Schema-Agnostic Indexing with Azure DocumentDB
0x00 基本内容
这篇Paper是关于 Azure DocumentDB如果建立索引的的。Azure DocumentDB是微软的一个文档数据库。文档数据库中的每个数据库中的每个Collections保存的是JSON式的Document。特点是没有Schema,可以随时添加新的字段,带来了很大的灵活性的同时也带来了一些问题,比如在这种Schema-Agnostic的数据模型上面如何构建Indexing。这篇Paper描述的就是一种Schema-Agnostic Indexing。默认的情况下,DocumentDB会为所有Documents自动构建索引,不用用户自动指定schema或者是次级索引。Indexing构建的时候,会有一个性能,存储空间以及一致性等上的一个tradeoff,DocumentDB可以选择不痛的indexing policy,选择不同的tradeoff方案。Schema-Agnostic的索引方案,DocumentDB首先有这几种方式处理Document,
-
首先DocumentDB将Document解析为一个JSON Tree,基本思路如下图所示,对于一般的Key-Value的时候,子结点就是Key。对于数组的情况,子结点为数组索引,从0开始。这样对于一个Value,都可以对应到这个JSON Tree上面的一个Path。这里将node称之为一个label,Document会有一个虚拟的root node。对Documents构建索引的时候,默认情况下DocumentDB会为Documents上每一个Path都构建索引(可以配置排除)。
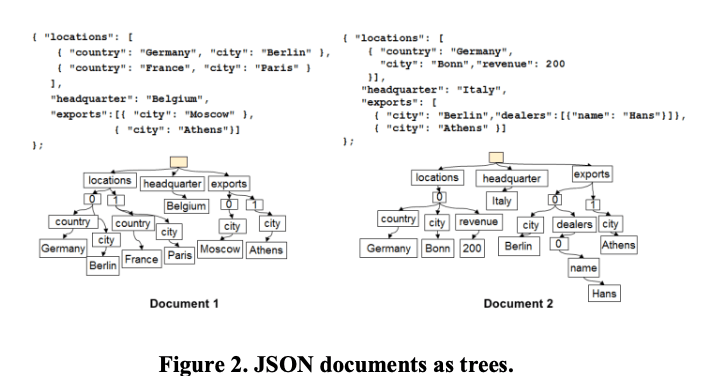
-
每更新一个Document的时候,这里就希望即使是一个很复杂很多层的JSON结构,也能想yiceng的Key-Value一样索引的更新成本。索引实际上就是Path和Doc IDs之间的一个映射。这样forward index mapping的思路是(document id, path),即Doc ID映射到Path,另外一个是inverted index mapping,即 (path, document id),Paht映射到Doc ID。inverted index是一种很有效的方式,因为不同的Documents会有很大一部分相同的部分。所以这里将不同Documents union之后的结构称之为index tree。Index tree的node称之为一个index entry,包含了label和position values,以及保护了这个node的文档的ID集合。其基本结构如下图。由于是一种inverted index,使用的术语和倒排索引的术语类似,Terms以及Postings等。
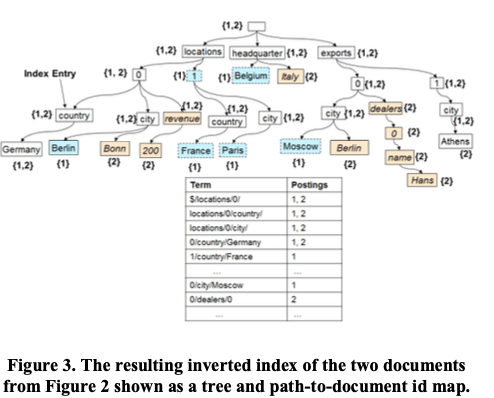
0x01 索引结构
在上面描述的索引模式下面,DocumentDB将Index Entry的逻辑结构表示如下图。其Key是一个Term,默认使用5个byte表示,Value为一个Postings Entry,为了压缩存储的空间,引入了PES(posting entry selector)。这里的Term只使用了5个byte表示是一个有意思的地方。Term在DocumentDB就是一个有向的Path,这个又向可以有不同的模式:forward path为有root node出发到leaf node的方向,而reverse path与之相反。不同的方向有不同的存储和维护的开销,也会影响到查询。比如SELECT * FROM root r WHERE r.location[0].country = "France"这样的等值比较查询,或者是SELECT c FROM c JOIN w IN c.location WHERE w = "France"这样的匹配,或者是SELECT * FROM root r WHERE r.Country < "Germany"这样的范围查询。在forward path和reverse path之外,partial forward path和partial reverse path分别是forward path和reverse path的一定长度的一部分。

每个term使用多少个semgents就直接影响到了query functionality, performance 和 indexing cost,需要在查询功能、性能和索引的开销上做一个tradeoff。DocumentDB默认选了3个segments,主要基于这样的考虑:1. 大部分的JSON Doc都是一个root,一个key,然后对应到一个value,也就是说大部分的就是一个key-value的结构;2. 三个已经能够比较好的表示不同的path,又能又比较好的成本。另外的一个是Path的编码方式,DocumentDB使用了如下的编码方式:对于Partial Forward Path,这种长用于 range 和 spatial indexing的,选择三个suffix nodes来表示。对于数字性和非数字的有不同的编码方式。对于爷一辈和父一辈的结点,都是计算一个hash之后选择最低的一个byte。而对于数字的,选择了一个特殊的hash,因为数字大部分在100以内,这里hash的设置是的100更新精确,而更大的更加不精确。而对最后的一个segment,对于非数字的选择最前面的一部分 或者是 保存全部的数字,这样可以保存其字典序的信息,对于数字的也和非数字的差不多。对于Partial Reverse Path的,和Partial Forward Path类似,也是选择3个suffix nodes,但是逆序排列,
