Two-Level Adaptive Training Branch Prediction
0x00 基本内容
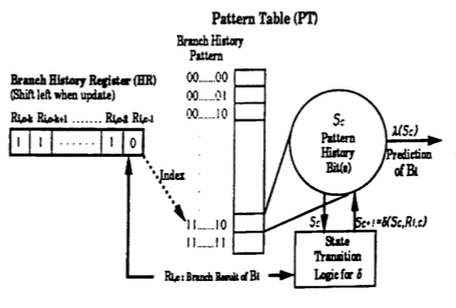
分支预测对CPU的性能影响非常大。一般来说,分支的跳转与否都有明显的规律,对于一个分支来说其跳转与否的倾向性是很明显的,这样的情况下预测下一次分支跳转与否可以通过记录前面这个分支跳转与否就可以预测,这样的方法就能实现比较高的预测准确率。基本的方式比如使用饱和技术器的方式,最常见的就是使用2-bit的饱和计数器。这样的方式是让简单,但是很有效,后面的branch predictor的设计都会有这样的思路。在此基础之上,Two-Level的是改进了简单的2-bit计数器不能识别更加复杂的pattern的缺点。基本思路如下图:这里2-level的意思是,通过一个PC找到一个Branch History Register,然后在通过这个BHR的值去寻值Pattern Table/PHT里面值,得出预测的结果,
Since the history register table is indexed by branch instruction addresses, the history register table is called a per-address history register table (PHRT). The pattern table is called a global pattern table, because all the history registers access the same pattern table.
0x01 细分
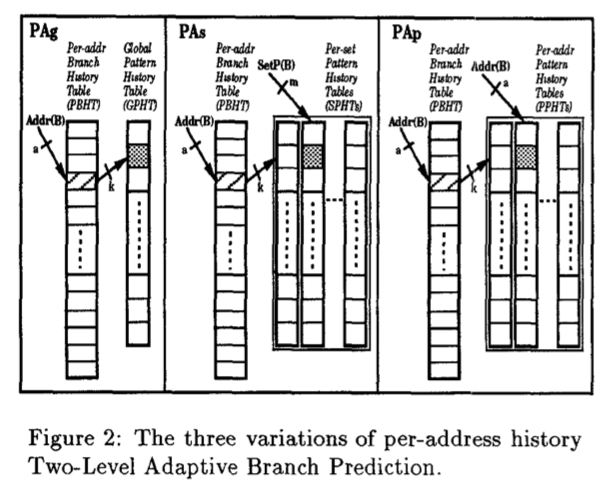
上面的基本的2-Level Predictor的方式,BHR是每个branch各自有的,而PHT是使用的branch是使用同一个,所以这样可以称之为per-address BHR - global PHT的方式,简写为PAg[2]。除了per-address BHR,global BHR的方式之外,[2]中提到了一种set的方式,即在per-address和blobal中间的一种折中的方式,使用来自一个set的branchs的分支历史。除了BHR是否使用global的,还是per-address的,还是set的方式,PHT也将其分为了global,per-address和set三种方式,这样组合下来,就有9中的组合方式,分别简写为 GAg, GAp, GAs, PAg, PAp, PAs, SAg, SAp 和SAs。比如per-address BHR的示意图如下:
0x02 改进
这里讨论的多是前面分类中的global BHR的方式。由于发现2-Level Predictor很难继续提高预测准确性的一个原因是不同地址索引到同样的PHT位置造成的。这样使用某种机制来优化这个索引冲突的问题就可以继续提高预测的准确性。这种思路一般是使用某种简单的hash的方式,比如使用BHR值和PC的XOR之后的值,这样就得到的gshare branch predictor。另外一种方式就是将PHT分为记录倾向于跳转的 和 倾向于不跳转的 两个,选择的时候同时使用2-level的方式寻值两个PHT,然后使用另外的一个choice predictor来决定选择哪一个PHT的值作为预测的结果,这种思路称之为Bi-Mode Predictor。在YAGS Branch Predictor的这篇Paper中,另外总结了优化别名冲突的几种思路:
-
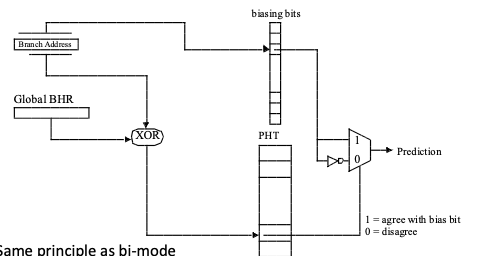
比如在Agree Predictor的思路是大部分的分支都是很有倾向性的,而且在第一次执行的之后这种倾向性就会表现出来。其在一般的2-level的基础上加了一个biasing bit,而原来的2-bit counter表示为是否同意这个biasing bit的值。其值在实际分支跳转结果和biasing bit值相同的时候增加,不同的时候减少。输出的预测值为biasing bit和是否同意预测与否的异或值。biasing bit的值就记录为这个branch地址执行的时候token与否的值,根据Agree Predictor的假设,大部分情况下2-bit counter会“同意”biasing bit的预测。Agree Predictor的Paper中举例了一个这种方式怎么优化准确性的例子,比如两个index到同一个PHT entry的branch,token的概率分别为85%和15%,则两者得出相反的情况下的概率为74.5%。而在Agree Predictor中,阿和个两者的出相反情况的概率为(br1-agrees, br2-disagrees) +(br1-disagrees, br2-agrees) = (85% * 15%) +(15% * 85%) = 25.5%。不过这种计算方式感觉有点过于简化了。
