Umbra: A Disk-Based System with In-Memory Performance
0x00 基本内容
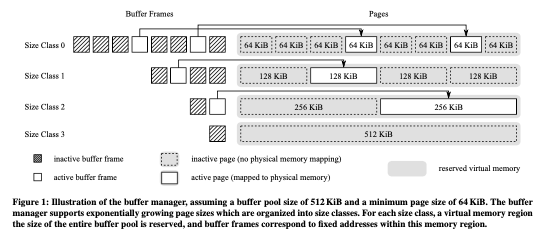
这篇Paper的主要内容是一个Disk-Based的数据库系统的Buffer Pool相关的设计。之前一段时间内全内存的数据库设计是一个热门的方向,然后这篇Paper认为圈内存的数据库成本太高了(A modern 2 TB M.2 SSD can read with about 3.5 GB/s, while costing only $500. In comparison, 2 TB of server DRAM costs about $20 000, i.e. a factor of 40 more),而设计了Umbra这样一个Disk-Based的数据库系统,而且接近In-Memory数据库的能力。而这Umbra的buffer manager的核心是一个variable-size pages的设计,其基本思路如下图。一般的Disk-Based的数据库使用page为单位来管理磁盘上面的数据,而这个page大小是固定的,常见的page大小有8KB,16KB等。这样简化了buffer manager的设计,但是处理一些大字段 或者是字典压缩相关的lookup tables的时候超过了这个大小处理起来就会比较麻烦。
0x01 基本设计
UMbra选择的最小的page大小为64KB,比常见的page要大。而且会有多个不同的page大小,后面的大小按照2倍的方式增长,理论上一个page的大小可以和整个buffer pool一样大。不过实际上大小一般都是最小的几种大小。这些不同大小的page由一个统一的buffer pool来处理。在处理将这些磁盘上面的数据load到内存中的方式上面,Umbra使用mmap来映射一个内存区域,每个大小的size class都会使用一个单独的mmap映射的区域。一个buffer frame中会保存一个指向这个page的指针。这个buffer frame中的pointer保存的指针信息在数据库运行过程中是不会改变的。
- 为了将数据load到内存里面,需要读取一个page的数据库的时候,就使用pread这样的syscall将数据load到mmap映射的内存的位置。mmap映射的内存是在使用的时候才会实际分配。所以一开始为每个size class的page mmap可以放下整个buffer pool的内存区域也是可以的。在需要驱逐一个page的时候,如果是一个dirty page则需要写会磁盘。一个dirty page在数据写会磁盘的之后,使用madvise的MADV_DONTNEED来提示内核在必要的时候对应的内存可以回收。以此来保证buffer pool使用的内存在一个配置的size里面。这里映射是匿名映射,madvise with MADV_DONTNEED操作实际上没啥很大的开销。在page淘汰算法上面,使用的是LeanStore那样的思路。
- Paper中认为仅仅是使用了变长的page不会解决所有的问题。为了继续优化,同样地,Umbra也引入了LeanStore中的Pointer Swizzling的思路。为了避免使用PID来管理在内存中的page,Umbra引用一个page的64bit值可以是内存中的一个地址,也可能是磁盘上面page的PID。区别通过最低的一个bit来表示。如果最低的bit为0,则为高63bit为一个pointer。否则,63bit分为两个部分,低位的6bit表示size class,高57bit表示PID。这样可以表示的size class数量为64种。在这种设计下面,需要保证一个page只会被一个pointer引用,以及使用的page eviction方式也需要修改,相关的思路在LeanStore的论文中[2]。
- 另外一个是Latch的优化。每个内存中的buffer frame会有一个64bit的versioned latch。这个latch可以是exclusive,shared或者是optimistic的方式来获取。64bit被分为5bit的state信息和59bit的version。state中记录了这个latch是否被获取,以及处理哪一种的模式之下。而version部分用于optimistic中访问数据是否还是有效的检查。exclusive模式下state被设置为1,而shared模式下面设置为n+1,n表示同时请求了这个latch的线程的数据。这个5bit的state可能在一些情况下这个不该用,这个时候就会使用一个额外的counter。另外,无论是latch是被获取为exclusive模式 or shared模式,都可以在optimistic的模式下面使用。optimistic模式只能是读取操作使用,读取之前需要获取version值,而读取完成之后需要检查这个version。由于这个数据可能已经被修改了,这样检查不对就需要重新读取操作。
