Write Dependency Disentanglement with Horae
0x00 基本内容
这篇是OSDI ‘20上面一篇关于NVMe SSD上如何优化并发写入性能的文章,关注点是写入的顺序控制上面。一般的文件系统接口下面,其操作持久化/完成的顺序是乱序的,而且写入操作返回之后并不能保证数据已经只持久化了。为了处理顺序和持久化的问题,文件相同的fsync提了这样的功能,同时带有确定操作的顺序和确保数据已经持久化的功能。OptFS提出fynsc保护的顺序和持久化的两个语义和拆解,可以拆为数据持久化和确定数学两个分开的接口。还没的BarrierFS在这样的基础上提出了,提出了针对高速SSD优化的Barrier-Enabled IO stack。这篇Paper则关注在多个高速硬件的时候,如何充分发挥其性能。在多个设备的情况下,有顺序要求的写入由于写入顺序会导致性能随着硬件数量的增加提升不上去,而对于写入请求没有要求的,则可以比较充分发挥出硬件的性能。所以操作满足交换律还是比较好优化的[2]。

在目前Linux的系统,mq block layer的情况下,software queue可以对上层的请求进行合并、重新排序等操作。而在hardware queues这边,执行IO操作的指令的执行也是没有顺序保证的。目前解决这个问题的方式就是对于有顺序要求的,就是操作完成一个之后再去进行下一个,这样严重影响了性能。二BarrierIO的核心思路是让IO栈个层都可以告知到一个操作的顺序,使得这些操作可以并行的进行一些操作,同时完成操作的顺序有可以保持。而BarrierIO对于多个硬件的情况,其还是限制了多个硬件并发的性能。Horae的思路是数据流和控制流分开。对于数据流,其完全是无序的,二对于元数据的完成会给一个顺序上的保证。其关于操作顺序相关元数据持久化在前,而数据持久化在后。如果处理到中间crash的话,需要根据先持久化的元数据,如果有没有完成的操作,依赖于这个没有完成操作都需要进行会滚:
Moreover, Horae separates the ordering control from the data flow: the ordering layer translates the ordered data writes (1) into ordering metadata (2) plus the orderless data writes (3). The ordering metadata passes through a dedicated control path (MMIO). The orderless data writes flow through the original block layer and device driver (block IO) as usual.
0x02 基本设计
Horae IO Stack的价格如下图,其核心是在上层的FS、Store等应用和Block Layer之间,加入了一个Ordering Layer。Ordering Layer不需要处理所有的IO请求,只要处理有顺序要求的更新操作即可。Horae的ordering metadata保存在硬件中一个 persistent controller memory buffer结构中,这个是NVMe中新加入功能,比如可以通过NVMe设备中的CMB or PMR来实现。这里就将这个看作是一个设备中的可以持久化保存数据的内存。数据结构使用了一个ordering queue structure。这里引入了一个epoch的概念,将写入请求划分为一个组内没有intra-dependency的组。而with inter-dependency通过ordering queue structure来体现。
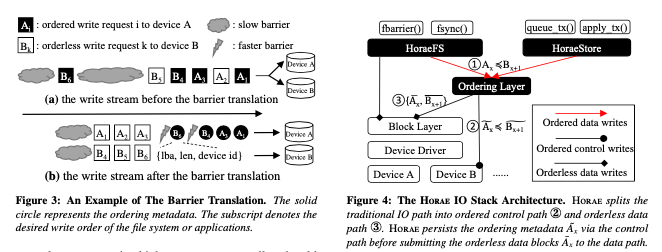
在顺序上,具体的做法是通过如下图所示的一个 Circular Ordering Queue。其顺序的指定有Ordering Layer完成。Ordering Layer会将操作之间的依赖关心翻译为一种顺序关系。比如将两个操作有A-x ≼ B-(x+1),表示A操作得在操作B之前完成,Ordering Layer将这个翻译为Am-x ≼ Bm-(x+1) ≼ {Ad-x, Bd(x+1)},即A操作的元数据先于B操作的元数据持久化,而A,B操作的数据写入部分是可以任意顺序。下面的这个数据会被保存到设备上的persistent Controller Memory Buffer (CMB)部分。Epoch来对操作分组的思路如下图所示,操作之间的依赖关系被转化为epoch的先后次序。在实现上, Circular Ordering Queue每个entry中会有一个byte来标示一个epoch的边界。硬件上面的CMD一般都不大,比如2MB左右。Horae通过将过大的数据swap到flash上面,及时将不在使用的数据回收来处理这个空间受限的问题。在持久化上,基本的指令是FLUSH command。一般的FLUSH操作也是有顺序语义和持久化语义两个部分。Horae则只作为持久化语义的FLUSH使用。这样带来的一个好处就是可以将多个FLUSH操作合并为一个,多个设备FLUSH的时候,可以并发进行。Horse需要FLUSH一个设备的时候,在这个设备之前操作顺序要求的设备也需要同时进行FLUSH操作。Horae会在元数据中记录下flushed position的信息,在FLUSH操作之后更新这个信息。Entry的元数据会保护这样的一些,
lba: logical block address. len: length of continuous data blocks. devid: destination device ID. etag: epoch boundary. dr: is made durable. plba: lba of prepare write. rsvd: reserved bits.
