ParallelRaft on PolarFS
0x00 基本思路
ParallelRaft是再PolarFS[1]中应用的一个针对特定应用的Consensus算法。ParallelRaft的特点是Out-of-Order ACK(乱序复制确认),Out-of-Order提交以及Out-of-Order Apply。一般情况下Consensus不会关系应用是证明apply log的。通用的情况下,log需要顺序地apply才能保证得到预想中的结果。但是很多情况下,不是顺序的乱序的apply也是可以的。最典型的情况就是如何就是一般的Key-Value Store的情况。如果log是关于KV Store的操作,只需要保证乱序操作的部分没有针对一个Key的两个操作就行了。这样乱序处理带来的一个问题就是可能每个节点上面都没有完整的日志,而在Raft中,是要求被选为leader的节点有全部的可能已经committed的日志的。因此就需要对ParallelRaft的leader election算法进行一些修改:
- ParallelRaft新leader仍然保证来会有全部的已经committed的日志,这样就需要一种方式来补全刚刚选出的新leader可能缺失的日志。为了处理这个问题,ParallelRaft引入了额外的一步merge的操作。Merge操作中,1. 对于已经committed的但是新leader没有的entry,会从其它的已经有了的节点拉去回来;2. 对于在其它结点上都没有committed的entry,如何每个结点都没有对应的数据,可以选择跳过;3. 对于没有committed的/不知道有没有committed的,总是会选择term更大的。除此之外,ParallelRaft还引入了一个checkpoint的逻辑,用于确定在某个点之前的所有的log entries都已经有了。
一个落后的follower想要追赶leader时,可以使用fast-catch-up or streaming- catch-up的方式。其中fast-catch-up用于实现leader和follwer之前的增量同步,一般在leader和follower的差别不是很大的时候。如何两者的差距比较大,就可能需要同步全量的数据。这个时候就使用 streaming- catch-up。那么如何确定可以OoO Apply呢?ParallelRaft这里使用的记录LBA的方式。Leader在commits一个log entry的时候,之后会将这个消息广播大其它的follwers。在Ack-Commit-Apply这样的操作步骤中,后面的apply操作ParallelRaft也不一定会是按照log entry的顺序apply的。OoO Apply也是基于一个范围内的log entry表示的操作之间没有冲突。如果没有冲突,按照什么样的顺序执行,可以得到一样的结果。这里检测冲突的方式就是记录LBA,因为这里面向FS。为了实现这个思路, ParallleRaft引入来一个look behind buffer,保存在每个log entry中。这个 look behind buffer保存了前面的N个log entry中会修改的LBA。N就是一个最大的能乱序apply的单元,这样带来的一个限制也就是log中的空洞不能大于这个N。Paper中这个N数值并不是很大。
... the follower can tell whether a log entry is conflicting, which means that the LBAs modified by this log entry are overlapping with some preceding but missing log entries. Log entries not conflicting with any other entry can be applied safely, otherwise they should be added to a pending list and replied after the missing entries are retrieved. According to our experience in PolarFS with RDMA network, N set to 2 is good enough for its I/O concurrency.
0x01 评估
这里的具体信息可以参看[1].
On the Parallels between Paxos and Raft, and how to Port Optimizations
0x20 基本内容
这篇paper讨论的是问题是使得Paxos和Raft更加相似,并提出了一个formal mapping,使得对于Paxos的一些优化可以移植到Raft上面。标题中的Parallels应该不是并行的意思。这里移植了Mencius 和 Paxos Quorum Lease两个特性到Raft。Paper中先总结了Paxos和Raft两个算法的基本核心的思路:
- 在Paxos中,phase-1的操作是一个结点选择一个globally unique proposal number (called ballot),然后向其它的server发送Prepare RPC请求。一个server在接受到这个请求之后,没有看到过更高的ballot的prepare请求返回成功。回复中带上其看到过的最大的ballot,没有看到过的话返回一个null。Proposing server收到半数以上的结点的成功回复的时候,进入第二步。负责选择更高的ballot重试操作。在第二步中,为之前prepare的ballot选择一个value,然后向其它结点发送Accept RPC请求。如果第一步其它的结点返回的数据中没有带上previously accepted value,这个value可以是任意的。如果有带上的,必须带上有回复中highest ballot最高的带上的value。一个server在收到这个Accept请求的时候,没有看到过更大的ballot的请求的时候,则接受。 Proposing server收到半数结点的回复接受之后,可以认为其打成了一致。可以在后面以其它方式将这个chosen(or equivalently, committed)的信息发送到其它结点。比如下一次请求的时候带上这个信息。MultiPaxos在Paxos上面改动而来,其可以在每个 position上使用一个paxos来完成操作,也可以并发批量地处理phase-1。这里描述的MultiPaxos中,没有一个类似于Leader的角色。一般MultiPaxos也没有限制只能有一个Leader来发想其它结点发送请求。但是在一般的实现中,会使用一个Master的角色来避免多个认为自己是主导致的冲突,这个Master和Raft的Leader有些类似。
- Raft中,核心的操作是通过复制log来完成达成一致的操作。两个核心的部分是 electing a leader 和 replicating of log entries。领导选举通过向其它结点发送RequestVote请求开始,每个server会维护一个term。能被选为leader的只能是包含了所有的可能已经提交log的结点。选举为leader的结点通过向其它结点发送AppendEntries请求来复制,接收到的server在term没有更大的情况下接受这个这个请求。同样地,leader在收到半数以上结点回复成功的时候可以认为其已经committed,在后面通过其它方式将这个消息发送到其它的结点。比如下一次请求 or 定期同步。