- 在结构上面,Umbra使用B+tree来组织数据,而每个tuple使用一个8byte的ID来标识,这个ID是自增的(that tuple identifiers increase strictly monotonically),这样避免了一些麻烦。另外在分配新node的时候也等到目前的inner node和leaf node都满了才分配。Inner node总是使用最小的page size。Leaf page中的数据使用PAX格式来保存数据。Umbra使用的Recovery方式也是ARIES风格的方式。Paper中这里提到了要特别处理的一个问题就是,要保证在原来保存一个大size的page的位置去保存一个较小的page的课恢复性。比如一个128KB的空间开始存储了一个128KB的page,后面将其load到内存,一些操作之后这个page被删除。然后创建了2个新的64KB的page。如果这个时候系统crash,可以可能存在的情况是完成了些相关的log记录,而没有实际的page数据。这样可能导致读取到之前的旧数据。目前Umbra的方式是只会reuse同样size的disk space。
Paper中还提到了一些其它的优化,比如其string的结构。Umbra使用16byte header保存一个string的元数据,4byte表示长度,而如果string长度12以内的话,直接保存在这个header中。如果超过了12,则可能保存一个prefix,地址信息记录为offset值或者是一个pointer,根据是否在内存中来选择不同的方式。string保存out-of-line的数据会细分为persistent, transient, 以及 temporary几种,
References to a string with persistent storage, e.g. query constants, remain valid during the entire uptime of the database.
References to a string with transient storage duration are valid while the current unit of work is being processed, but will eventually become invalid. ...
Finally, strings that are actually created during query execution, e.g. by the UPPER function, have temporary storage duration. While temporary strings can be kept alive as long as required, they have to be garbage collected once their lifetime ends.
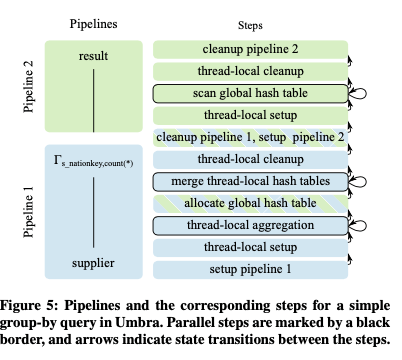
Umbra中也同样适用来查询编译的技术,不过这个团队前面开发的Hyper不同,其使用了一种自定义的IR,而不是使用LLVM,可以获取更加为查询编译优化的设计。另外查询编译也使用了adaptive编译的方式,在必要的时候才会编译执行。编译和在Hyper中将查询变为一个大的可执行的code fragment不同,Umbra将其编译为很多 fine-grained的部分,变现为一个modular state machines。比如select count(*) from supplier group by s_nationkey这样的查询被编译为如下图所示的部分。主要分为2个pipeline,第1个为scan操作,第二个为group操作。Pipeline有分为了多个step,每个step可以是单线程 or 多线程来执行。每个step编译为一个function。查询操作抽象为在这些step中的数据转化操作。多线程的时候使用morsel-driven的方式。
Mosaic: A Budget-Conscious Storage Engine for Relational Database Systems
0x10 基本内容
这篇Paper讲的是实现在Umbra中的一个Storage Engine,Mosaic。主要的目标是实现一个为scan-heavy的workload环境下(OLAP),可以很好地支持多种不同存储设备的存储引擎,能够自动的适应有DRAM, Persistent Memory, NVMe SSDs, SATA SSDs, 以及 HDDs等多种设备的环境,并利用好其个各自的性能。之前存储的一些存储系统在这种情况下的一个思路是分层的设计,但是Mosaic并没有使用这种设计,而是使用device models 和 linear optimization的方式来寻找一种data placement solution,来优化吞吐。其基本设计如下:
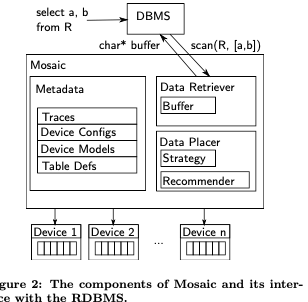