-
The Skewed Branch Predictor的思路是认为别名冲突的主要原因不是因为PHT的容量不足。这个测试数据也说明了PHT达到一定容量之后在增大也不会明显提高预测的准确性。这里认为其原因是lack of associativity in the PHT,冲突时aliasing is conflict aliasing and not capacity aliasing。这样的话可以使用Cache的组相联的思路来优化,不过在Branch Predictor这里会引入额外的结构,比如保存tag的部分,效率可能也会降低。而Skewed Branch Predictor使用的方式是使用一个special skewing function来模拟associativity,其将PHT分为3个brank,每个使用一个单独的hash函数(branch address和branch history的hash值)来寻值每个BHT里面的2-bit counter。决定预测值是什么的时候,通过选择3个里面比例更大的预测,即majority vote。而更新的时候,如果预测错误,则3个bank都更新,而如果正确的话,只是预测正确的bank会更新。
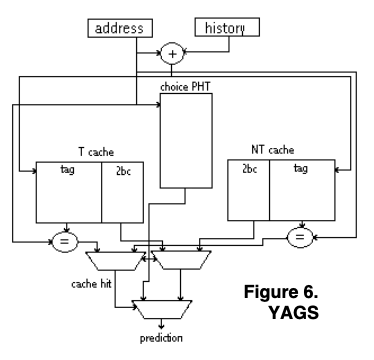
而The YAGS Branch Prediction Scheme这里提到的YAGS Branch Predictor的思路是沿用了Bi-Mode的思路,在这里变成了T cache和NT cache,里面出来2-bit的counter之外,还加入了6-8bit的tag。预测操作的时候先访问choice PHT,如果其预测这个会调整,则再去参考NT cache,这里是检查特殊情况。因为YAGS认为大部分情况下choice PHT的预测就可以了。如果NT cache里面没有,则选择choice PHT的预测值,有则选择其预测的值。choice PHT为not token则查询T cache,逻辑相同。NT cache在预测是来自这里的时候会更新,T cache同理。choice PHT在预测错误的时候更新。
Design Tradeoffs for the Alpha EV8 Conditional Branch Predictor
0x10 基本内容
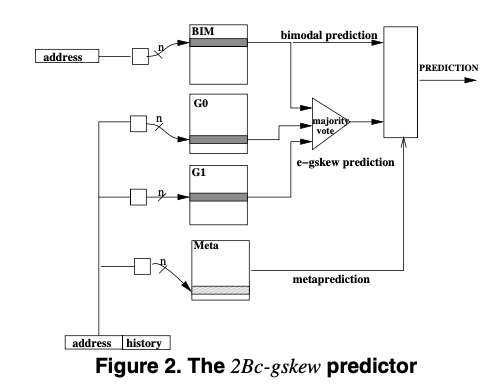
在Alpha EV8上,其Branch Predictor使用的是一种组合的方式。EV8每个cycle可以从I-Cache回去2个instruction block,每个一个cache line的大小。这样就是16条指令。其使用一个简单的line predictor来产生下两个block的地址。而且最近的几个blocks其分支的结果还未可知,使用使用的是最近几个blocks地址的方式(The line predictor consists of three tables indexed with the address of the most recent fetch block and a very limited hashing logic.)。作为这个line predictor后备的是一个主要的branch predictor,其使用Bi-Model和gskew的组合的方式,基本结构如下图。由于其要做到每个cycle完成16个branchs的预测,使用local branch prediction方式要每个cycle完成16次local history table的读取,另外由于有些branchs还在运行之中每个得出结果,即处理inflight状态,就需要一个speculative history的方式,维护speculative local history也会很麻烦。所以EV8上面使用时global history的方式,这样aliasing的问题就需要处理。其使用的branch predictor称之为2Bc-gskew的方式:
