Concurrent Updates to Pages with Fixed-Size Rows Using Lock-Free Algorithms
0x00 基本内容
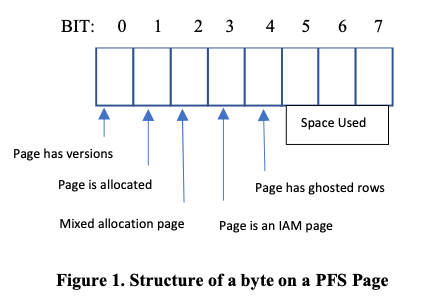
这篇Paper讨论的是SQL Server中一个具体的优化。SQL Server中使用PageFreeSpace (PFS) 的结构来管理空闲的存储空间,每个PFS Page管理64MB大小的chunk,一般情况下更新FPS的信息要加上写类型的锁,这里可以优化为Lock-Free的方式。Paper中的例子都是以FPS的更新为例子说明这里的算法,但是可以推广到其他的使用Fixed-Size Rows的Page更新中。SQL Sever中PFS的基本结构如下,SQL Sever使用8KB大小的Page,每个PFS Page前面的几个bit是标志位,后面为记录chunk使用前面的部分,所有这里可以标记8088个page的使用情况。可以看到对应page的标记是固定的,且更新其中的一个不会干涉到另外的一个,这个为这个算法提供了一定的基础。除此之外,SQL Sever使用Index Allocation Map (IAM) Page来记录4GB大小的extent,这个extent为一个allocatation的单元,使用Global Allocation Map (GAM) Page记录依据allocated的extent的情况。
SQL Server是使用ARIES风格的WAL,会周期性地scan buffer pool将dirty page写入到磁盘上面,以及其它的一些操作,来完成checkpoint。SQL Sevrer使用DirtyPageManager管理一个数据库中的dirty page,将它们保存到两个list中,一个list保存是准备更新,后面会变长dirty的,另外一个是记录依据变长dirty的。这里的两个list估计和获取到锁之后,开始写日志到写日志完成的时间过程中使用的。Dirty Page Context(DPC)用来记录一个buffer中 checkpoint ID,也记录buffer中的为dirty状态的第一个 LSN,即用于确定一个checkpoint中最老的page。目前PFS更新的时候,会使用独占类型的latch来保存更新的互斥。在更新一个PFS Page的时候,如果这个信息已经在DPC中存在了,则不用管,否则可能需要记录为最小的LSN。
Void UpdatePage()
{
Latch the data page exclusively.
{
Compute the necessary PFS update;
If the transaction is in rollback, update the PFS page;
Generate log record for the data page;
Update the data page;
If the transaction is not in rollback, update PFS page;
}
Release the latch on the data page;
}
//
Void UpdatePFSPage()
{
Obtain PFS page corresponding to the data page;
Update latch the PFS page;
{
Prepare the PFS page to be dirtied;
Generate log record for the PFS update;
Update the byte on PFS page;
Set LSN on PFS page;
Mark PFS buffer as dirty;
}
Release the latch on the PFS page;
}
0x01 基本算法
这里的优化是将更新PFS Page的时候获取的独占类型的latch改成share latch。主要的改动是获取page的latch的时候变成了share类型的latch,另外更新对应位置的信息和LSN的时候使用interlock的方式。这样需要其它方面的一些改动才能保证正确性。一个是Buffer Pool的管理,为了支持concurrent updates scheme的方式,和之前的方式不同,这里BufferManagement会区分不同的page类型,可以使用这种方式更新的page会有一个BUF_CAN_HAVE_SHARED_UPDATES来标记。另外DirtyPageContext(DPC)一些操作不是线程安全的,这里改用interlocked compare and exchange的操作另外实现。
Void UpdatePFSPageUsingSHLatch()
{
Obtain PFS page corresponding to the data page;
Share latch the PFS Page;
{
Prepare the PFS buffer to be dirtied;
Generate log record for the PFS update;
Update byte on PFS page using interlocked operations;
Set LSNon PFS page header using interlocked operations;
Mark PFS buffer as dirty;
}
Release the latch on the PFS page;
}
另外的一个是日志和LSN相关的。在ARIES风格的WAL中,一个log record会记录和这个log record相关的前一个log record的LSN,称之为previous LSN。Recovery操作的时候,如果这个previous有问题,则会造成恢复失败。在concurrent updates的模式下面,可能存在多个log record的previous LSN是同一个的情况,在原始的ARIES风格的WAL中这种情况会被assert掉。concurrent updates的模式下面其实这种情况是可以的,也可以保证正确性,所以这里要放松这种模式下面的previous检查。在concurrent updates的模式下面,更新Page的LSN信息的时候,需要使用原子的方式,SQL Server中的LSN不是一个8byte的字段,不能直接使用原子指令。这里获取Page LSN的时候使用的原子指令实现的,但是更新的时候需要获取一个latch。
struct LSN
{
ULONG m_fSeqNo;
ULONG m_blockOffset;
USHORT m_slotId;
}
//
Void SetPFSPageLsn(LSN targetLSN)
{
Get the current LSN value on the page;
If the current LSN > targetLSN
{
return;
}
Else
{
Obtain the lock on m_slotId using interlocked operations;
{
Get the current LSN value on the page;
If Current LSN on page < targetLSN
{
Update the LSN value on the page;
}
}
