并将这些信息发送到主节点,主节点得到这些信息之后,选择其中一个最小的发送到PageStore,作为一个新的 recycle LSN。这里要去在new recycle LSN之后的page的任意version,PageStore都可以提供。这里面向的是OLTP,所以这个recycle LSN推进一般都比较快,方便尽快是否PageStore的一些资源。
- 另外一个就是logical consistency。目前的数据看一般都使用MVCC的并发控制方式,提交的时候会写入一个commit log记录到log中。读节点在读取到commit log的时候,以此来更新其active transaction list。读节点上面的读事务启动的时候,记录下active 和 committed transaction list,这些信息决定了这个事务对于数据库的logical view。
0x03 Page Store
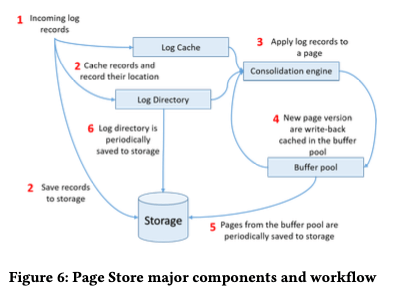
这里对于PageStore有这样的一些设计考量;1. 每个PageStore节点单独地执行log consolidation操作,避免和其它节点同步带来的开销;2. 以append-only的方式写入数据;3. consolidation操作需要base page和若干的log记录,这些数据都会先cache到内存中。PageStore这里践行了”the log is the database”的思路。这样对于一个page,想要找打创建一个version的page需要的所有的log记录。解决这个问题这里引入的一个结构是Log Directory,对于每个silce会有一个Log Directory( It keeps track of the location of all log records and the versions of the pages, hosted by the slice, i.e.,),实现为一个lock-tree的hash table。其中key为page ID。当consolidation不能追上log写入的速度的时候,这个table会一直增大。为了避免这个table增长太大,需要在一定时候向主节点发送限流的一些信息。
-
PageStore基本的操作流程: Page以group方式接受到log记录,称之为log fragments,这些数据会被立即写入磁盘,同时会cache到内存的LogCache,相关的一些location信息添加到Log Directory中。Consolidation操作访问Log Directory,获取page和其相关的log记录,重日志产生新version的page。这些page会被添加到PageStore的Buffer Pool中,
The buffer pool functions as a write-back cache, asynchronously flushing dirty pages to the slice log (step 6) allowing it to apply multiple log records before writing a page to disk, further reducing the amount of I/O. Once a new page version is flushed, the Log Directory is updated to point to the new location.PageStore的Buffer Pool,作为前端数据库节点的second-level cache。这个Buffer Pool的主要作用还是用于加速consolidation操作。在测试中发现LFU比LRU有更好的缓冲命中率。
-
Consolidation操作的时候,选择哪些Page也是一个问题。这里开始选择的方式是选择the longest chain first。但是这种方式对hot pages有太高的优先级。对于更多的cold pages,造成太多的unconsolidated cold pages。优化之后的策略称之为”log cache-centric”,consolidation操作哪一个page由其相关的log记录到达Page的顺序决定。Log cahce满了的情况下,数据只是刷入磁盘,等后面的处理。后面处理的时候还是得需要load到log cache中。
0x04 评估
这里的具体信息可以参看[1].
参考
- Taurus Database: How to be Fast, Available, and Frugal in the Cloud, SIGMOD ‘20.
- CockroachDB: The Resilient Geo-Distributed SQL Database, SIGMOD ‘20.
