Ambry: LinkedIn’s Scalable Geo-Distributed Object Store
0x00 基本内容
这篇Paper是关于LinkedIn的对象存储系统Ambry的设计,其基本价格如下图所示,其基本架构和Facebook的Haystack类似,存储也是使用100GB一个大文件,里面保存多个blob。对于上传的很大的对象,也会对其进行拆分,拆分为chunk,每个chunk对象大小在4-8MB左右。每个chunk就类似于一个blob的方式保存到相同中,同样的为了记录下一个blob为拆分为那些blob,Ambry会创建另外的一个b-metadata的blob,记录下这个信息,这个metadata又作为一个blob保存代系统中。同样为了定位一个partition中的一个blob,也适用来本地的一个index。这些没啥特别的。
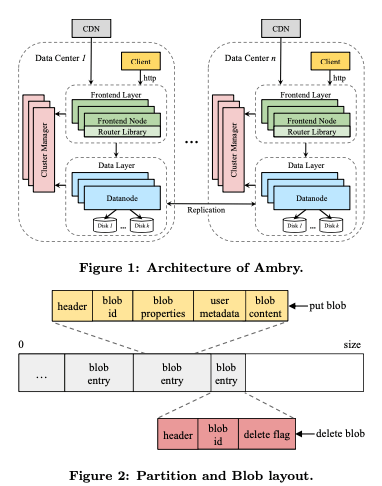
Paper中对其复制有详细一点的讲解。Ambry复制利用了一般这种类型的系统append-only写入,不会修改的特点。使用多点并发写入的方式,而不用care并发写入带来的同样的blob数据不一致的问题,而blob保存在不同副本上面的位置不同,则利用每个副本的index来各自定位。这样多副本并发写入的方式,对降低延迟又比较好的效果。而对于跨地理区域复制的情况,使用异步复制的方式。比如写入3个副本,2个ACK就能返回的话。需要处理GET的时候读取到最近写入到问题,这里的处理方式也就是一个没有GET到的时候请求另外的副本即可。这样每个副本上面的数据不一定是完全一致的。为了处理这个问题,Ambry的方式是每个副本之间周期性同步数据的方式,为了记录下来最近写入一个partition的数据,Ambry使用一个内存中的日志。记录下根据其在partition保存的offset排序的blob。同步操作的时候,第一步根据这些信息发现从最近一次同步点依赖的,副本自己缺失写入的数据,第二步操作就是同步到本结点。对于负载均衡,Ambry使用了2中不同的策略:
-
Static Cluster,即将大的blob拆分,然后随机选举partition保存的方式。
-
Dynamic Cluster,在这里定义了3个ideal state,(idealRW, idealRO, idealUsed),表示 ideal number of read-write partitions, ideal number of read-only partitions 以及ideal disk usage each disk。这个值通过总的请求的量除以磁盘数量得到。算法的基本思路是第一步大于ideal值的,加入到一个pool中。然后将其移入到低于ideal的磁盘中。移入的基本方式是创建一个新的副本然后删除之前副本的方式。
// Compute ideal state. idealRW=totalNumRW / numDisks idealRO=totalNumRO / numDisks idealUsed=totalUsed / numDisks // Phase1: move extra partitions into a partition pool. partitionPool = {} for each disk d do // Move extra read-write partitions. while d.NumRW > idealRW do partitionPool += chooseMinimumUsedRW(d) // Move extra read-only partitions. while d.NumRO > idealRO & d.used > idealUsed do partitionPool += chooseRandomRO(d) // Phase2: Move partitions to disks needing partitions. placePartitions(read-write) placePartitions(read-only) function placePartitions(Type t) while partitionPool contains partitions type t do D=shuffleDisksBelowIdeal() for disk d in D and partition p in pool do d.addPartition(p) partitionPool.remove(p)
0x01 评估
这里的具体内容可以参考[1].
