Overload Control for μs-Scale RPCs with Breakwater
0x00 基本思路
这篇Paper主要是关于RPC做Overload Control的思路。Breakwater的基本思路是一种server-driven admission control的方式,client只有在收到server的credits的情况下才能向server发送请求。对于server来说,它使用排队延迟来作为一个overload的判断。在Breakwater之前,场景的overload control方式有这样的一些策略:一个是Active Queue Management (AQM),Control的组件作为一个 circuit breakers运行在server端 or 另外的一个 proxy,其使用的策略可以是限制server正在处理的请求的数量。这种方式的一个缺点是即使一些请求被拒绝,还是会造成server的一些开销;另外的一种方式是Client-side Rate limiting,使用某种策略来限制client发送请求的速率,client端通过deplay等信息来判断server的处理能力,避免让server过载。Client端控制的方式在client数量很多的时候处理并不是很好。另外的一些方式是结合这两种方式。Breakwater提出的对Overload Control的要求是:
1. Short average service times;
2. Variability in service times;
3. Variability in demand;
4. Large numbers of clients;
基于上面的思考和对Overload Control要求的总结,Breakwater的思路是:
1. Explicit server-based admission control, client只有在收到server给的credit的时候才能发送请求。即显式的server-based admission control;
2. Demand speculation with overcommitment, server也会预测client的请求,可以让server发送overcommit的credit给client,降低client请求credit等动作的开销;
3. AQM,由于overcommit的存在,server可能在一些情况下请求是超出了其处理能力的。这种情况下引入了AQM来处理;
0x01 方案
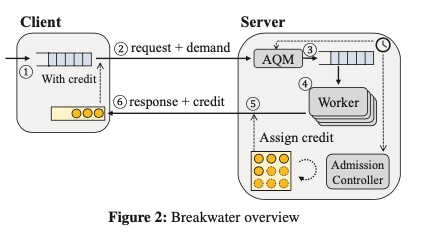
Breakwater的基本架构如下图。一个client加入的时候,需要向server注册,并带上在其queue中排队请求的数量。Sever在收到这个加入的请求的时候,将其加入到client list中,在没有overload的情况下执行这个请求,回复client结果 or 错误信息,并会带上credits的信息。这个credits的数量由client的需要(和server目前的情况?)决定。Client不在发送请求的时候,需要向server解除注册,并归还没有使用的credits。在这种模式下面,Breakwater的核心是三个部分:
-
Overload Detection,过载的探测。这里不使用CPU利用率来判断,但是CPU利用率只是一个单一的指标,另外的策略是使用排队长度。但是这里认为queuing delay是一个更好的指标。Breakwater使用两个queue来记录packet层面和thread层面的排队delay,通过记录目前的时候和最近的enqueue时间来判断排队的延迟,
... for every queue in the system, each item (e.g., a packet or a thread) is timestamped when it is enqueued. Each queue maintains the oldest timestamp of enqueued elements in a shared memory region, and this timestamp is updated on every dequeue. When the delay of a queue needs to be calculated, Breakwater computes it by taking the difference between the current time and the queue’s oldest timestamp.这样的策略是追踪整体的queue delay而不是记录当个请求的排队时间。
-
Overload Control,Overload Control包含了Server-driven Credit-based Admission Control、Demand Speculation with Overcommitment和AQM几个部分。其中Server-driven Credit-based Admission Control,Server维护来一个global pool of credits (C-total ),表示来server在保存目标SLO的情况下能处理的请求数量。这个C-total有目标的queue delay d-t,和目前测量到的的queue delay d-m来动态计算而来。对于每个RTT,如果测量到的d-m小于d-t,则其根据加性增的策略来增加C-total,负责根据乘性减的策略来减少C-total。这个策略和TCP Congestion Control的策略是类似的, \(\\ C_{total} = C_{total} + \alpha, if\ d_m < d_t \\ C_{total} = C_{total}\cdot\max(1.0 -\beta\cdot\frac{d_m-d_t}{d_t}, 0.5), else. \\\) C-total计算出之后,credits被分发给clients,如果C-tatol在后面增加,则通过在client的请求的response中稍带给client。如果C-total减少了,则通过在client的请求的response中稍带一个负数的credits来撤销之前给的。
-
Demand Speculation with Overcommitment,这部分决定了server给一个client的credits的数量。Breakwater通过client在请求中带上起demand来降低回去credits带来的额外开销,server回复的时候也是在response带上返回的redits。Server分发credis的时候,如果按照起能力分发,由于client不会立即使用,则可能使得server处理under utilization的情况。为了解决这个问题,这里使用的策略是Overcommitment。Server回去推测一个client的需求。Client可以获取其最后的damand请求更多的credis,这个overcommitment数量根据client的数量C-oc和C-total的大小和client可能请求credits的数量C-issue来决定。Overcommitment通过设置前面的alpha、beta参数来实现。这里alpha为前面C-total计算中的alpha,a为一个参数,n-c为client数量。 \(\\ \alpha = max(a\cdot n_c,1). \\ C_{oc} = \max(\frac{C_{total}-C_{issued}}{n_c},1). \\\) Server控制每个客户端没有使用credis不超过它最后的demand加上C-oc,超过的时候通过其撤销机制来撤销多发的。二AQM是为了处理overcommitment导致的server可能overload的问题。
0x02 评估
这里的具体信息可以参看[1].