有这样的几个核心组件,metadata中会保留存储设备的一些信息,包括了其容量、性能、价格等的特点。Data retriever负责获取数据,可以从不到的存储设备获取,自己内部也会有一个buffer。另外的data palcer来处理将数据放置在哪里的问题。存储数据的时候,Mosaic使用Parquet格式来存储,适合Mosaic面向的scan heavy的workload环境。另外Parquet方便支持多种不同压缩方式,方便数据存储在不同的设备上面的时候使用不同的压缩方式。而且Parquet分配保存列的数据,方便Mosaic方便保存、移动数据等。Data retriever组件这里会讲存储为Parquet格式的数据转化为DBMS比较好处理的格式,其维护了一个较小的buffer pool,用于暂存DBMS正在处理的一些数据,已经预取一些数据。Buffer主要是为大量的scan优化,作用和一般的buffer pool有些不同。由于数据可能保存在不同的存储设备只是,data retriever会负责发表取回数据。对于NVMe SSD这样的需要多线程来操作才能返回出最高性能的设备,data retriever会使用一个reader线程池来操作。读取操作的时候,完成的时间实际上是最慢的线程决定的,所以数据的placement strategy就比较重要了。数据解压缩会使用另外的一个decompression thread pool来操作。为了避免多个并发操作相互影响,其还会使用semaphore来实现一个per-device thread limit,这个limit值不同设备上不同,比如HDD就不适合并发的访问。
0x11 设计
Paper中比较多的内容是关于其data placement strategy。Paper中根据下面的几个条件,来预测一个table scan time,从而引出data placement的决策。其最终估算per unit of storage的cost使用这样的公式: \(\\ const_{total} = \sum_{c∈C}\sum_{d∈D} I_{d,c}\cdot cost(d)\cdot\frac{size(c)}{cr(d)}.\) 其中C为columns,D为devices;I为一个函数,一个column c保存在设备d上时,其为1,否则为0;size为大小,cr为压缩率。而scan设备d上的一个column c的时间开销使用这样的公式: \(\\ t_{d,c} = t_{seek} + \frac{size(c)}{cr(d)\cdot t(d)}\) 其中t为throughput;t-seek为寻道时间,有些设备上可能没有。处理的总时间为: \(\\ t_{total} = \sum_{T∈TS} \max{(\sum I_{d,c}\cdot t_{d,c}| d∈D)}\) 其中max中的为计算T为scan一个table的时间,TS为一个操作scan的table的集合。max的意思是其取决于scan最慢的一个column的时间,因为其并发处理。
1. Columns are atomic,即一个列的数据保存在一个设备上;
2. Queries are I/O dominated,查询主要要考虑的是IO;
3. The throughput of a device is independent of the number of columns being read in parallel, 这个要求Mosaic多不同设备的并发读作一个处理;
在其基础是谁,其使用两种策略。一种称之为HOT,即 places the columns read the most often on faster devices,另外一个为LOPT,即finds the optimum placement using linear optimization。Paper中的数据,LOPT的性能能好上30%。
- 对于HOT的策略,其有两种方式:一种是在Table Granularity粒度上使用HOT策略,选择将最频繁访问的table放到最快的设备上面。在Column Granularity上的HOT策略细粒化到一个Column,将访问最频繁的数据放到最快的设备上面。HOT策略的缺点是其实际上是一种分层的架构,另外也不能很好的利用多个设备的并行访问特点。同时访问HOT的column的时候能利用所有的存储设备一般是一个更好的选择。
- 而Linear Optimization Strategy将这个问题抽象为一个优化问题。OLPT算法要求一个column只会保存一次,即不会在一个地方重复保存,而一个column只会保存在一个存储设备上面。另外在capacity模式下,要求其所有的数据压缩保存之后其小于存储设备的空间,budget模式下面要求总的开销不能超过一个值。在结合其它的压缩算法的特点(配置在metadata中),压缩解压缩的性能,设备性能数据等,抽象为一个线性优化的问题。Paper中利用Gurobi来计算这个问题。
0x12 评估
这里的具体信息可以参看[3].
参考
- Umbra: A Disk-Based System with In-Memory Performance, CIDR ‘20.
- LeanStore: In-Memory Data Management Beyond Main Memory, ICDE ‘18.
- Mosaic: A Budget-Conscious Storage Engine for Relational Database Systems, VLDB ‘20.
