Parallel Replication across Formats in SAP HANA for Scaling Out Mixed OLTP/OLAP Workloads
0x00 基本内容
这篇Paper是关于HANA数据库复制机制的一些内容,其主要的内容是如何实现并行的replication,以及适应OLTP/OLAP混合的workload。HANA这里提出的方式称之为Asynchronous Parallel Table Replication (ATR),和很多的HTAP的系统类似,ATR的思路也是实现在primary replica上面实现OLTP的服务,而在另外的一些副本上面实现OLTP的服务。ATR这种情况下需要处理OLTP实现的行层和OLAP使用的列存之间的差异。另外的一个内容就是其Parallel Replay特性,利用HANA使用的MVCC的机制来实现一种optimistic lock-free parallel log replay 方式。在这样的基础上,ATR的几个设计决策:
- 一个是使用replicate使用跨行存和列存的数据格式;将storage-level recovery log和replication log隔离。两个使用不同的格式,和MySQL有点类似;log的产生和发送和storage engine紧密结合;另外对于primary上,log记录record-level的SQL执行的结果(record-level result logging),即一种value log的方式,以此来避免一些不确定性和parallel log replay的一些冲突。对于其它的replicas,主要是parallel log replay,还有就是类似adaptive query routing的一些功能。
- 一般情况下,复制使用异步的方式(lazy replication),也可以支持同步的方式(eager replication)。ATR还会使用early log shipping方式,在相关的事务提交之前,对于的DML语句完成之后,就发送相关的log,而不是等到事务committed。这样要求primary的事务后面abort的话,replica执行了的操作也需要回滚。这种方式可以尽早地让操作在replicas上面可见。为了处理replica落后于primary的问题,ATR也支持查询设置一个maximum acceptable staleness。primary执行操作的时候,会在log里面commit log下面记录提交的时间。Replica上面replay log的时候会更新其replay到那个时间了。查询如果指定了最大的落后时间的话,查询可以被重新路由到primary上。Lazy的方式在性能上面有优势,但是也可能造成一些数据丢失,所以又引入了一个post-failure replica recovery来处理这个问题。
0x01 基本设计
在Log Records又这样的一些基本的字段:Log Type表示Log的类型,表示这个是DML log entry还是transaction log entry,后者比如是precommit记录,commit记录还是abort记录。前者是DML操作产生的,而后者是transaction manager产生的;Transaction ID;Session ID。DML log entries中还会包含操作类型,Table ID,Before-Update RVID,After-Update RVID,Data等内容。这里的RVID是一个赋给一个creaded record version,HANA使用MVCC的并发控制方式,每次更新一个record都是创建一个新版本,这个 RVID就是一个record的一个version的一个标识符。有Before和After操作的区别是因为在实际产生一个版本记录的时候,对应的记录前面的版本的RVID和后面要添加的区别。这样也就是说inert的记录不会有Before-Update的RVID,而delete的操作不会有After-Update的RVID。Before-Update RVID可以用于在replica中快速定位到一个record,而After-Update RVID的应用是为了使得primary和replica之间的RVID字段相同。下一个操作这条记录的DML log replay的时候,可以使用Before-Update RVID来定位记录,而After-Update RVID会在log replay的时候填充。Data记录里面,会记录下更新Column的ID,以及新的值。这样对于列和行都比较好地兼容。
-
Paper中比较强调的一些是其Parall Log Relay的功能,实现这个的主要思路是并发的replay DML log entry,而顺序地执行transition commit log。要保证得到的结果是相同的,commit log执行的顺序得和primary上面的一样。为列了降低replay的时候的操作冲突,ATR引入了SessionID-based log dispatch method 和 the RVID-based dynamic detection of serialization error的思路。Replica在接受到一些logs之后,log dispatcher会根据log的类型来分别处理。对于commit log的记录,会加入到一个全局的transaction log queue中,而其它的log,包括precommit,abort的,加入到一个DML log queue中。选择哪个DML log queue根据log中的session ID来决定。这样可以降低一些操作冲突。 log replayer会从queue中读取记录,并发的apply这些操作。为了保证一些log replay的顺序关系,ATR使用了一种optimistic lock-free protocol。基本思路是,ATR replayer先检查一个log entry对应的database record,在这个database record上发生在此log entry之前有没有log entry已经被applied了。如果没有,显然是有问题,称之为log serialization error。然后会重试replay的操作。在发现log serialization error的方式上,ATR利用了HANA中MVCC的一些特性,update和delete log通过意见存在的database record的RVID是否和log entry的Before-Update RVID对得上。对不上则代表有问题。对于insert的操作就是直接添加并设置RVID。
-
还有一个问题是Recovery。对于异步处理的方式难免存在log丢失的问题。可以使用的方式是store-and-forward的方式,即在primary侧先将日志保存下来。在replica侧会记录一个拉取到哪里了的值。这样的方式会带来一个log持久化的开销。而HANA采用的方式是通过比较primary table 和 its replica table记录的RVID来发现其差异。这个方式需要收集tables的RVID的信息。
Require: P , a set of RVID values from the primary table. Require: R, a set of RVID values from the replica table. 1: Delete the records R \ P from the replica. 2: Insert the records P \ R into the replica.这种方式也利用了HANA内存保存数据的一些特点,要不然扫描的开销会太大了。(这里是否可以使用不全量检查的方式,而是利用RVID。签名的log replay利用RVID来检查,应该也可以用来检查其数据不对。为了将log replay冲突导致的差异和log丢失导致的区分,每次recovery之后维护一个已经fix的标记。对于存在冲突,但是自上次recovery还没有fix操作的,可以向primary获取对于record的数据,来确定不同情况。而fix了的,就会是replay冲突的情况?)。
Paper中另外还提到一些实现中的问题。比如例如OOM这样的Run-time Error,其Run-time Error Handling机制主要是通过一段时间之后重试操作,超过了一定时间的话,做offline处理。DDL操作不同通过添加这种类型的一个log,而是通过DDL Transaction Replication,即维护metadata的方式,使得之前的metadata失效,但是要等到之前log repay完成。对于一些Read-own-write Transactions,读取如果是读副本的话,可能导致读取不到自己之前写入的数据,HANA的方式,一个是维护复制的watermarks的方式,来检查复制操作的时效性。另外一个是根据事务的信息来决定将这个操作重新路由到primary。
0x12 评估
这里的具体内容可以参考[1].