μTune: Auto-Tuned Threading for OLDI Microservices
0x10 基本内容
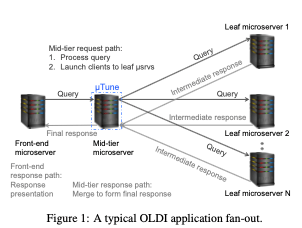
这篇Paper讨论的是RPC中的Threading Models。这里关注的是On-Line Data Intensive (OLDI)类型的微服务,即在线数据密集型应用?一般来说RPC实现会有异步、同步,Inline、Dispatch-Based等不同的实现策略,这里总结出这些策略并提出了一个μTune的框架给了这些策略一个很好的抽象,另外可以自适应地选择不同的Model,以优化尾延迟。这里关注的场景类似于下图所示的。关注的是存在多个微服务的系统中,mid-tier部分的策略设计。这里先将策略范围这几个不同的方向,
- Synchronous vs. asynchronous,同步和异步。同步的方式在编程上来说会简单一些,异步的方式会麻烦一些。在性能方面,同步的方式需要处理request/response排队、cache pollution、lock contention, 以及 scheduling/thread wakeup delays等的问题,在延迟和吞吐上来说都会比异步的占一些劣势。
- In-line vs. dispatch-based,Inline-based的方式是指一个线程处理一个RPC全部的过程,保护发送到接受返回。而 Dispatch-based模式下RPC不同的步骤可能由不同的线程来处理。从编程上来说,Inline-based的方式更加简单。性能上来说,Inline-based的方式避免了一些work的转移操作,在load比较低、请求是比较短的请求时候更有效率。在load比较高的时候,dispatch-based可以有更好的处理方式。
- Block- vs. poll-based。Pool的方式会带来更低的延迟,也会导致更高的CPU消耗。
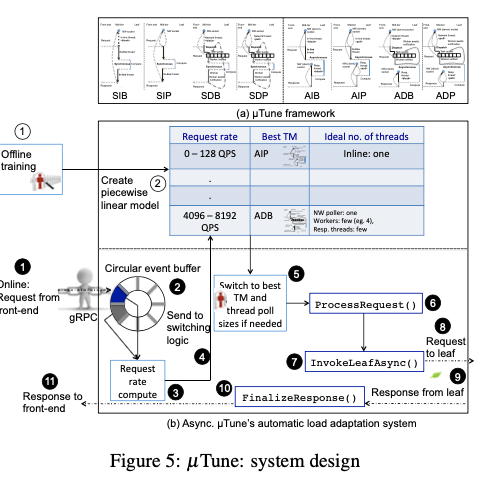
在上面的基础之上,这里将使用的RPC分为这样的几种:1. 同步的,Synchronous In-line Block (SIB),Synchronous In-line Poll (SIP),Synchronous Dispatch Block (SDB),Synchronous Dispatch Poll (SDP);2. 异步的:Asynchronous In-line Block (AIB),Asynchronous In-line Poll (AIP),Asynchronous Dispatch Block (ADB),Asynchronous Dispatch Poll (ADP)。
0x11 基本设计
μTune的基本设计如下图。μTune想要实现简单的接口抽象、快速的load shift监测、自适应的threading model切换和 调整 thread pools但是又要避免thread creation, deletion, or management overheads等。对于同步和异步的请求,都是使用其ProcessRequest接口,可能inline or dispatch的方式处理这个请求。ProcessRequest内部会根据时同步还是异步来调用不同的实现。ProcessRequest接口对于调用多个Leaf的情况时,其会将结果合并之后返回。对于异步的情况,最后一个返回的会调用FinalizeResponse。μTune还要实现的一个关键功能是如何在不同的模式下切换。
-
异步和同步的模式的不同点太到了,在同样的代码下面实现在异步和同步模式下的动态切换太麻烦了。这里使用的方式就是如果有一个异步的版本,这里可以得出其同步的一个版本。也就是说这里两种还是分离的,
... it is not possible to switch automatically and dynamically between synchronous and asynchronous modes, as their API and application code requirements necessarily differ. If an asynchronous implementation is available, it will outperform its synchronous counterpart. So, we build μTune’s adaption separately for synchronous and asynchronous models. -
μTune的目标是优化PCT99的延迟,这里如何训练μTune来适应目前的workload的方式如下图。下面表示的应该是异步的版本。在Training阶段,使用一个模拟的load generator来在一个指定的时间段内,生成一个特点的负载。这个步骤中,会测试调整thread pool和threading model ,并测量它的PCT99。测量完成一个负载水平之后,重新测试下一个。如何从这些测量数据中得出一个 piece-wise linear model,分段线性模型。
-
Runtime adaptation。在运行的时候,使用 event-based windowing的方式来测量其实际的PCT99延迟。对于每个请求,会在一个Circular Event Buffer中记录一个到达时间,然后根据这个里面最早和最晚到达的timestamp来计算一个 inter-arrival rate。然后根据这个 inter-arrival rate和前面的到的 piece-wise linear model得出一个使得PCT99最低的模式。如何目前的模式不是最佳的,可以选择进行模式的切换,
μTune transitions by “parking” the current threading model and “unparking” the newly selected model using its framework abstraction and condition variable signaling, to (a) alternate between poll/block socket reception, (b) process requests inline or via predefined task queues that dispatch requests to workers, or (c) park/unpark various thread pools’ threads to handle new requests.
0x12 评估
这里的具体信息可以参看[2].
参考
- Overload Control for μs-Scale RPCs with Breakwater, OSDI ‘20.
- μTune: Auto-Tuned Threading for OLDI Microservices, OSDI ‘18.
