Spanner: Becoming a SQL System
0x00 基本内容
这篇Paper是关于Spanner的第二篇Paper,应该是也是比较有名的了。这篇主要的内容是关于Spanner在SQL方面的进化。Spanner开始的时候更像是一个Key-Value的系统,支持SQL。而现在更像是体格关系型数据库系统。在SQL的执行中,query compiler会先将SQL查询编译为一个relational algebra tree,即SQL查询的一个tree的表示,然后根据schema和数据的一些特性来对查询进行重写,使之成为一个更加有效率的执行方案。这里的重写Paper中描述的是通过transformation rules,所以看来是一种rule-based的方式。比如常见的优化方式如谓词下推,使用索引,字查询消除等。查询计划会有一个cache,对于相同模式的查询可以避免重新编译。Query Complier会用到很多的 correlated join operators操作,包括查询优化里面的algebraic transformation,以及一些physical operators。Spanner中将logical operators分为两种类型,CrossApply和OuterApply。CrossApply签名类似于CrossApply(input, map) 的操作,类似于函数式编程的map,而OuterApply(input, map)也是将map作用到input中每一个tuple上,但是不会有map的输出。由于是分布式的数据库,查询编译器生产的查询计划会包含在remote servers上面执行的subplan,还包括将每个shard的结构聚合的部分。这里就涉及到Spanner的分布式查询。
0x01 Query Distribution
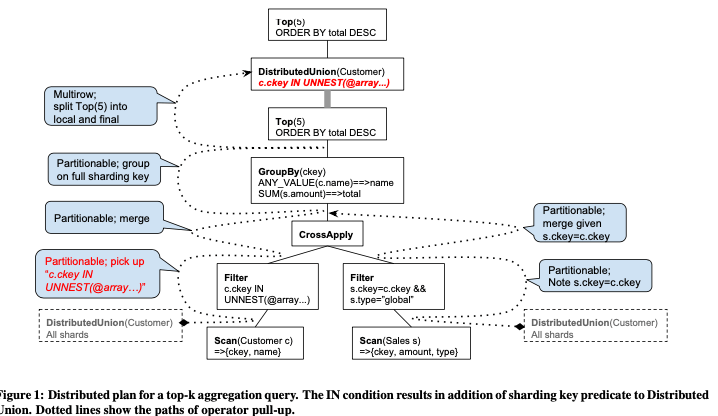
前面简单地提到Spanner的执行模式。考虑到Spanner的分布式环境,其很多查询结果是每个shard查询的和。这样就引入了Spanner的一个分布式operator,称之为Distributed Union,即实现将每个部分的结果汇总。这个Distributed Union是一个很核心的operator,用在查询进行的时候,也包含在查询restart的时候。比如一个分布式的scan,可以表示为Scan(T) ⇒ DistributedUnion[shard ⊆ T](Scan(shard))。为了优化执行的性能,Spanner会尝试就可能地将Distributed Union放在relational algebra operator tree的更高的位置,也就是说尽可能的将其它的一些operators放到每个每个分区上面进行。达到类似于一个算子下推的效果。当然这样就要求这些下推的operators在每个部分执行在聚合和聚合之后在执行最终得到的结果是一样的,Paper中将满足这种特性称之为partitionability。Join操作很多时候不能满足这个partiitonability,但是Spanner支持一个table interleaving的特性,即将不同的tables(sharing a prefix of primary keys)的数据,交叉地保存。在这样的保存方式在进行一些join操作的时候,同样也可以使用operators下推然后进行Distributed Union。有些这样的可以使用Distributed Union是通过multi stage的方式实现的,比如一些Top操作和一些Group By操作。这样的操作下相当于将查询重写,Op(DistributedUnion[shard ⊆ T](F(Scan(shard)))) = OpFinal(DistributedUnion[shard ⊆ T](OpLocal(F(Scan(shard))))。Paper中以下面的SQL查询语句为例,
SELECT ANY_VALUE(c.name) name, SUM(s.amount) total
FROM Customer c JOIN Sales s ON c.ckey=s.ckey
WHERE s.type = ’global’ AND c.ckey IN UNNEST(@customer_key_arr)
GROUP BY c.ckey
ORDER BY total DESC
LIMIT 5