Partial Reverse Path Encoding Scheme is suitable for point query performance. This scheme also serves wildcard queries like finding any node that contains the value "Athens" since the leaf node is the first segment. The key thing to note is that the intermediate nodes of each path, across all the documents are generally common while the leaves of the paths tend to be unique.
另外一个是Postings Lists的表示,如果是使用8byte的Doc ID,直接保存的话消耗的空间太大。这里使用了几种策略来压缩这里使用的空间。第一个是对Postings List进行分区。Doc ID是递增产生的,给压缩保存带来了一些方便。分区的思路是将使用一个postings entry保存一个specific document id range,最多16K个IDs。这样可以使用2byte保存,或者是使用16K bits的一个bitmap来保存。为了实现这种方式还需要postings entry selector (PES),长1到7 bytes。对于ID在0-16K,使用第一个postings entry,16K-4M使用接下来的256和posting entries, 4M-1B使用接下来的64K postings entries,以此类推。另外也会使用其它的一些动态编码方式来压缩空间
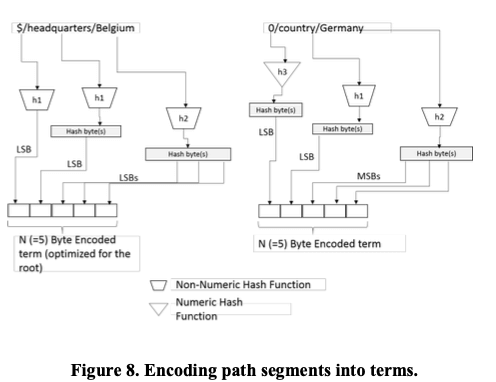
索引的数据结构上使用的是Bw-Tree。索引更新的时候,由于是term-to-postings list的映射方式,对于insert或者是delete的操作,需要更新所有的保护对应Doc的postings list。这样的索引更新操作在一边的B+-Tree上,表现为read-modify-update操作。这样在term-to-postings list索引方式上面,由于其空间局部性较低,可能造成需要每次都要读取一些pages更新。为了处理这个问题,DocumentDB使用了logically的方式,为Bw-Tree添加了一个blind incremental update的功能。Blind incremental update可以记录下更新而不用实际访问更新的数据。在一个page被swap到磁盘上的时候,会在内存中流行一个小的slim page stub记录,blind incremental update操作可以根据流行的信息来记录下操作。比如添加一个新的时候记录下t -> d+,
A blind incremental update of a key prepends a delta record that describes the update to the relevant page. In the case of document ingestion in DocumentDB, such a delta record describes the mapping t -> d+, where d is the document id, t is a term, and “+” denotes addition (similarly, “-“ would denote deletion). This delta record append operation does not involve any read I/O to retrieve the page from storage.
在后面查询的时候,需要引入merge的操作来合并这些数据。另外前面提到DocumentDB支持不同的indexing policy,这里描述的是Consistent模式下的更新方式,这种模式要求索引和Document的更新是同步的,而另外还支持Lazy的模式,即异步更新索引。另外就是None模式,即不需要索引。在Lazy的模式下面,index更新是后台进行的,
0x02 评估
这里的具体信息可以查看[1].
参考
- Schema-Agnostic Indexing with Azure DocumentDB, VLDB ‘15.