要想将Paxos的一些优化移植到Raft,需要一个Paxos上操作到Raft上面的映射关系。这里使用了refinement mapping的概念。但是Paxos和Raft之间是不能直接映射的,paper中总结了几个关键的原因:1. Raft要求followers被要求接受leader发送的AppendEntries请求。这里带来的一个效果就是leader强制要求follwers的结点的日志保存和自己的一致。这样才能让每个结点知道了committed的log entry,只会被commit唯一的值且每个结点知道的commit的值一致。这里带来的一个效果就是可以leader使得一些follower结点的日志被截断了。如果同意的操作发生在,MultiPaxos则可能会造成截掉已经accepted的值。Raft能过保证leader一定包含了所有的committed的log,所以Raft中截断的操作不会影响正确性。而Paoxs中,每个instance(对应到Rafe一个log entry)其commit操作是乱序的。为了处理这个问题,Paxos的方式是在回复的prepareOK的消息中,拉取其它没有提供instances的safe values(半数以上接受了),对应已经accepted的value,只可能覆盖写而不会移除。2. 另外的一个是Raft log entry中的term number不能直接映射到Paxos的ballot,原因是Raft中,leader不会更新已经存在的log entry。因此,Raft中一个新的leader会复制之前term中没有committed的log entry其它的结点,然后完成commit操作。这个操作在Paxos中没有对应的操作,Paxos的做法是覆盖写一个已经accepted的nstance的ballot number,重写为现在的ballot number。所有Raft写入数据的更像是一个append-only的log(可能会截断),而Paxos的这里称之为instances。
0x21 基本设计
这里提出的一个Raft的variant版本称之为Raft*。在Raft的接触之上改动了几个地方,如下图的伪代码所示。第一个改动是line 68,69,在回复RequestVote请求OK的时候,会带上超出了leader的log的部分。另外一个是在line77 – line81,增加了一个选择extraEnts中半数以上接受了的entry的信息。另外在line 110,append请求的时候,增加一个要求此结点的log不能比leader的要长。另外在entry中,增加了一个ballot字段,和Paxos类似,这里在AppendEntries中,leader会改写prev后面的log entires的ballot为目前的term。

增加了这些之后,Paxos到Raft之间的映射如下图。Paper中有比较详细的证明。对于将Paxos的优化移植到Raft,这里将其分为了几种类型,即增加的subaction,or 没有改到有直接对应的subactions,or 修改了的subactions。
• An added subaction. This is a subaction that has no relation-ships to existing subactions in A.
• An unchanged subaction. This is a subaction that is identical to an existing subaction in A.
• A modified subaction. This is a subaction derived from an existing subaction in A by adding extra conjunctive clauses.
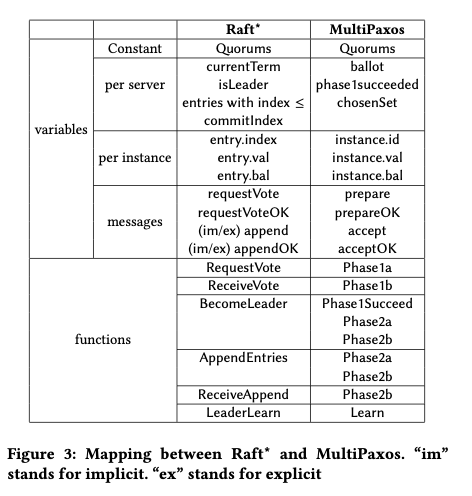
在此基础上的移植操作。以Paxos Quorum Lease为例,Paxos Quorum Lease的优化是优化读性能,避免只能从propsing server读取。其核心是一个租约,获取一些数据本地读的lease。更新这些数据的时候,需要通知到有这个租约的结点,同步不到的需要等待租约过期。这里移植搭配Raft的思路如下图。基本上就是commited对应到chosenSet,leader给出的leases对应到对应proposing servers。paper有具体证明。


Mencius,Mencius的优化是改善写的性能,使得其可以让每个结点轮流作为类似于一个leader的角色。其将 instance (log) space 用一个钟 round-robin的方式分配给每个结点。这里的主要改动是skip-tags的维护,因为轮到一个结点propose的时候其不一定有请求要发送,没有的话就需要skip。这里好像麻烦不少,在这篇Paper中也没有伪代码描述,而是在另外的一片extend version的paper中。
0x22 评估
这里可以具体参考[1].
参考
- PolarFS: An Ultra-low Latency and Failure Resilient Distributed File System for Shared Storage Cloud Database, VLDB ‘18.
- On the Parallels between Paxos and Raft, and how to Port Optimizations, PODC ‘19.
