F1 Lightning: HTAP as a Service
0x00 基本架构
VLDB‘20上面出现了不少的关于HTAP的Paper,其中这篇是Google的F1最新的一篇,主要的内容是是在现在的OLTP系统和F1 Query上面实现一个HTAP的系统。其核心的方式和不少的系统类似,通过消费OLTP系统的Log,来构造OLAP的部分,实现列式部分的存储。同时AP的查询利用了已经存在的F1 Query系统。从而实现HTAP as a Service。F1 Lightning的基本架构如下,主要的组件有这样的一些:1. Data Storage部分负责对数据进行存储,存储的格式以AP型应用优化;2. Change Replication,负责消费OLTP系统的日志,来更新对于AP的数据;3. Metadata Databse,存储系统的一些元数据和状态信息;4. Lightning Master,负责协调管理Servers。
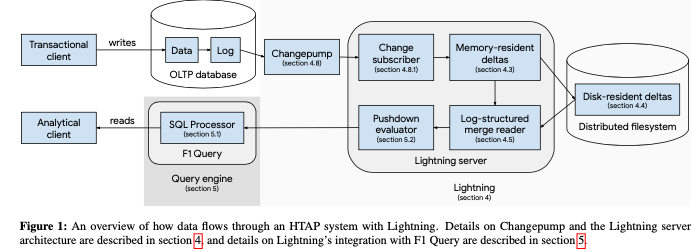
0x01 基本设计
F1 Lightning使用MVCC的并发控制方式,并提供SI级别的隔离。对于F1 Lightning中的一个查询,会有一个对应read-ts,类似于在TP系统中这个read-ts的一个快照下面的数据读取。这个ts的选择可以决定查询能够看到的数据。这里引入了safe timestamp的概念,即可以被F1 Lightning查询的数据,其中max safe timestamp为到这个时间戳为至的所有变动都已经应用到F1 Lighting中,而min safe timestamp则表示F1 Lightning中能够查询的最老的数据。这里从而得出一个queryable window的概念。和一般的OLAP的系统一样,F1 Lighting存储数据的时候也是使用delta data + base data的方式。F1 Lighting使用LSM-tree来保存,这里保存数据称之为为partial row versions,包含了一行数据一个版本的部分信息,由一个primary key和一个timestamp指定。主要包含三种类型的partial row versions数据:1. inerts,表示添加信息,包含一行数据的全部信息;2. updates,包含一个非key行的某些列的信息,没有更新的列没有包含;3. delete信息,只会记录删除key的信息,不包含数据。
-
数据写入到 F1 Lightning中的时候,会写入到内存中的一个B-tree的行存的结构中。使用一个线程来apply OLTP系统的log,例外的一个线程来定期清理垃圾数据,即GC操作。这种设计下面,这个时候写入的数据是没有持久化的,如果这个时候系统crash的话,这部分的数据丢失。丢失的数据这里会重新从OLTP系统中获取。这部分的checkpoint操作会将这个B-tree的数据写入磁盘,查询操作的时候要从磁盘中读取出来,和一般的数据系统类似。而另外的一种操作刷内存中数据的操作,这个操作和checkpoint的不同的是,这个操作会将数据转化为列存的方式。
-
磁盘的delta数据以读优化的格式保存,支持多种的数据保存格式。一般delta filea分为两个部分,数据部分和索引部分。数据部分使用PAX的格式保存,而所以部分是一个稀疏的B-tree索引结构。索引部分一般小得多,可以cache到内存中。
-
Delta数据终将会merge到base数据中,这里使用mergeing和collapsing两个操作实现数据的合并,
Merging deduplicates changes in the source deltas and copies distinct versions to the new delta. Because the source deltas and the new delta do not necessarily use a common schema, merging performs schema coercion while copying rows. Collapsing combines multiple versions of the same key into a single version.除了上面的部分之外,这里还引入了Delta compaction,将多个的小的delta通过compaction为单个的大的delta。Compaction被实现为四种类型,active compaction, minor compaction, major compaction 以及 base compaction。Active compaction操作对内存中的delta进行compaction。Minor compaction and major compaction对磁盘上面的delta数据进行操作。而 base compaction形成心的snpashot data。
-
F1 Lightning实现OLTP系统到AP部分的schema变化,使用logical shema到physical shema的映射方式,例子如下。不一定都会有这种Logical到Physical的映射方式。
Logical column Physical column Id Id TS TS OP OP Address Address Address.City City Address.State State
对于不同源的Log数据,F1 Lightning通过Changepump的抽象来提供一个统一的接口,隐藏了不同LP数据源Log的不同,另外Changepump将以事务为核心的日志转化为面向分区的日志。另外这个Changepump还会负责维护transactional consistency,为每个分区获取maximum safe timestamp的信息等。对于一个F1 Lightning的server,其会维护多个partition,通过向Changepump订阅相关partition来获取数据变动的信息。订阅操作会有一个start timestamp,向Changepump说明只会订阅这个timestamp后面的数据。向Changepump订阅的数据主要分为两种类似,一种是change updates,另外一种是checkpoint timestamp updates。前者包含订阅key访问那的数据变动信息。这里对于同一个Key,总是会更具timestamp的先后来投递数据,但是不同行数据的变动信息可能是乱序到达的。所有这里对于不同的primary key来水,maximum safe timestamp可能相差比较大。为了处理这个问题,这里引入了checkpointing机制,Changepump会周期性的发送checkping信息,来通知订阅者一个时间戳之前的数据都已经投递了,
For efficiency reasons, Changepump does not deliver a checkpoint timestamp along with every single change update. Changepump batches change reading from the change log and divides the work into parallel substreams that are loosely coordinated, meaning that checkpoint generation has a non-trivial cost.