这个查询包含了Grou By,Order By和Top以及Join等的操作。会被编译为如下的查询计划。这里Customer表和Sales表使用interleaving的方式保存,其shared key为ckey。最朴素的是将所有的数据都scan,然后聚合处理。这个通过多种的方式将其它的operators下推,而最终的Distributed Union只需要在每个shard的结果取Top即可。使得操作更加接近数据,提高性能。同时查询处理的时候,Spanner的coprocessor framework会将subquery路由到最近的一个副本来处理,降低延迟。在查询的时候,Spanner会尝试先将无关的shards先从查询中剔除掉。由于Spanner一般面向的是OLTP的workload,很多时候将shard踢出之后就剩下了一个。如果从filter expression获取的key range覆盖了整个的table的话,则查询计划可能会做相应的调整。比如将call每个shard优化为call每个server。另外Spanner发送subquries的时候通过并发请求的方式,并发操作。为了降低不同查询的相互影响,这里会需要一个并发度的限制,而对于large shards的查询,也可以通过拆分为sub-shards的方式来将其并发处理。另外一些情况下,一个库的数据并不多,可能一个副本就保存在一台机器上面。这样 Distributed Union在发现数据都在一台机器上面之后,这样就可以直接本地处理,而不用引入分布式的逻辑。
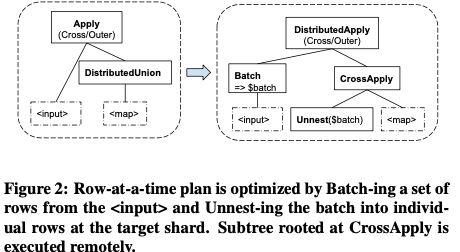
对于independently distributed tables,应该指的是不能使用interleaving特性的tables。基本的优化思路是batched apply join,即批量处理。对于Apply Join, Cross Join, 以及 Nested Loop Join这样的操作,朴素的实现会引入对于每一行的数据产生一个rpc的操作。为了优化这个Spanner引入了一种Distributed Apply operator,是Distributed Union operator的一种拓展。基本的思路就是批量处理。其聚合了Cross Apply 或者是 Outer Apply 加Distributed Union的功能。
Spanner提供两种类似的Query distribution APIs,Single-consumer API值需要发送到一个server,称之为root server,然后这个root server来处理请求。Spanner会在client端cache一个location hint。如果是对于涉及到少量数据的,可以直接通过location hint发送到数据所在的机器,来实现更佳的延迟。对于如下的查询,可以直接发送的@t orindexed_col对于区间所在的机器。
SELECT p.*,
ARRAY(SELECT AS STRUCT c.* FROM Child AS c WHERE c.pkey = p.key)
FROM Parent AS p WHERE p.key = @t
SELECT p.* FROM Index AS i
JOIN Parent AS p ON p.key = i.foreign_key
WHERE i.indexed_col BETWEEN @start AND @end
而Parallel-consumer API在查询结果比较大的情况下使用,同时发送到多个servers,这些servers并发处理查询请求。Spanner使用2-stage的方式来处理将工作分配到多个clients。第一步是将工作分割。Parallel-consumer API在接受到查询请求的时候,以及其需要并发处理的并发度信息,然后会给出若干的opaque query partition descriptors,第二步操作为在每个partition上执行查询。这样的请求要求是root partitionable的。
0x02 Query Range Extraction
Range涉及到一个查询会请求到那些的shards。Spanner本身就是一个range分区的相同,但是为了更好地支持查询,过滤一个查询不要涉及到的分区。Spanner还引入了一个Query Range Extraction。对于Range Extraction,Spanner将其分为几种类型:1. distributed range extraction,即那些table shards会涉及到一个查询;2. seek range extraction,一个shard的那些fragments会与一个查询相关;3. lock range extraction,对于pessimistic事务,为一个table的fragments被加锁了,对于snapshot事务,为那些会有pending的修改。Lock range extortion主要是降低锁的粒度,来提高并发性。以如下的查询为例,其index的columns为(ProjectId, DocumentPath, Timestamp)
