Kernel/User-level Collaborative Persistent Memory File System with Efficiency and Protection
0x00 基本思路
这篇Paper是一篇关于NVM上文件系统设计的paper。这篇Paper提出的KucoFS的思路是内核态和用户态结合的思路,来解决完全的内核态文件系统 or 完全的用户态文件系统存在的各自的缺点。在兼容原来的接口的情况下,还可以实现应用直接访问文件系统的数据,并实现很高的protection功能。KucoFS的基本架构如下。其核心思路是用一个用户空间的lib,ulib来实现文件系统的接口。所以这里并不是兼容原来的syscall,而是原来的posix的文件操作接口。不过这样的话并不是完全兼容的,毕竟还是依赖于ulib。在ulib下面,是内核中文件系统逻辑的实现,这个一个特点是ulib可以直接看到文件系统的结构,进而可以直接访问数据。但是对于更新来时,需要通过一个msg buf来放松到内核中的一个master来处理。
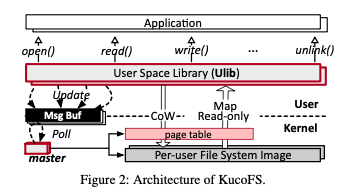
0x01 基本设计
整体设计上,KucoFS将文件系统image的一部分以只读的方式映射到用户空间,这样读取数据的时候可以直接访问数据。写入数据的时候总是以CoW的方式写入,ulib先想master申请可以写入的数据pages,然后想其中写入数据,写入完成之后再将元数据更新的请求发送到master,由master来完成更新元数据的操作。管理文件系统中内部结构的时候,KucoFS使用NVM+DRAM结合的是,一般情况下只会设置的DRAM,这样可以提高性能。内存中的一个inode table保存了指向实际inode保存位置的指针。这个inode table实际上就是一个预先分配的数组。对于每一个user,这个table的第一个都是指向root inode。这样也就是说每个user看到的root inode可能是不一样的。空间管理上面,使用类似于ext2的block mapping来管理pages,这种方式更加简单,便于实现lock-free fast read 。另外对于dentry,每个dir使用一个dentry list来保存下面的dentry。这个dentry list也是保存在内存中的。为了保证元数据的 durability 和 crash consistency,每次操作元数据的时候,会先写log。在这样的基础设计之上,KucoFS的另外的一些设计:
- Index Offloading,master在处理请求的时候需要根据index来查找相关的结构,以及更新的时候更新index。这些完全由master来处理的话会给master带来不少的压力。由于一部分文件系统image以及映射到用户空间了,这里的思路就是直接由ulib来完成index查找的工作,对于一个更新的操作,比如creat请求,ulib会在请求中带上parent dentry的信息。Master就可以直接进行检查和更新相关的操作了。
- 要实现这样的思路,还有几个问题需要处理:1. 第一个就是在master可能并发更新 directory tree的时候如何读取到consistent directory tree。这里对于每个dir都使用一个基于skip list实现的dentry list。更新的时候原子地更新一个pointer就能完成添加的最后一步操作,这样不需要lock,ulib就可以看到一个consistent view。对于rename的情况,需要更新两个dentries,这样就可能同时看到两个相同的文件,这里的解决方式是在dentry在一个flag来标记这样的操作,避免ulib读取到中间的不一致状态。2. 另外的一个问题是ulib在读取的时候,一个数据可能被删除了。这个是并发数据结构中常见的一个问题。这里的方式是对于inode和dentry都加入了一个dirty bit。其被删除的时候,先标记这个bit,垃圾回收的时候使用epoch-based reclamation机制。Master维护目前的epoch,ulib会记录目前工作的epoch,master回收最老的epoch之前的数据,不过这样受到ulib被blocking的影响,而paper认为这个问题不是很大。3. 另外的一个问题是提前定位的dentry,pre-located dentry,可能已经改变了。使用master操作的时候需要检查。
- Master使用logging来保证元数据的crash consistency。这里通过Batching-based Metadata Logging,即批量处理来优化性能。
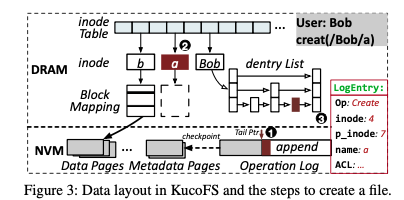
这里写入的方式是数据是ulib操作,而元数据更新master来完成。为了实现写入的高效率、consistent和safe,这里使用 pre-allocation and direct-access range-lock的思路。基本方式是数据更新的时候总是使用CoW的方式。写入操作的时候ulib先请求master对file加上lock,并预留出data pages,使得这个进程可以有这些pages的写入权限。然后ulib写入数据,在向master发送请求更新元数据。在这样的基本逻辑之上,这里使用另外的一些策略有优化性能: Pre-allocation,写入数据的时候会预先分配一些空间,来避免一些第二步的操作;Direct Access Range-Lock,只会lock需要写入的范围。另外读取操作,这里要保证在有并发更新的时候,如何读取到一个file的一个consistent的snapshot。CoW和委托为master更新元数据的方式也方便了这里的处理。这里将KucoFS的读取方式称之为lock-free fast read,来保证读取操作不会读取到没有完成的写入操作,即不会脏读。这里block mapping使用一个96bit的字段,有四个部分,最高bit为start标记,后面54bit为version,然后接着1bit的end标记,最后是40bit的pointer。以更新三个pages为例,会在第一个page标记start,最后一个标记end,三个page的version必须相同。读取的时候reader就可以知道一个进行中的write,通过start、end直接的version就可以判断。
0x02 评估
这里的具体信息可以参看[1].