对于Changepump的订阅者来水,Changepump看起来是一个单独的服务。但是实际上Changepump回是多个实例组成,这里Changepump client library会将多个Changepump server来的数据合并。Changepump对于最近的数据,会在内存中维护一个cache,来提高性能。对于次级索引,这里将其看作为一个derived tables。维护这些tables不是通过向Changepump订阅数据,因为这些table实际上不是OLTP的数据库,另外的一个问题是需要对数据进行shuffling,以服务安装次级key排序的要求。这里使用的方式是将数据安装需要key的顺序写入到Bigtable中,利用Bigtable来作为shuffle的工具和数据保存的中介。维护derived tables通过scan对应Bigtable中数据的对应range。
- F1 Lightning支持Online repartitioning,用于在线线修改分区情况。在一个分区的大小超过一个阈值或者是这个分区的load太高的时候,系统会对这个分区进行分裂的操作。第一种情况会选择按照大小将partition分裂,第二种情况会根据没有被更新的操作的情况进行分裂。选择好从那个点分裂时,线注册一个新的处于非active状态的partition,注册完成之后,会订阅Changepump的数据,当新分区数据catch up的时候,会将原来的分区deactive,将新分区设置为active。同样也会有partition merge的操作。
查询通过F1 Query完成,F1 Query查询制定的时候,操作会选择database-level maximum safe timestamp作为query timestamp。根据不同的查询目的地生产不同的执行计划,对于OLTP直接生产逻辑的执行计划,而实际的执行操作应该是交给了OLTP系统,对于F1 Lightning上面的操作,会生成物理的执行计算。另外会使用Subplan pushdown来优化性能。
0x02 评估
这里的具体信息可以参看[1].
TiDB: A Raft-based HTAP Database
0x10 基本架构
TiDB也是一个HTAP的系统,其TP的部分主要是按照Spanner和F1的架构设置的,对于AP的部分,通过在Rafe中加入一个learner来获取数据库的数据,构建额外的一个列存的部分,来实现分析类型的操作。这里Raft中加入Leader角色不同一般的Follwer,对于Learnder这里完全是异步复制的,而其一致性的保障通过read time。TP部分的数据以行存的方式保存到TiKV中,而AP部分的数据以列存的方式保存到TiFlash中。行存数据被编码为Key:{table{tableID} record{rowID}},Value: {col0, col1, col2, col3}的格式,Range分区作为一个Raft组保存到多个服务器上面。
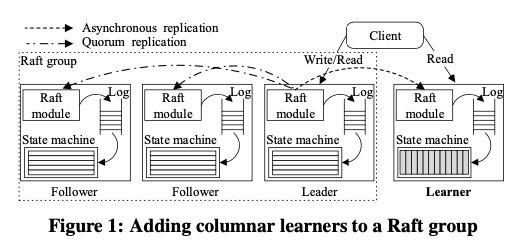
0x12 基本设计
对于TP的部分, Paper中讨论了不少的优化策略,比如Rafe的Pipeline优化,以及通过read index和lease read实现的follwer read的优化。另外对于维护大量的Region/Range,即分区,进行的hearbeat策略上面的一些优化,来降低Placement Driver的压力等的优化。同样的这里也讨论了Ragion,即分区的分裂和合并操作,这些操作作为一个Raft操作啦进行。基本的流程如下,
-
PD发动一个split指令给一个region的leader;leader在接受到这个指令的时候,将这个指令转化为一个log,并复制这项的log到follwer节点上面。一个quorum收到了这个split指令之后,指令在这些节点上面apply。这个操作会更新原始region的range信息以及epoch信息,并创建一个新的region。这个操作必须是原子的,并且要求在磁盘上面持久化保存。分裂的时候处理故障的逻辑,
Note that the split process succeeds when a majority of nodes commit the split log. Similar to committing other Raft logs, rather than requiring all nodes to finish splitting the Region. After the split, if the network is partitioned, the group of nodes with the most recent epoch wins.对于merge region的情况,操作时类似的。merge会使用两阶段的操作策略:线停止一个region接受新的操作,然后将这个region的range merge到另外的一个region中,这点的操作和split的情况有所不同。