Object Storage on CRAQ – High-throughput chain replication for read-mostly workloads
0x10 基本思路
这篇Paper是关于在Object Storage一种复制方案的设计,其基本思路是使用chain replication的方式去设计。CRAQ支持get,put这样简单的接口,支持强一致性和最终一致性。其基本思路如下图。CRAQ处理复制的方式是每次从chian的head写入,然后通过这个chain去replication。写入到最后一个node完成之后,即写入完成,称之为committed。即最后一个写入结点没有完成之前,写入都是没有完成的。CRAQ中一个object是可能被多次更新了,所以其保存了一个object的多个版本。这样就带来了几个需要解决的问题。
- 读取的话,如果总是读取tail的数据,就可以保证读取到的总是committed的数据。但是就一些副本就利用不上了。如果可以读取任意副本的话,就会有可能读取到没有committed的数据的问题。这里的结局方式是在数据保存了多个版本之后,tail之前的副本先将这个版本标记为dirty,然后复制到后面的结点。而tail结点在复制完成之后标记为这个版本为clean,然后将这个clean的信息向前传递。
- 如果读取的时候一个object的最后一个版本是clean的,则直接返回。如果遇到了一个dirty的版本,则这个结点会想tail询问最新的一个clean的版本。
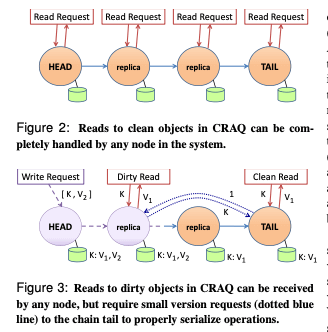
这样的设计看起来是一种不是行得通的设计。写入延迟,crash处理,网络分区处理都会有很多麻烦的问题。
0x11 评估
这里的具体内容可以参考[2].
Pelican: A building block for exascale cold data storage
0x20 基本思路
这篇Paper比前面两篇显然要有意思一些。显然现在的数据量已非常快的速度增长,但是大部分的数据只是在其诞生之后的一段时间会有一些访问,大部分的数据是诞生一段时间之后就几乎不会就有机会访问了。也就是现实中大部分的数据是冷数据。而这篇Paper给出了一个为cold data设计的一个存储系统,其核心点事使用高密度的存储之外,还使得一般情况下只有8%的磁盘处于工作的状态,而其它的处于休眠的状态以节省电力。Pelican使用的rack组织如下,每个1152个磁盘的高密度设计,16个磁盘一个tray,一个chassis有12个trays,一共有6个chassis。这样总共就是1152个磁盘(6 (width) x 16 (depth) x 12 (height)),这样类似一个方体的结果。每个行事一个powe domain,每个列是一个cooling domain。而电力支持能够支持启动72个trays,但是每个只能启动2个磁盘,即144个。而冷却来说,测试16*6=96个cooling domain,每个domain支持启动一个磁盘,就是96个。Power domain个cooling domian使用交叉的方式布置看上去也主要是启动一个满足启动一个power domain的时候对冷却的要求能不超过一个cooling domain的能力。
A tray is an independent power domain. Due to the nature of power distribution, and the use of electronic fuses, we provision the system to support a symmetrical power draw across all trays. In-rack cool- ing uses multiple forced air flow channels, each cooling a section of multiple trays, the cooling domain. Each air flow is shared by 12 disks. There are 96 independent cooling domains in the rack, and each is currently cali- brated to support cooling only one active or spinning up disk.
另外一个是带宽的特性,实现40Gpbs的带宽需要大搞需要50个左右工作的磁盘。所以96个可以满足处理一些请求的同时启动另外一些来为后面的请求做准备。每个 tray的磁盘连接到一个Host Bus Adapter (HBA),这个HBA连接一个PICe Switch,用来连接serve。通过在一个物理的switch上面虚拟出两个的virtual switch,每个HBA连接到两个虚拟switch中的一个,而每个root port连接到两个server中的一个。Chassis维度,6个都连接到了两个server。一般情况下rack被垂直地分为没有共享cooling domain和power domain的两个部分,这样每个server就独立地处理两个部分的一个。如果一个server出现故障的话,另外一个可以接替故障server的工作。这样系统中的 servers, chassis, trays 以及disks都是不同纬度的failure domain。

0x21 Pelican Software Storage Stack
这上面描述的这样的物理rack的设计上面,软件战也需要进行对应的设计。这里Pelican先定义了一个resource domains的概念,即同时提供一类资源的一个磁盘的subset,这个resource可以是多种的。如果不同的disks之间有某种共同的resource,即处于某个共同的resource domain,即它们是domain-conflicting的,没有的话则称之为是domain-disjoint。而domain-disjoint关系的不同磁盘其状态转化是单独处理的,而domain-conflicting关系的必须同时转化状态,比如必须同时由休眠转化为活跃。系统会保证任何的resource都不会被超额使用。这样在系统运行的时候,会给系统施加一个resource domains上面的限制,这里Pelican对这样的限制进行了分类: hard限制,soft限制。hard限制的违反会导致短期内or长期内的故障,而soft的限制违反性能的降低,资源利用不充分的。比如power和cooling为hard限制,而bandwidth(PCIe等的)限制为soft限制。这样Pelican软件栈设计的时候,想要满足:
The Pelican storage stack uses the following constraints:
(i) one disk spinning or spinning up per cooling domain;
(ii) two disks spinning or spinning up per power domain;
(iii) shared links in the PCIe interconnect hierarchy; and
(iv) disks located back-to-back in a tray share a vibration domain.