SELECT d.*
FROM Documents d
WHERE d.ProjectId = @param1
AND STARTS_WITH(d.DocumentPath, ’/proposals’) AND d.Version = @param2
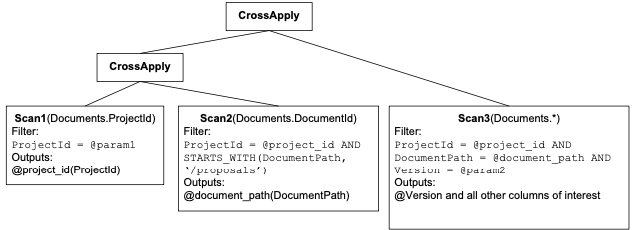
对于参数为 ‘P001’ 和 ‘2017-01-01’的情况,根据第一个参数就可以获取其在那一个shard。根据第二、三个参数使用seek range extortion,可以获取定位到更精确的数据位置。而对于加锁,这个使用(P001, /proposals),即涉及到的数据的一个prefix,也是一个要求的最小的key range。对于这个tables上面这个查询,其range extraction可以其index的几个columns数据的prefix相关。为了实现range extraction,Spanner在编译时和运行时的两种机制,编译时会将代谓词的scan(filter scan)重写为correlated self-joins,而在运行时候利用了filter tree结构。
-
重写为self-join类似于下图。所示的为上面的Documents表的查询。where中的三个条件为重写为三个部分scan操作,其结果为三个部分的self-join操作而来。第一个部分可以直接根据第一个参数定位到key ranges,而不用实际的scan操作。第2个scan会利用到第1个scan的结果,而第3个会利用到前面2个scan的结果。Scan2可以在发现满足第二个谓词的条件的第一个数据后,寻找下一个可以直接跳到下一个。也就是跳过了第一个数据的其它的version。第3个需要需要在前面的数据中过滤处理啊满足所有条件的数据。另外一些在编译时候处理的重写比如将NOT下推到最后层次的谓词,即leaf predicate。大小比较则如1 > k -> k < 1,NOT(k > 1) -> k <=1这样的形式。查询的的interval如果比较小,则直接解析出来,比如between 5 and 7变成(5,6,7)等。
-
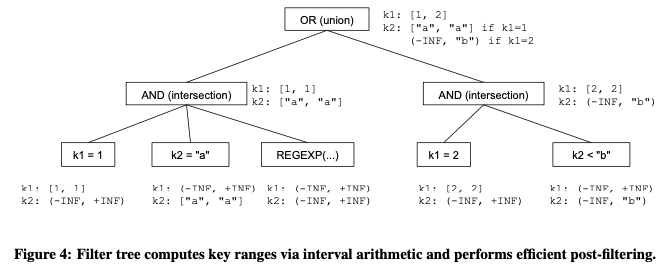
Filter Tree则可以处理更加复制的where条件。Filter Tree为一个运行时的结构,通过自底向上的方式构建key ranges。如下图所示,range extraction通过自底向上,最下的每次作用在一个column上面。对于没有明确访问的,表示为一个无穷的访问。然后就是向上的AND和OR操作。AND为选择条件都复合的部分,OR为符合条件之一的部分。
为了处理查询过程中的故障,Spanner引入了query restart的机制。这样会给用户带来很多方便,比如自动处理暂时性的故障,不用用户实现很容易实现错误的重试逻辑,可以避免分页查询而使用streaming pagination,以及降低尾延迟等。
0x03 Blockwise-Columnar Storage
Paper中还提及到了Spanner使用的一个新的存储格式。原来的存储格式很大程度上使用了Bigtable的代码,也就使用了Bigtable的格式。Ressi是Spanner引入了新的结合了OLTP和OLAP一些要求的格式,同样是基于LSM-tree来存储。对于LSM-tree的layers使用行存的方式老保存,在block的层面以列的格式来保存。类似于PAX的格式。由于Spanner是一个多版本的数据库,一个数据可能存在多个版本。但是不同版本使用的概率是不同的,Ressi的思路是将最近的版本保存在active files中,而之前的比较老的版本保存在inactive files中,类似于一个冷热分离的设计。另外对于大的value,也适用保存到单独文件中的方式。
Ressi’s fundamental data structure is the vector, which is an ordinally indexed sequence of homogeneously typed values. Within a block, each column is represented by one or multiple vectors. Ressi can operate directly on vectors in compressed form.
0x04 总结
参考
- Spanner: Becoming a SQL System, SIGMOD ‘17.