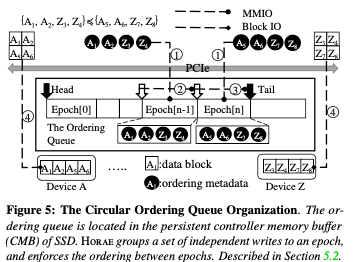
这里一个处理起来比较麻烦的问题是循环以来的问题,发生在in-place更新一个block的情况下。比如A3操作依赖于B2操作,B2操作又依赖于A1操作,而两个A操作都是操作了同一个块的数据,这样就会造成一个循环依赖,即在有 in-place updates (IPU)的情况下。这个解决这个问题的发生称之为write redirect,即将写入重定向到另外一个地方。实现的时候,IPU操作需要上层来告诉Horae操作是不是一个IPU操作。在接受到一个IPU操作的时候,显示一个Prepare write的操作,即先在preparatory area (p-area)分配一块空间。如果这个信息会被写入到entry元数据中的plba字段。后面的写入操作就是按照一般的方式写入到这个预分配的位置了。如何,Horae会使用一个radix tree记录一个Logical Block Address,lba到plba的映射。读取的时候需要读取这里的信息。Prepare write操作完成之后,需要通过Commit write来完成写入操作:先扫描ordering queue,发现p-area中overlapping的数据块,然后将这些数据库并发写入到原来的位置,然后radix tree中的数据会被删除。最后更新ordering queue的head 和 flushed pointer信息。
API Explanation
// block device interface
olayer_init_tream(sid, param) : Register an ordered write stream with ID sid and parameters param
olayer_submit_bio(bio, sid) : Submit an ordered block IO bio to stream sid
olayer_submit_bh(bh, op, opflags, sid) : Submit a buffer head bh to stream sid with specific flags opflags and op
olayer_submit_bio_ipu(bio, sid) : Submit an ordered in-place update block IO bio to stream sid
olayer_blkdev_issue_flush(bdev, gfp mask, error sector, sid) : Issue a joint FLUSH to device bdev and stream sid
// file system interfaces
fbarrier(fd) : Write the data blocks and file system metadata of file fd in order
fdatabarrier(fd) : Write the data blocks of file fd in order
// libaio interfaces
io setup(nr events, io ctx, sids) : Create an asynchronous I/O context io ctx and a set of streams sids
io submit order(io ctx, nr, iocb, sid): Write nr data blocks defined in iocb to stream sid
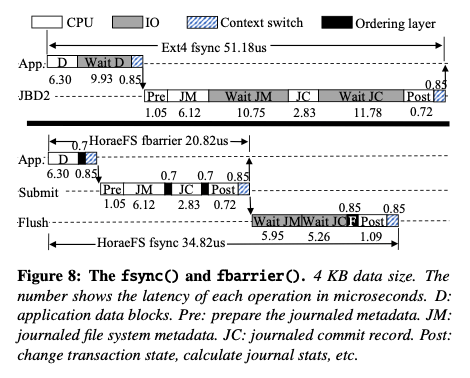
Horse提供的API如上所示,主要有kernel中的block device interface接口部分和file system interface已经aio接口几个部分。Paper中也在BarrierFS的基础上改了一个HoraeFS,表现了其优化效果。主要的改动是对有顺序要求的写入、读取要先发送到ordering layer,然后移除了一些FLUSH操作。另外就是IPU操作的处理。其操作流程和原ext4文件系统对比:D 表示data block,JM表示journaled metadata block,JC表示 journaled commit block。FS要求{D, JM } ≼ JC,即JC必须持久化在D和JM之前,而D和JM之间的顺序任意。Ext4的操作会需要等待D操作完成,然后写入JM,再等待JM操作完成,最近操作JC,等待JC操作完成。这样耗费超过50us。在HorseFS上,fsync这个流程变成了App发出写D的操作,然后进行Submit的时候发送写JM和jC的请求。航母就是等待JM和JC的完成。而对于fbarrier来说其不需要等待操作完成。
0x03 评估
这里的具体信息可以参看[1].
