Zero Downtime Release: Disruption-free Load Balancing of a Multi-Billion User Website
0x00 基本内容
这篇Paper是Facebook的关于LB的一篇Paper,这篇Paper的主要内容比较有意思:主要是关于如何实现LB的Disruption-free,即可以实现在LB升级的时候也可以不影响到Load Balancing的操作。在FB的系统中,LB在系统中的部署模式如下图,整体是两个部分,Edge PoP和Data Center,两个部分都是一层的L4和一层的L7。L4一层是FB使用最近的Linux内核的一个技术XDP实现了,不知道这个新技术实际部署的比例。另外的L7是FB最近开发的一个库。总体来说。
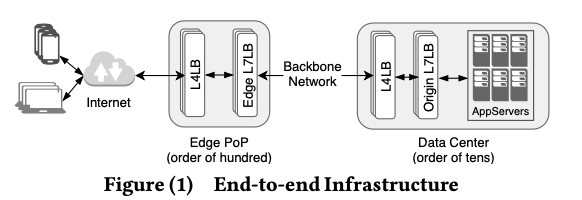
一个请求的在这个系统中的生命周期如下:1. Edge PoP服务器作为一个类似网关的角色。这里一般是TCP,这个连接的一方是Edge L7LB;2. Edge Proxygen处理用户请求,如果是可以直接处理的, 使用Direct Server Return来直接返回结构给客户端,如果不能则转发到上游的Origin DataCenter;3. Edge 和 Origin会保持一个HTTP2的长连接和MQTT连接,用于传输用户的请求;4. Origin Proxygen负责将请求转发到App. Server(based on the request’s context (e.g., web requests to HHVM, django servers while persistent pub/sub connections to their respective MQTT broker back-ends).);这里讨论的主要是L7层面的一些设计。 这些组件升级的时候,可能带来一些问题。这里提出了减少升级带来影响的一些理想的方法。比如;
-
Language Support (Option-1),编程语言本身支持 headless updates,比如Erlang。但是一般的语言不支持。所以这个方法实用性不高;
-
Kernel Support(Option-2),另外一个方法是使用kernel的特性。比如Kernel的一些转移连接的功能,比如SO_REUSEPORT。但是也有些缺点:
* First, kernel techniques like SO_REUSEPORT do not ensure consistent routing of packets. During such migration of a socket, there is a temporary moment before the old process relinquishes the control over it when both processes will have control over the socket and packets arriving at it. * While temporary, such ambiguous moments can have a significant impact at our scale.另外一种方式是使用 CMSG, SCM_RIGHTS 加 dup()组合而来的方式,也有限于UDP的限制。另外这些功能在一个实例处理成千上万连接的时候依然会有问题。除了这些缺点之外,还有的问题是对于长连接,可能需要等待很长的时间来使得原来的连接结束工作,另外就是SO_REUSEPORT这样的不能传输app相关的状态信息。
-
Protocol and Kernel Support (Option-3)。第三种方式是协议上面的支持,这种方式是通过在进场之间migrating listening sockets,原来的进程不会接受新的连接,这样可以优雅地退出。还可以通知上游的服务来帮助优雅退出。这种方式的缺点是一些协议不支持,比如 HTTP/1.1 和 MQTT,HTTP2的GoAways功能倒是可以支持。
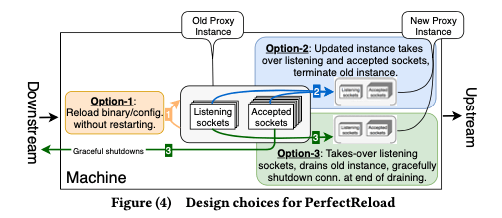
0x01 基本设计
这里提出的方式称之为Zero Downtime Release,本质上是从第三种方式优化而来的方式。通过引入几种更新机制来解决现在的问题:Socket Takeover,Downstream Connection Reuse和Partial Post Replay:
-
Socket Takeover,这个是实现Zero Downtime Restarts的主要机制。这种策略会将 listening socket交接给新的进程。然后旧进程不在监听,也就不会有新连接,以支持优雅退出。这个通过Linux Kernel的几个功能实现。通过sendmsg和recvmsg的syscall,使用其CMSG、SCM_RIGHTS的功能来实现将旧进程的all active listening sockets传输到另外一个进程,接受会通过dup来复制FDs。这个概念的缺点是只支持TCP。为了支持UDP,这里通过Linux Kernel的SO_REUSEPORT功能,来使用多个server threads来处理UDP包,对于使用进程变动导致hash UDP包导致的mis-routing问题,通过移交all UDP VIP sockets来解决。这里还有的问题是对于UDP上层的协议的连接,比如QUIC,一些信息会丢失,比如还在运行的旧进程的QUIC连接。这个问题的处理方式是使用用户空间的一个router方式,通过pre-configured host local addresses将packet路由到旧进程。这个路由可以通过QUIC中的connection ID来实现。基本的操作流程如下,
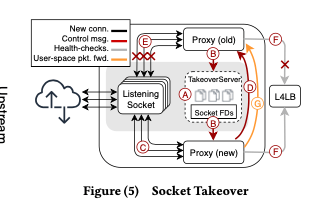
Edge 和 Origin之间的连接是通过HTTP2,这里通过HTTP/2的GOAWAY机制来处理。实现优雅退出,
Proxygen in Edge and Origin maintain long-lived HTTP/2 connections between them. Leveraging GOAWAY , they are gracefully terminated over the draining period and the two establish new connections to tunnel user connections and requests without end-user disruption. -
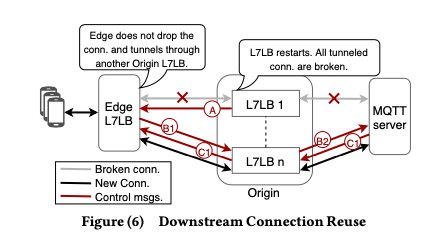