Release the lock on the m_slotId;
}
}
//
LSN GetPFSPageLsn()
{
do
{
read1 = Atomic read of first 8 bytes of LSN;
read_s1 =Atomic read of last 2 bytes of LSN;
Memory barrier to prevent compiler reordering;
read2= Atomic read of first 8 bytes of LSN;
read_s2 = Atomic read of last 2 bytes of LSN;
} while (read1 != read2 || read_s1 != read_s2 ||
SLOT_MASK_set_in_read_s1 ||
SLOT_MASK_set_in_read_s2);
Double read succeeded, return the value;
}
另外一个需要改动的地方是checkpoint相关的,concurrent updates的模式下面,可能线程t1产生了一个更小的LSN的日志,t2产生了一个LSN更大的日志,t2却赶在t1之前更新了DPC的信息。这个时候checkpoint操作去查看最小的dirty page LSN的时候,可能获取到一个比实际的更大的值,从而导致错误。这里使用一个PENDING_COUNT的方式解决这个问题。checkpoint操作只有在这个PENDING_COUNT为0的时候才能继续后面的操作,否则需要等待这个PENDING_COUNT变成0。更新Page操作的时候,t1准备生成log record的时候,如果dirty bit为0,则编码目前还没有其它的更新操作。如果t1的操作对DPC中记录的LSN值有影响,则t1递增PENDING_COUNT的值。这个时候如果t2准备产生log record,dirty bit发现此时的值为1,而t2对PENDING_COUNT不用操作。
Void PrepareToDirty()
{
If the page does not already have DPC, create one;
Increment PENDING_COUNT in DPC in interlocked way;
Other prepare to dirty aspects;
}
Void Dirty()
{
Perform other Dirty tracking;
Set the Dirty bit;
Decrement PENDING_COUNT on DPC if needed;
}
0x02 评估
这里的具体信息可以参看[1].
Segment-Based Recovery: Write-ahead logging revisited
0x10 基本思路
WAL是现在的数据库系统基本都会采用的系统,一般的关系型数据库使用Btree作为索引结构,以page为管理单位。这篇Paper提出来了segment-based recovery的思路,提出以segment为管理单位,并支持segment和page的管理方式同时存在。Segment在这里就是一段存储的空间,即a set of bytes that may span page boundaries,recovery操作的时候以segment为单位,而不是page。一个segment可以是有多个page组成。这里segment的一个优势是对于大对象来说,可以保存在一个segment,和page为单位管理的系统那样使用多个page来保存,另外就是能更好利用DMA 和 zero-copy IO。在ARIES风格的WAL中,每个page会有一个LSN,记录应用到这个page上面的Log的位置,而这里的Segment-Based Recovery的一个特点就是不需要每个page一个LSN。而对于Segment-Based Recovery,其redo记录的限制与blind writes,即写入一个segment数据的时候不用care这个segment的内容,和一般基于page的需要理解这个page的结构的方式不同。一般的数据库,比如MySQL,使用redo log为 physiological redo,这个physiological是physical和logical的合成次,即即有physical也有logical的log。对于page-oriented的recovery机制,paper中总结了这样的一些问题:
-
Multi-page Objects,需要使用多个pages的大对象的处理。这个在page-oriented的方式中处理比较麻烦。另外由于page中需要保存一些元数据,比如LSN,所以及时这些page在磁盘上面是连续保存的,Multi-page Objects也会被切分为多段来保存。这样对于利用DMA 和 zero-copy I/O有些劣势。
-
另外一个就是系统不同的部分的耦合。比如下面的一般的page-oriented的操作逻辑,
pin page get latch newLSN = log.write(redo) update pages page LSN = newLSN release latch unpin page这里认为这种方式类似于一个write through caching,而更想要的是一种write back caching。而在Segment-Based Recovery中,数据在被从cache中ecivt中驱逐的时候写入磁盘,更像是一个write back cache。
-
Log Reordering,对于page-orientd的系统,更新操作的顺序是有LSN决定的,recovery的时候也必须按照这个顺序操作。Segment-Based Recovery在recovery操作的时候,不需要知道page的LSN (just need to make sure it is assigned before you commit, so that it is ordered before later transactions;)这样在支持不同优先级的事务的时候,可以将高优先级的安排到写入的前面。
-
Distributed recovery,page-orientd的方式不同组件耦合更多,分布式操作的时候麻烦更多。 Segment-Based Recovery分割了几个部分的[3],
• App <-> Buffer manager: this is the write-back caching described above: only need to interact on evic- tion, not on each update • Buffer manager <-> log manager: no holding a latch across the log manager call; log manager call can now by asynchronous and batched together • Segments can be moved via zero-copy I/O directly, with no meta data (e.g. page LSN) and no CPU involvement. Simplifies archiving and reading large objects (e.g. photos).
