MyRocks: LSM-Tree Database Storage Engine Serving Facebook’s Social Graph
0x00 基本内容
这篇Papper时关于使用RocksDB作为MySQL存储引擎的时候的一些优化策略。在总体的设计上,RocksDB为LSM-tree的结构,应用到MyRocks时,索引为cluster的。Primary Key中,一个内部的index id和数据库primary key的组合为一个RocksDB的Key,数据看cloumns值作为其RockDB的Value,元数据会包含一些SeqID和Flag的信息。而次级索引包含的Key包含Index ID加上次级的Key,在加上Primary Value,没有Value。

在此的设计知识,这里主要讨论的是MyRocks使用的一些优化方式:
-
Mem-comparable Keys,Key的比较在LSM-tree or B-tree这样的结构是一种常见的操作。LSM-tree在一些操作的时候会比较B-tree进行更多的比较操作,比如找到下一个Key的时候,B-tree用不着比较,而对于LSM-tree来说,需要在多个level中比较,找到实际的下一个。另外MySQL的字符串比较默认是不区分大小写的,这个给比较操作带来了更大的开销。这里会选择将MySQL Key编码为bytewise-comparable的格式。来避免一些额外的操作,比如序列化。这个格式这里没有具体说明,但是这个之前网上就有一些描述了。另外对于RocksDB逆序扫描笔顺序慢不少的情况下,这里引入了everse key comparator,以inverse bytewise order的方式存储到RocksDB中,将逆序扫描转化为顺序的。
-
Faster Approximate Size to Scan Calculation,这个优化主要是用于指导优化器。这里的scan key的数据在RockDB中,会找到min-key和max-key所在的blocks,并计算两者之间的block数量,
We implemented two features to improve the performance of query cost calculation. One was completely skipping cost calculation when a hint to force a specific index was given... . We also improved the RocksDB algorithm to get the estimated size of scan ranges by estimating total size of full SST files within the range first and skipping the remaining of partial files as soon as RocksDB determines that they would not significantly change the result.
-
Scan性能方面,LSM-tree一般不如B-tree。Bloom Filter常常用于提高LSM-tree提高点查询的性能。这里为了提高Scan的性能,引入了Prefix Bloom Filter。Prefix Bloom Filter记录以一个特定的prefix的key存不存在。另外,在删除了大量的数据之后,SST文件里面会包含大量的Tombstone数据,这个会明显影响性能,这里会在Flush or Compaction的时候,如果发现Tombstone数据比较多,会触发一个额外的Compaction,称之为 Deletion Triggered Compaction 。
-
LSM-tree删除是通过写入一个Tombstone来记录删除。在Put一个Key-Value之后,如果这个Pair在Memtable中,后面来一个删除的时候,可以直接将这个Pair删除,但是这个删除的Tombstone还得继续保存,因为下面的Level可能还有这个Key的数据。这样在很多情况下会带来不少不必要的Tombstone。为了优化这个问题,这里引入了一个SingleDelete的操作,这种操作遇到了一个Memtable中的Put记录时候,可以不用继续记录Tombstone。这种情况下需要使用者来保证数据一致性。如果可能Put一个Key对此,数据一致性保证不了。
-
DRAM Usage Regression,Bloom Filter由于提高LSM-Tree查询的性能,但是也会消耗不少的内存。LSM-tree结构下面,最后的一层灰占有大部分的数据,RocksDB可以选择不创建最后一层的Bloom Filter来提高性能,但是可能带来一些性能的降低。这里其它Paper中描述的优化方式有不同的Level使用不同假阳率的Bloom Filter。
-
SSD Slowness Because of Compaction,这部分是关于在SSD上面的一个优化。SSD的trim命令灰有助于其内部的空间管理,但是一些SSD在处理了大量的trim命令之后,会遇到一个临时的性能降低。这里的优化方式是会有一个rate limit来限制文件删除的速度,另外也会使用rate limit来限制compaction I/O requests,以避免对user请求的IO带来过大的影响。
-
Physically Removing Stale Data,这个优化是针对Facebook的一些应用场景。通过设置了一个Lmax,一些操作,比如Put添加的数据 or Delte产生的Tombstone记录,在达到Level Lmax进行操作,方便一次性回收更多的空间。
-
Bulk Loading,这种策略是优化一次性写入大量的数据。通过RocksDB File Ingestion API 直接创建SST文件。然后这些文件设置到Lmax中。
Paper中总结了使用MyRocks带来的一些好处。一般的经验来看,占用的空间更少是比较大的优势。
0x01 评估
这里的具体内容可以参看[1].