Assise: Performance and Availability via NVM Colocation in a Distributed File System
0x10 基本思路
这篇Paper会发表在OSDI ‘20上,在arXiv有预印本。这篇Paper的思路是做一个分布式文件系统,类似于Ceph的那种而不是GFS的那种。其基本的架构如下图。其核心是利用了RDMA和NVM两种新型的硬件,另外将主要使用的数据放到本地,这样访问数据大部分的情况下都是使用本地的NVM。跨网络,即使是RDMA也会带来比本地访问大得多的开销。不用跨网络可以显著提高性能。直接本地访问带来的问题就是可用性的问题,这里需要处理好如何将本地的数据复制到其它结点上面的问题。本地访问带来的另外一个问题是数据一致性的问题,这里的实现利用了POSIX文件系统接口的一些特性。文件系统会选择应用在调用fsync的时候同步将最近的更新同步到其它的结点,完成数据的复制。另外在OptFS的分析中,fsync包含了顺序和持久化两个层面的语义,这里Assise也引入了OptFS的研究,在适当的时候调用dsync而不是fsync来实现更好的性能。dsync只有数据持久化的语义。

0x11 基本设计
Assise中存在一个中心的Cluster Manager,而进程访问的时候,会通过LibFS来连接到本地每个NUMA区域的一个SharedFS。这个SharedFS以subtree的粒度保存了文件系统一部分的数据,关于这些的元数据会保存到Cluster Manager中。LibFS访问一个subtree的时候,会先请求Cluster Manager建立起一个RDMA replication chain。在这样的基本设计执行,Assise的一些基本操作:
- Write path,写入操作的时候,LibFS直接写入到NVM的一个process-local cache。这个write cache是一个update log,而不是一个block cache。使用log写入的方式来提高性能。避免复杂的block管理。为例处理结点故障的情况,这里会将update log复制代其它的结点上面。这个复制的动作发生在调用fsync or dsync的时候。复制通过RDMA来复制,绕开Kernel以实现最高的性能。这里的replicas chain的最后一个结点在完成复制这个update log之后,会向回复一个ack来通知复制已经完成了。
- Read path,读取操作的时候,LibFS会首先读取本地的 process-local cache。如果 process-local cache没有的话,再去读取对应subtree的最近的 cache replica。如果这里还没有的话,在去读取reserve replicas和 cold storage。读取的数据会先cache在process-local的内存中。另外LibFS会另外预取一些数据。
- Cache eviction&Permissions and kernel bypass,当一个LibFS的缓存空间使用完了的时候,会先复制那些没有复制的更新数据到其它的结点。然后使用LRU的策略来淘汰数据。另外在权限的问题,这里是有一个 single administrative domain的假设,这个假设简化了一些问题的处理。LibFS只会cache那些经过了鉴权的数据。
一致性的问题是一个很麻烦的问题。这里的一致性处理了crash consistency和 cache coherence两个方面的问题。Assise提供的是prefix semantics,前缀语义的crash consistency,即如果有数据丢失的话,只会丢失最近操作的一个前缀。即最近的一个没有丢失操作的前面不会有其它的丢失了的操作。˙这里的写入是先写入到本地的update log。在使用fsync的模式下面,每个更新的操作记录在update log中是按照操作的顺序保存了。在使用 chain- replicating的方式复制到其它的结点上面的时候,利用RDMA的一些特性来保证写入其它结点的时候顺序也是和本结点是一样的。这样恢复操作的时候丢失的只会是没有完成复制的一个prefix。Assise还提供了cache coherence with linearizability,这里利用了lease的机制。读取和写入操作会先获取一个lease,其中读取lease可能同时有多个的进程获取,而写入的只能有一个。这种方式在读占多数的情况下工作很好,为了优化写密集的应用,这里使用subtree lease的方式,来获取一个指定目录的lease。Leases通过LibFS向SharedFS获取。
0x12 评估
这里的具体信息可以参考[2].
参考
- Kernel/User-level Collaborative Persistent Memory File System with Efficiency and Protection, arXiv.
- Assise: Performance and Availability via NVM Colocation in a Distributed File System, arXiv.