CrossFS: A Cross-layered Direct-Access File System
0x10 基本内容
这篇Paper的思路是提出一个跨越不同Layer的文件系统,保护用户空间,内核空间和硬件上面的几个部分,几个部分co-design来充分发挥系统的性能。其基本的架构设计如下。主要分为三层LibFS,FirmFS和OS Component三个部分,LibFS可以直接通过一个队列结构和FirmFS通信,消除了很多kernel带来的开销。这个三个组件主要处理的功能:
- User-space Library Component (LibFS),用户使用CrossFS通过LibFS来使用文件系统的接口,LibFS会将文件系统的操作转化为FirmFS I/O commands,即直接转化为FirmFS的操作指令。为了解决并发操作同一个文件带来的锁问题,这里引入了一个FD-Queue。每打开的一个文件的时候,LibFS会想Kernel申请创建一个FD-Queue,实际上就是神奇一个区域的一块内存(DMA’able memory region on NVM)。这个是因为现在的高速硬件可以支持上千上万的IO Queue,这样的方式可以利用好硬件的潜力。然后向FirmFS注册上这个分配的内存区域。如果没有block-level的操作冲突,后面的每个IO请求都会添加到file descriptor-specific FD-queue,存在block-level的冲突的时候,就需要将这些操作顺序地保存到同一个FD Queue。为了处理操作同一个inode的冲突,引入了一个per-inode interval tree,来实现一个range-based locking,只有操作同一个range的时候才会真的冲突,而不是lock整个inode,以此来降低lock的开销。
- Firmware File System Component (FirmFS),FirmFS从FD-Queue中获取应用发出的请求然后处理这些请求。FirmFS的结构和一般的文件系统没有太大的不同,基本也是superblock, bitmap blocks, 和 inode and data blocks这几个部分。另外FirmFS使用设备上面的一些空间来作为写日志的空间。这里一个特点是FirmFS将一些元数据保存到存储设备的DRAM中。
- OS Component,Kernel部分的主要是管理FD-Queue。负责相关的内存分配和回收,另外会处理一些访问权限的工作。在文件系统逻辑实现上面的作用比较少。

0x12 基本设计
Paper中花了比较大的篇幅来描述CrossFS的 file descriptor-based concurrency机制的设计。CrossFS为每个文件分配了一个IO Queue,称之为Per-File Descriptor I/O Queues,这个利用现在的NVMe设备最多可以支持64K个IO Queues的特性。并且为了利用好硬件的并行性能,CrossFS是每个Per-File Descriptor I/O Queue对应到一个硬件IO Queue。CrossFS中打开一个文件之后,通过ioctl syscall为这个打开的文件分配一个FD-queue (I/O request + data buffer)的空间,并且会将这个FD-queue的地址信息注册到FirmFS上。对于比较少见的打开的文件数量超过了64K的情况,需要一种IO Queue多路复用的机制,Paper中描述这里暂时还没有实现。在文件系统并发操作的语义中,要求读操作读取到最新更新的数据,而对于有冲突的写操作,必须是后操作的覆盖前面的操作。为了处理部分的时候实现细粒度的部分控制且满足文件系统并发操作的语义,这里使用了这样的一些方式:
-
有并发操作的时候,如果是多个线程,则使用主机的CPU来负责并发控制,而这个并发是在多个进程之间的时候,则利用FirmFS来文件,会利用到存储硬件上面的计算能力。将并发控制将给主机的CPU可以降低对计算能力比较弱的存储硬件的要求,这种方式在这里称之为host-delegated concurrency control。实现的方式CrossFS利用来Request Timestamp的机制,即在将一个请求添加到FD-queue的时候,LibFS会为每个请求添加一个全局的TSC-based timestamp。另外处理操作同个inode的冲突,引入了一个per-inode interval tree,实现为一个红黑树,使用操作的区间(low, high)作为key,