AC-Key: Adaptive Caching for LSM-based Key-Value Stores
0x10 基本思路
这篇paper关注点在LSM-tree的cache方面,提出了一个Adaptive Caching的思路。LSM-tree目前使用的不同的Cache有这样的一些。一种是Block Cache,和Btree-based的数据库中使用方式类似,Cache的是一个Block,一个Block中有多个的KV。这种Cache可以用于Scan的请求。而后面的KV Cache包含单个的Key Value。KPCache则包含了Key以及Value保存到磁盘上面的位置信息,类似于bitcask中的index,这种方式更加节省内存,但是即使是缓存命中了也会有一次额外的IO操作。
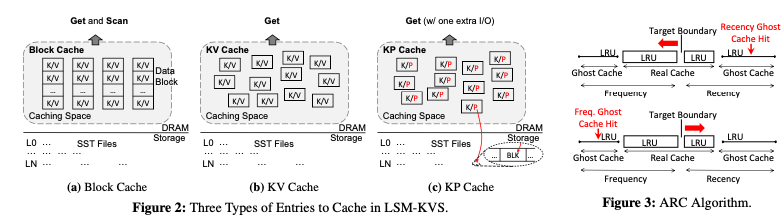
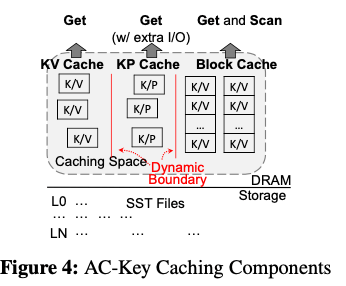
这三种Cache的方式都是有各自的优缺点,比如如果访问比较集中在少量的Key,KV Cache性能会更好,而如果访问比较分散的话,KP Cache能够Cache更多的数据,性能可能会更优一些,而Block Cache对于存在Scan的情况会更加适合。AC-Key的思路是将这三种方式结合起来,并且能够根据当前workload的情况自动调整。这个思路应用了ARC缓存替换算法的思路,ARC会根据当前动态的请求信息来调整LRU策略和LFU测量使用的内存空间。
0x11 基本设计
AC-Key在一定的内存空间的情况下,动态地调整着三种Cache占用的空间。Cache命中存在一下的集中情况:
- Case I:Hit in KV Cache,KV Cache命中,直接返回数据即可;Case II:Miss in KV Cache but hit in KP Cache,这种情况下,Cache了KV所在的文件位置。如果对应的Block可能已经Cache了,所以先查看Block Cache,没有的话再去读磁盘,将对应的Data Block放入到Block Cache。Value会被读取,之后KP Cache会被转为KV Cahe;Case III: Miss both in KV Cache and KP Cache,这里就需要到SST文件中去查找,如果找到的话,会添加一个KP Cahe。这种情况中,先请求SST文件的BF block,如果BF Block不在Block Cache中。
- Flush Handling,Flushing Memtable的之后,后面的Put请求如果添加Cache已经存在的数据,会造成Cache中的数据过期。Cache中过期中的数据不会影响到正确性,因为查找先查Memtable。先次Flush操作时候,就需要同步这些信息,因为新的Memtable可能不存在,查询Cache会返回旧的数据。这里需要一个Cache和Memtable同步操作,可以在Put操作的时候处理,也可以在Flush的时候处理。AC-Key选择的方式是在Flush的时候处理,将多个请求可以积累到一次处理,提高效率。
- Compaction Handling,Compaction的操作会影响到KP Cache和Block Cache。Compaction的操作的时候,AC-Key会更新KP Cache指向的Pointer的信息,对于Block Cache,会用新的Block替换。