数据保存的时候以blob的方式保存,被拆分为128KB的fragments,以15+3的EC编码方式保存。这样增加的空间开销也不多,而读取一个较大blob的时候也能得到比较大的带宽。另外一个好处是保存这个fragments的磁盘不能同时处于工作状态的时候,可以通过EC重建的方式得到初始的数据。软件系统实现的时候,希望最大化能够并发处理请求的数量,有能够满足Pelican的这些限制。考虑如下的场景:
- 对于一个磁盘的几个S-a和另外一个集合S-b,如果两个集合的磁盘中存在domain-conflicting的磁盘,则在两个集合上面的操作只能是串形的,而为domain-disjoint的话,操作可以是并发操作的。对于一个简单的贪心算法:1152个磁盘组织为一个列表,每次随机从其中选择一个磁盘,然后和这个磁盘有domain-conflict的从这个list中移除,然后重复操作,知道选择了18个磁盘。这样的算法的问题在于其冲突的可能性太高,为冲突的概率和磁盘数量的平方有关系。另外一个是可能的选择的集合数量太多了,要从1152中选择合适的18个。
处理这样问题的一个思路就是分组,Pelican的思路是将磁盘分为l个group,在同一个group的磁盘都是domain-disjoint的,可以同时处于工作状态。冲突情况变成要考虑l的平方组合的冲突情况。另外这里继续选择两个groups里面,一个group中一个磁盘和另外一个group中一个磁盘有conflict,则认为和所有的磁盘有conflict,目的是使的两个group要么是完全conflict/colliding的,要么是完全disjoint的。Pelican分组的方式如下图所示。其一个group的数量根据cooling domain的数量来决定。图中黑色的斜线为一个group,红色虚线为另外的一个group。其怎么分组的策略从其中就可以看出来的。这两个group是存在冲突的,所有两个group不能同时启动。这样这里实际上有12个mutually-colliding的groups,这里将这样mutually-colliding的groups的集合称之为class。也就是说一个class里面,一个时刻只能有一个group处于工作的状态。而paper中选择的group size为24,这样大于15+3,而且可以容忍24个磁盘有有一些故障了还能选出18个磁盘来写入数据。这样l的数量为48,分为4个classes,每个class独立处理工作。而准备写入一个blob的时候,会从24个中选择18个, 选择的方式会考虑到failure domain,比如backplane failure domain。保存在那些磁盘的元数据会保存到另外的一个地方。

在这样的设计下面,如何调度IO请求也是一个问题,其延迟会明显比一般的存储栈要高。一个简单的思路是将padding的请求根据class进行reorder,同一个class里面的请求尽量同时处理。对于HDD的磁盘,操作系统的IO调度器也会对其进行reorder,这个优化可以表述为c-d(h-l,IO-1,IO-2) != c-d(h-l,IO-2,IO-1),即磁头在h-l位置的时候,以不同顺序执行两个IO请求的开销不一样。而这里将其cost function表述为 c-p(g-a,IO-g),这里g-a表示目前处于工作状态的group,而IO-g表示IO操作在的group,如果g-a和g相同,则c-p的值为0,负责为1。对于这里的IO调度器的设计,主要是要解决最大化性能的问题,和保持搞好可靠性的问题。这里引入了request reordering 和rate limiting两种思路,并对于rebuild的IO请求和一般的IO请求分为两个请求队列:
- 每个队列,其请求的reorder操作都是独立进行的,简单直观的一个思路是让同一个group里面的请求都排列在一起,然后执行。但是也可能导致让其它的一些请求delay、饥饿的问题。其reorder的基本思路是:对于每来一个请求,记录下一个计数值,另外记录一个reorder的计数值。添加到队列中间的时候,这里会使得两个时间戳的差不超过一定的值。即在队列往前面参展在相同group里的请求,如果没有相同的则直接添加到最后。如果有相同的另外一个请求l,这个l后面的任意请求i不满足o-i +1−t-i ≤ u,则目前进来的请求还是添加到最后面,负责这个l后面的请求去哦o-i值都增加1,添加的请求插入到l后面,且其记录为o-r = t-r − |i|,|i|为l后面请求的数量。对与u=0的特殊情况,这个时候就相当于FIFO,而u为无穷大的时候,则为尽可能增加吞吐的方式。
- 另外一个为rate limiting,对于两个队列,通过一种weighted fair queuing的算法,来分享带宽,降低一些相互影响。
0x22 评估
这里的具体内容可以参考[3].
参考
- Ambry: LinkedIn’s Scalable Geo-Distributed Object Store, SIGMOD ‘16.
- Object Storage on CRAQ – High-throughput chain replication for read-mostly workloads, ATC ‘09.
- Pelican: A building block for exascale cold data storage, OSDI ‘14.