Asymmetric-Partition Replication for Highly Scalable Distributed Transaction Processing in Practice
0x10 基本内容
这篇Paper是关于HANA的Asymmetric-Partition Replication,是在前面的ATR上面的功能拓展。提出asymmetric-partition replication用来实现单独的分区复制,分区方式和primary的不一样。另外的一个是optimistic synchronous commit来优化一些2-PC的开销。这种Asymmetric-Partition Replication的应用Paper中的例子是比如:Independently Partitioned Replica,即分区方式不同的复制,比如OLTP和OLAP使用不同的分区方式;Distributed Secondary Index,分布式二级index也可以看作是一种分区方式不同的复制;另外一个是Online Table Re-partitioning。这种Asymmetric-Partition的方式的应用之外,Paper中还提到了其采用几个优化策略:
-
Optimistic Synchronous Commit Protocol。即OCS-R,其基本的思路如下图。为了在primary和replica上面提交一个事务,2PC的方式需要primary和replica之间至少2个RTT,3次的IO操作。OSC-R的方式可以在1个RTT,一次IO操作内提交一个事务。由于replica的数据从primary复制而来,所以及时replica故障了,还是可以从primary恢复数据的。一个事务在DML操作完成之后,primary向replica发送一个precommit的log,然后在本地写入一个commit log。此时primary就会返回,而后面向replica发送commit的log。而在这样的实现下面,replica上面的查询的记录处于precommit状态的时候,需要有一个等待的操作,来等待其状态改变。
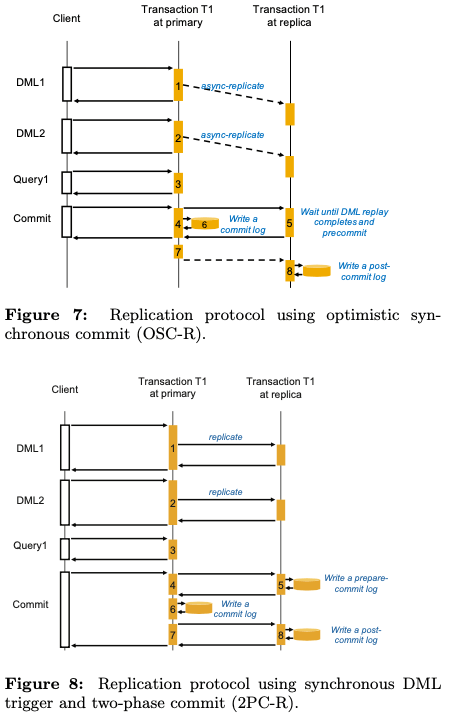
-
另外一个是MVCC-based Online Replica Addition,即创建一个新replica的时候,先是开始从primary拉去日志,同时从primary拉取一个snapshot的数据。并且在拉取snapshot的时候就会apply logs。为了实现这个拉取snapshot时候并发的DML操作,这里利用了HANA使用MVCC的特性。同样是基于前面提到的RVID (record version ID)。在apply一个log之前,检查一个database record前面的版本的RVID是否和这个log的Before-Update RVID对得上。如果对不上,则这个log的apply会被暂缓。
0x12 评估
这里的具体信息可以参考[2].
参考
- Parallel Replication across Formats in SAP HANA for Scaling Out Mixed OLTP/OLAP Workloads, VLDB ‘17.
- Asymmetric-Partition Replication for Highly Scalable Distributed Transaction Processing in Practice, VLDB ‘20.
- Replication at the Speed of Change – a Fast, Scalable Replication Solution for Near Real-Time HTAP Processing, VLDB ‘20.