而对于具体的Cache替换算法,这里提出了E-LRU的方式,和一些机遇成本/效率的Cache类似。AC-Key定义一个caching efficiency factor E, E = b / s,其中b为Cache命中的情况下节省的IO次数,s为Cache占用的缓存空间。一般而言有:block cache的时候,b为1,KV Cache的时候 b = f(m), KP Cache为f(m)-1。m表示为number of SSTs to search for the key,f(m)表示IO次数。LSM-based的情况下,一般为f(m) = m + 2,m个BF Block,加上一次index block和一次的data block。对于不同的level l,有 m = n0/2 if l = 0, m = l + n0 if l >= 1,其中n0表示为max number of SSTs L0 can hold,l表示 the level where the key resides。E-LRU操作的时候,替换操作的时候检查最后的a个cache entres,淘汰掉其中一个caching efficiency E最低的一个。其中a的值取决于the variance of the caching efficiency factor E of the cached entries。使用a = e ^ v计算,其中:where v is the standard deviation of the caching efficiency factor E of sampled entries in the caching component。如果 a一直为1 的话就是一般的LRU算法。
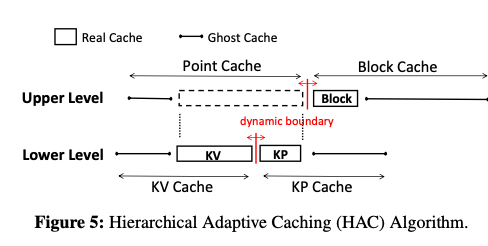
在这个的基础之上,这里还提出了Hierarchical Adaptive Caching,使用如下图所示的两层的设计,将KV Cahe和KPCache划为lowe level,Block Cache为Upper Level。Lower使用E-ARC的缓存替换算法,同时在upper level,在Point Cache和Block Cache直接也使用E-ARC算法。Lower Level的E-ARC操作基本逻辑:
-
和ARC一样,缓存也分为real和ghost的部分。Real Cache Hit的时候,可能是real kv or real kp。Real kp的时候就需要一次IO操作。取回的数据被放到real kv;
-
KV Ghost Cache Hit的时候,意味着要调大real kv的空间,使用δ = kE的粒度来调整,k为一个配置的参数。淘汰的时候,
After fetching from storage, insert the fetched KV to the MRU end of Rkv. To make room for this KV entry, evict from Rkv (resp. Rkp) if the target boundary is within Rkv (resp. Rkp), meaning that the target size of Rkv (resp. Rkp) is smaller than its actual size.即根据KV Cahe和KP Cahe目前的boundary,即分割的地方,到根据算法应该怎么移动这个boundary,来达到的target boundary的发现来决定淘汰那边的数据。
-
KP Ghost Cache Hit,这种情况下real kp应该调大,使用同样的δ = kE的粒度来调整,k为一个配置的参数。淘汰的时候类似,
To make room for this KV entry, evict from Rkv (resp. Rkp) if the target boundary is within Rkv (resp. Rk p ), similar to Case II. -
Cache Miss的时候,从磁盘中读取到KP的信息, target boundary在KV的时候淘汰real kv,否则为real kp。
0x12 评估
这里的具体信息可以参看[2].
参考
- MyRocks: LSM-Tree Database Storage Engine Serving Facebook’s Social Graph, VLDB ‘20.
- AC-Key: Adaptive Caching for LSM-based Key-Value Stores, ATC ‘20.