- 2Bc-gskew组合Bi-Model方式和gksew的方式,BIM为Bi-Model Predictor,同时有作为gskew 3个banks中的一个bank。G0和G1就是gksew的另外两个banks。Meta brank为meta-predictor。运行的时候根据这个meta-predictor来酸则BIM的结果还是gksew的结果。更新策略:在预测正确的时候,如果所有的predictors都预测正确的时候,都不进行更新;如果BIM和gksew的结果不同,则增加Meta的计数,因为Meta的选择正确,另外预测正确的predcitor也会根据这样的方式增加计数:如果meta使用BIM的结果,则增加BIM的计数,如果是使用gksew的,则增加其3个banks中预测正确的几个。在预测错误的时候:首先更新chooser的值(应该就是meta predictor的值),然后根据新的chooser值选择的重新计算预测,预测正确的话,增加预测正确来源的banks的计数,预测错误的话更新所有的banks。可以看出来这里的策略则是倾向于增加预测正确bank的计数。这样设计的主要两个逻辑/原因是:1. limit the number of strengthened counters on a correct prediction;2. limit the number of counters written on a wrong prediction。
- 在预测正确的时候,2-bit counter的prediction bit不会被更新,而hysteresis bit在预测正确的时候参与最终结果给出的会被增加,通过将prediction 和 hysteresis bit组织为不同的array,实现在预测正确的时候最多对prediction array的一次读和对hysteresis一次写。另外EV8对即个banks使用了不同的长度。
- 另外一个是如果索引table里面的entry。EV8这里索引这些entry组合使用来目前指令的地址、到最近3个instruction fetch blocks的路径信息,还有最近3个instruction fetch blocks的branch and path history。history bit更新的时候,paper中提到一个周期更新16个的话回带来很大实现上面的复杂度,这里使用的方式是使用 history bit和地址的一个组合:当一个fetch block之中有至少一个条件分支的时候,使用其中最后一个条件分支的跳转结果(1 for token, 0 for non-token)与最后一个条件分支的PC地址第4个bit XOR组合而来得到一个bit,移入global history register,减少了更新global history register的数据量。另外最近3个blocks的branch and path history是因为在进行预测时候,由于而V8 branch predictor有两个周期的延迟,而每个cycle可以fetch两个blocks,这样最近的几个还包括自身所在block的预测消息是还不知道的,这样就只能使用其地址的信息。
Paper中还讨论了Conflict free bank interleaved和如何索引branch predicotr的问题。
0x11 评估
这里的内容可以参看[6].
参考
- Two-Level Adaptive Training Branch Prediction, Microarchitecture, 1991.
- A Comparison of Dynamic Branch Predictors that use Two Levels of History.
- Advanced Branch Prediction - ECE/CS 752 Fall 2019,https://ece752.ece.wisc.edu/lect09-adv-branch-prediction.pdf
- The Agree Predictor: A Mechanism for Reducing Negative Branch History Interference.
- The YAGS Branch Prediction Scheme.
- Design Tradeoffs for the Alpha EV8 Conditional Branch Predictor, ISVA ‘02.