Downstream Connection Reuse。FB中MQTT协议来和Billion级别的用户维持长连接,但是由于MQTT缺乏GOAWAY类似的特性,这里需要解决这个问题。MQTT的一个特性不care那个LB回复的packets,这里只要Edge的L7 LB通过另外Origin L7 LB重新连接MQTT server,用户是不知道的,所以这里这样处理就这个问题,
... it does not matter which Proxygen relayed the packets. MQTT connections are tunneled through Edge to Origin to MQTT back-ends over HTTP/2. Any restarts at Origin are transparent to the end-users as their connections with the Edge remains undisturbed. If we can reconnect Edge Proxygen and MQTT servers through another Origin Proxygen, while the instance in question is restarting, end users do not need to reconnect at all.这样看起来Orgin L7 LB就是stateless的。对于用户来说,每个用一个唯一的ID,使用这个ID来通过Consistent hashing的方式路由请求到MQTT Server,就可以避免用户和server之间的连接中断。处理的流程如下图:Orgin L7 LB重启的时候,它发送一个reconnect_solicitation信息给Edge L7LB,来通知其即将重启,之后就断开连接。然后Edge L7LB发送re_connect给Orgin,另外的一台正常运行的Orgin L7 LB转发这个请求到对应的backend。Backend通过消息中的user id消息来获取和这个用户的连接。如果这个连接存在的话,回复connect_ack信息,否则回复connect_refuse信息。这个时候Edge需要drop连接,执行重新连接的操作。这个是讨论了Orgin LB的重启,对于Edge通用的方式也是适用的。
-
Partial Post Replay,App. Server的重启会导致进行中的一些请求失败,特别是长请求更加容易收到影响。重启的时候,App. Server 可以执行,1. 返回500;2. 返回307,Temporary Redirect,引导用户重新请求;3. 307请求可以由 Origin L7LB处理,避免将这个透传到用户。不过这种方式需要 Origin L7LB buffer起来用户请求的数据,这样会导致 Origin L7LB消耗资源增大很多。这里提出的方式是Partial Post Replay ,基本的思路如下图:对应要重启的接受到用户请求的App. Server,返回一个379的状态码,表示Partial POST Replay,并会带有收到的部分数据。Origin L7LB收到之后,会将着部分数据带上请求其它的App. Server。
三种机制的适用性有所不同。上面的用户请求到backend被处理的基本架构图中,App. Server重启是最频繁的。App. Server更适合用的Partial Post Replay,而不是Sockets Tabkeover。Sockets Tabkeover, Downstream Connection Reuse 被两层的L7 LB使用。在Edge L7 LB使用的时候,需要app能过处理 connection-reuse的逻辑。
0x02 Hands-on Experience
这部分总结了实际操作过程中的遇到的一些问题,以及其处理的一些方式,
- Downsides of sharing existing sockets。Sockets takeover的机制也可能有一些问题,一个是在发布新版本的L7 LB的时候,如果新版本存在问题,需要回滚操作的时候,会有一些麻烦。比如Paper就描述了其遇到过的在kernel在UDP write path上的一个Bug,可能导致sk_buff的泄露。另外的就是新旧经常交接的时候,需要新进程处理好socket listening和关闭fd不落。比如使用SO_REUSEPORT来监听的时候,如果在错误忽略了某个的received FD,关闭操作or监听操作没有正确进行,旧会导致一些orphaned sockets的问题。会导致用户遇到了错误越来越多。这里的一些处理措施是使用一些可以动态地关闭Socket Takeover的功能,比如交接不正常的时候选择打开新监听的方式而不是take over。在交接有问题的情况下通知L4 LB,来避免将流量发送到这条可能有问题的机器。
- Premature termination of existing process,在新进程起来进入正常运行的状态之后,旧进程才能退出,这个过程需要一段时间。这个过程中需要旧进程正常服务,而不是提前退出。这里处理的方式是在新旧进程中实现一个消息机制,旧进程在显式都到确认消息之后才退出。
- Backwardcompatibility,SocketTakeover的机制可能在变化,这里必须要一个版本的SocketTakeover机制兼容上一个版本的SocketTakeover机制。
- Availability risks and health-checks,升级这里可能导致短时间的一个监控指标不正常,比如内存压力突然增大。可能会带纸健康检查误认为故障,继而导致L4 LB路由packets改变路由。为了处理这个问题,这个会在L4 LB中使用一个connection table cache来记录最近的一些flows的消息,保持这个连接路由到一致的目的server。
另外的关于Partial Post Replay的一些处理。比如需要在操作的过程中保持HTTP的语义,比如HTTP2/HTTP3的request pseudo-headers问题,具体这里好像没说。这个应该和HTTP2/HTTP3协议的特点相关。另外一个是 HTTP/1.1加 chunked transfer encoding的问题,L7 LB需要处理这个chunk的一些消息。另外一个就是一些合法性检查的问题。
0x02 评估
这里的具体信息可以参看[1].
参考
- Zero Downtime Release: Disruption-free Load Balancing of a Multi-Billion User Website, SIGCOMM ‘20.
- A High-Speed Load-Balancer Design with Guaranteed Per-Connection-Consistency, NSDI ‘20.