对于AP的部分,数据保存也是delta加stable部分的保存方式,保存delta数据的部分为称之为DeltaTree,为一个B+ tree索引的列存结构,stable的部分以chunk为单位压缩保存,其存储一个range那的数据,使用类似于Parquet的格式保存数据。新的delta数据被批量添加到结构中,数据会在内存中有缓存,并会在磁盘上持久化一份。同样地,这里也会通过compaction的方式将多个的小的delta数据compaction操作为大份的delta数据。最终这些delta数据也会通过merge操作和stable数据合并,
Merging deltas is expensive because the related keys are disordered in the delta space. Such disorder also slows down integrating deltas with stable chunks to return the latest data for read requests. Therefore, we build a B+ tree index on the top of the delta space. Each delta item of updates is inserted into the B+ tree ordered by its key and timestamp. This order priority helps to efficiently locate updates for a range of keys or to look up a single key in the delta space when responding to read requests.
- Paper中描述的TP部分的事务操作流程:1. 接受到begin指令之后,从PD获取一个start ts;2. SQL engine执行SQL DML操作。数据从TiKV中获取,写入操作会线cache在本地内存中;3. 接受到commit请求的时候,SQL engine开始执行两阶段操作。随机选择key作为这个事物的primary key,作为一个lock的角色。发送prewrite请求到TiKV的节点。所有的prewrite成功之后,在向PD请求一个commit ts,然后发送commit请求到TiKV,TiKV会commit请求,并回复SQL engine;4. SQL engine给客户端返回成功;5. SQL engine再去commit secondary key,,异步清楚lock。这里和Google的Percolator的类似。TiDB这里支持乐观事务和悲观事务,两者的区别在于lock的获取。乐观事务中,lock在prewrite的时候增量获取,而悲观事务在prewrite操作之前获取。悲观事务中,获取lock的时候会请求一个for update ts,如果不能获取lock,则从这里重试操作。获取lock这个可以使用for udpate ts作为读取数据的ts,而不是start ts。此时实现的隔离级别为RR。这里同样也可以实现RC级别的隔离,区别在与RR的时候读取到一个加锁的数据的时候,RR会报告一个冲突,而RC会直接忽略。
- 而对于AP部分的操作。TiDB中,对于logical plan使用了rule based的优化器,而对于logical plan到physical plan,使用了costed based的优化器。由于TiDB可以使用两种类似的数据,TiKV 和 TiFlash,这样对于一些请求可以使用多种的策略:比如对于scan操作,可以scanning row-format tables in TiKV, scanning tables with indexes in TiKV, 以及 scanning columns in TiFlash。所以在优化器指导生产执行计划的时候,会同时考虑到这些不同的存储的特点,这部分在Paper中描述[2].
这里的核心内容都可以在互联网上找到,从论文的角度看没有特别多新的地方。核心的几点:基于Raft leaner的AP部分的异步复制,TP的数据和AP的数据分开存储,和一般AP存储差别不到的delta+stable/base的列存方式(优化delta保存使用了delta tree),以及一优化器同时考虑到TP和AP的数据存储等。最近的不少的Industrial Paper都是对于一些系统,挑选其中的一些的简要的描述,和一般Research Paper的风格差别还是不小的。
0x13 评估
这里的具体内容可以参看[2].
参考
- F1 Lightning: HTAP as a Service, VLDB ‘20.
- TiDB: A Raft-based HTAP Database, VLDB ‘20.