当然使用page的方式也有很多的优点。
0x11 基本设计
Segment-Based Recovery实际上也是一个WAL的系统,包含一般的四个基本组件:1. log file。按顺序记录每个操作,每个log entry包含一个LSN,事务的id,更新哪一个segment,这个segment是否包含一个LSN,已经这个操作如何redo的一些信息;2. application cache,没啥;3. buffer manager,内存中一个page cache。这里的coherent表示这里的更新反应了log order,读取立即能看到前面的更新。但是 Segment-Based Recovery允许先写入日志,在后面才更新buffer manager,这样可能导致一些incoherent的现象。4. page file,将数据保存在磁盘上面。Semgent的写入操作和buffer manager的交互如下:

和ARIES风格的WAL类似,这里也使用three-pass的恢复操作:1. 分析,估计要从log那里开始恢复操作。这里的一个特点是开始的点是估计的,而不像ARIES一样是确定的;2. Redo,重复操作;3. Undo,撤销不能redo的操作;另外还可以支持segment-based和page-based同时存在:
// Hybrid redo:
foreach(redo entry) {
if(entry->clears_contents())
segment->corrupt = false;
if(entry->is_lsn_free()) {
entry->redo(segment);
} else if(segment->LSN < entry->LSN) {
segment->LSN = entry->LSN
error = entry->redo(segment);
if(error) segment->corrupt = true;
}
}
// 支持segment-based和page-based同时存在,并支持切换
log(transaction id, segment id, new page type);
clear_contents(segment);
initialize_page_header(segment, new page type);
这里的redo是physical的,即会记录下具体改变的数据,而不是一个逻辑的操作(physical: write pre- or post-images (or both), logical: write the logical operation (“insert”)),undo是logical的。这个的redo操作和ARIES风格不同,这里通过分析LSN等来保证redo只会apply一次,而Segment-Based Recovery保证的是至少apply一次,这样对于写入操作也有一定的限制。Segment-Based Recovery要求是blind write。Paper中举例了一个segment-based的index设计的例子,
// Insert value into B-Tree node
make in-memory preimage of page
insert value into M’th of N slots
log (transaction id, page id, binary diff of page)
// Update N segments
min_log = log->head
Spawn N parallel tasks; for each update:
log (transaction id, offset, preimage, postimage)
Spawn N parallel tasks; for each update:
pin and latch segment, s
update s
unlatch s
s->lsn_stable = min(s->lsn_stable, min_log);
Wait for the 2N parallel tasks to complete max_log = log->head
Spawn parallel tasks; for each segment, s:
s->lsn_volatile = max(s->lsn_volatile, max_log); unpin s;
Segment-based indexes的更新操作比如是blind write(write content that do not depend on the previous contents)的,知道在哪个位置写入,而不管这个node的其它内容。在写入日志的时候,可以记录下page的binary diff,也可以直接记录这个page的preimage和postimage。Blind writes可能会明显增加比physiological方式的log开心。这里使用这两种方式同时存在来优化这个问题。
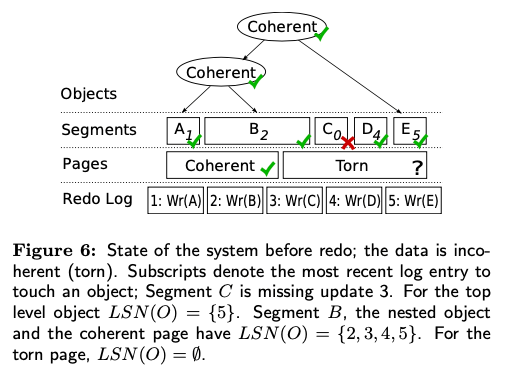
恢复操作要处理的两个问题是torn (incoherent) data(the object was partially writ- ten to disk), 和 inconsistent data(An object is consistent if it is coherent at an LSN that was generated when there were no in-progress modifications to the object)。Paper中的Coherency和Consistency用了很学术的定义。在segment-based recovery中,recovery操作第一个确定一个可以丢弃的log点,这个点是估计的。第二步是按照log顺序重放log。redo操作的时候,这里的segment每个可以并发进行。redo之前的segment可能是torn状态的,segment写入磁盘的时候会有一个checksum。如果checksum不对,会让redo操作完成在检查。如果不能的话只能向前会滚。这个逻辑和ARIES风格的WAL有不少的不同,这里写入的segment可能是存在问题的,可能可以由redo来fix。
0x12 评估
这里的具体信息可以参看[2].
参考
- Concurrent Updates to Pages with Fixed-Size Rows Using Lock-Free Algorithms, VLDB ‘20.
- Segment-Based Recovery: Write-ahead logging revisited, VLDB ‘09.
- https://people.eecs.berkeley.edu/~brewer/cs262/Lec-Segments.pdf