The interval tree’s timestamp (TSC) is checked for following cases: (1) for writes to identify conflicting updates to block(s) across different FD-queues; (2) for reads to fetch the latest uncommitted (in-transit) updates from an FD-queue; and (3) for file commits (fsync). The interval tree items are deleted after FD-queue entries are committed to the storage blocks - 对于一个写入请求,通过检查对应inode的interval tree来发现有冲突的写入操作,如上图所示的Op6和Op2操作,主要这里file descriptor级别的FD-queue和inode级别Interval-tree的区别。发现写入操作的冲突,通过将其转化为添加到FD-queue中的先后关系,来确定这些并发操作的顺序,它们会被添加到同一个FD-queue中。读操作可以查看Interval-tree发现有冲突的操作,二存在冲突的时候可以从FD-queue中获取数据。谢谢冲突的时候,还需要考虑是一个block的冲突还是多个blocks的冲突:对于并发的写操作只更新一个block的时候,后面的可以通过将前面的操作来设置为no-op的操作来实现操作的合并。而更新多个的blocks的时候则不能这么处理。而对于多个blocks的读取,需要interval tree中记录的更新区间都回去出来,以保证都读取到最新更新的数据。
- fsync在文件系统接口语义是,其返回成功的保证前面的操作都已经落盘了。而操作在CrossFS中由于一个实际的文件可能多个FD-queues原因,可能导致fsync添加到一个FD-queue的时候没有将另外queue中的操作持久化,违反了fsync的语义。Cross的解决方式是将fsync操作看作是一个barrier operation,会原子地添加到所有的FD-queues中。
- 另外一个并发操作的处理是关于元数据的。元数据更新会类似于fsync一样当做是一个barrier operation。对于mkdir这样的没有inode的操作,会使用一个全局的队列来处理。FirmFS处理没有依赖的请求的时候是乱序处理,而处理dir rename这样的请求需要操作的一个顺序。一种方式是通过在系统中所有的FD-queues添加一个 barrier request操作来保证操作的顺序。一种优化方式是添加到rename这样的操作添加到global queue,然后维护一个global barrier timestamps (barrier_TSC)。分发一个请求的时候设备的CPU检查 TSC 是否小于 barrier_TSC。如果不是的话,需要等待前面的操作完成。
Crash Consistency是文件系统设计和实现中一个处理起来很麻烦的部分,Paper中也简单描述了CrossFS处理Crash Consistency的思路。对于FD-queue的Crash Consistency,主要思路是通过Persistent Memory。CrossFS将FD-queues的数据保存到Persistent Memory上,使用append-only的方式写入。一个请求添加到FD-queue之后,会添加一个commit flag。故障恢复通过将没有commit flag请求丢弃。没有Persistent Memory的时候就直接使用DRAM保存FD-queue的数据,这样没有committed的数据是可能丢失的,这个也符合现在文件系统的语义。FirmFS的Crash Consistency则主要还是通过日志的方式来实现。
0x13 评估
这里的具体信息可以参看[5].
参考
- Write Dependency Disentanglement with Horar, OSDI ‘20.
- Optimistic Crash Consistency, SOSP ‘13.
- Barrier Enabled IO Stack for Flash Storage, FAST ‘18.
- The scalable commutativity rule: Designing scalable software for multicore processors, SOSP ‘13.
- CrossFS: A Cross-layered Direct-Access File System, OSDI ‘20.
