SplinterDB: Closing the Bandwidth Gap for NVMe Key-Value Stores
0x00 基本设计
SplinterDB提出的是一种新的微NVMe优化的数据结构,这个结构称之为STBε-tree。其整体的结构如下,STBε-tree本质上是一个tree的tree,主体称之为 trunk tree,trunk tree的元素为指向B-tree,称之为branch trees。branch trees保存实际的Key-Value Pair。每个branch还有有一个对应的quotient filter, 这个quotient filter的功能类似于LSM-tree中的Bloom Filter。STBε-tree也会有一个Memtable,有点像LSM-tree,Memtable这里实现为一个B-tree。对于一个chuck node指向的一些B-tree,是从旧到新排列的,也就是说,branch i对于的B-tree里面的数据,都添加在i+1的branch之前。另外,在chunk node的一项中,有一个整数a-c,表示对于其一个子节点来水这个branch处于active状态,其它的是inactive状态。这个和STBε-tree的flushing特性相关。STBε-tree的一些基本操作,
- Query,查询的时候,首先在Memtable中查找,找打就返回。否则继续向下查找,在一个chunk node t查找的时候,先通过pivots找到这个key应该在那个子节点c中,然后在c中从新到旧查找这个key,找到就返回。一个branch中查询的时候,先试查询quotient filter,存在的情况下才实际地在B-tree中进行查找操作。在这种结构中scan操作的时候,需要构建多个B-tree上面的iterator来完成scan操作。
- Insert,添加操作的时候,先添加到Memtable中。在Memtable满了的情况下,Memtable作为一个新的branch统计到root chunk node的branch集合中,作为一个最新的。这个操作称之为incorporation。这个Memtable的大小在这里设置为24MB。删除操作和LSM-tree一样,也是添加一个tombstone记录的方式。
- Flushing and Compaction,随着Memtable的不断的incorporation操作,root chunk node的branch会变得越来越多。这里引入了Flushing和Compaction操作来处理这个node size增长带来的问题。一个简单的方法是一个trunk node满了的时候,compacting这个node的branchs到一个branch,然后flushing到子节点中。这样的操作可能需要递归操作。STBε-tree会给trunk node设置一个大小的上限。Leaf node满了之后,就需要split操作来分裂leaf node。
- 一个trunk node p如果被认为是full的(这里的判断依据是其branchs占的总bytes数达到一个阈值)。compacting的时候,这里会创建一个新的branch b,然后选择p的子节点中active key-value pairs最多的c,将p所有branch的c子节点添加到brach b中,然后将这个branch flushing到c。这个过程中还会为b创建一个quotient filter。最后,对于c子节点,p的节点都会被标记为inactive。这样操作的原因是来记录p节点中c子节点的数据都已经被flushing到c中去了,要查找的话去c中查找。但是除了flushing到c中的之前,p还是有其它的子节点的。
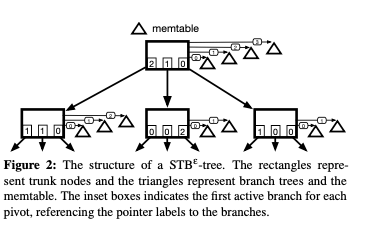
STBε-tree的结构有点类似于一个Tier leveling的LSM-tree,SST文件做出一个B-tree,这样的好处之一就是Compaction的时候,可以优化一些merge操作。在具体实现方面,Paper中还有更详细的描述。
0x02 评估
这里的具体信息可以参看[1].
Tucana: Design and implementation of a fast and efficient scale-up key-value store
0x10 基本设计
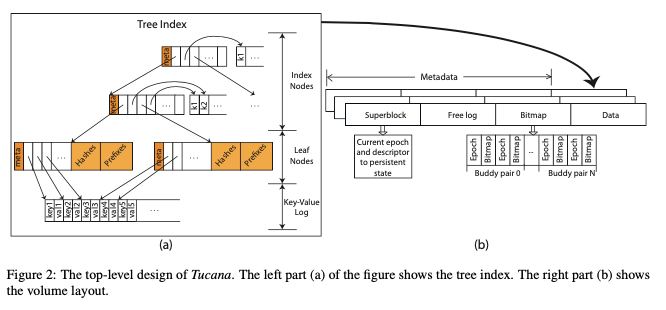
这篇Paper提出的结构称之为Tucana,和Bε-tree有很多相似的地方,其基本的结构如下。Tucana的设计会将index部分的结构放到内存/NVM中,而实际的数据部分放到磁盘上面。和LSM-tree相比,Tucana会有更多的小IO请求,但是不会有Tucana不需要LSM-tree的Compaction操作。Tucana的index结构部分中,interval有指向下一层结点的internal node和指向变长key的的部分。对于interval节点,Tucana使用分离的一个区域来保存keys的数据。指向key的pointer为根据key的顺序排序,而保存keys的buffer是append方式添加的。Bε-tree中,内部节点也会buffer一部分最近的写入key-value数据,没有分离保存。Tucana的leaf结点保存的是根据key排序的key pointer,key-value pair数据使用append的方式写入到log中。在Tucana中的一些基本操作方式如下,
- Query,先在interval node中使用二分的方式来查找找到下一层的位置,如此递归。到leaf node时,使用二分找到key-value pair在log中的位置,取回接口。Inert,添加操作和Query操作类似,找到leaf node时候,将key-value pair数据append到log中,然后将这个消息添加到leaf node,保持leaf node中的pointer根据key有序。这样,和Bε-tree,Tucana中不会在interval node中buffer一些数据。在查找的时候,会额外保存一些元数据来,比如保存了一个hash值,由于加速点查询。在leaf node满了之后,需要执行split操作。这个和一般的tree结构split没有很大的部分。对于删除操作,则这里是在log中添加一个tombstone记录。
- Tucana的数据部署如下图b,使用使用同感的segment来保存数据,一个segment在空间上面是连续的。每个segment可以由若干的block组成。segment主要是两个部分,元数据部分和数据部分,使用bitmap的方式来管理segment的空闲空间。segment使用基于mmap的方式来访问。bitmap在segment中阻止为buddy pairs,有2个4K的block组成。每个block会有一个记录epoch的字段。这样实际上实现了一个类似CoW的效果,提交更新的时候写入一份新的,恢复操作的时候选择数据完整的epoch最大的一个。
- 空间的释放使用lazy的方式,利用了segment之间的free log部分。因为执行free操作,free在中间crash的一些情况处理起来比较麻烦。Tucana在free log中记录free操作(using their epoch id),在这个epoch的一些信息吹就话之后在执行free操作。
0x11 评估
这里的具体信息可以参看[2].
参考
- SplinterDB: Closing the Bandwidth Gap for NVMe Key-Value Stores, ATC’ 20.
- Tucana: Design and implementation of a fast and efficient scale-up key-value store, ATC ‘16.
