Scaling Replicated State Machines with Compartmentalization
0x00 基本内容
这篇Paper相比较是一篇干货较多的,主要的内容是针对Multi-Paxos的这样的Distributed Consensus算法存在的bottlenecked提出一些优化方案,获得了比较明显的性能提升(compartmentalize MultiPaxos to increase its throughput by 6× on a write-only workload and 16× on a mixed read-write workload)。Compartmentalization的基本思路是将功能划分,是一种优化的方式,而不是一种Consensus Protocol,所以具有一定的普遍适用性,而Paper中的例子主要用的是MultiPaxos。Paper中先分析了MultiPaxos存在的bottlenecks:
- 增加proposers的数量不能提高性能。Client都需要将请求发送到leader,有leader对请求进行排序,然后将请求广播到其它的acceptors。这样leader承担的工作明显多于一般的角色。
- 增加acceptors的数量反而会降低性能。Leader需要获取一半以上的acceptors的accept才能完成一次请求。更多的acceptors需要leader处理更多的工作。
- 增加replicas的数量也会影响性能。Leader需要将被选择的value广播到所有的replicas,同样地,更多的replicas需要广播的数据量更多。
优化的总体思路是Compartmentalization,即将原因的部分化/工作拆分的方式。其优化的总结如下:

0x01 Compartmentalization MultiPaxos
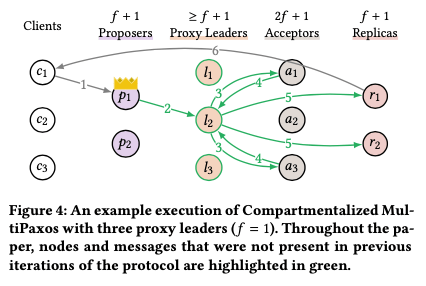
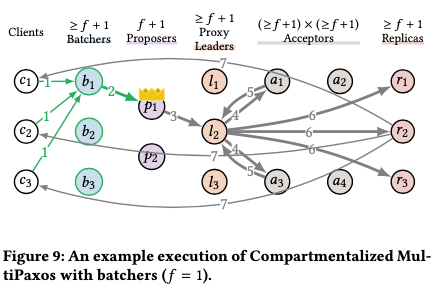
Compartmentalization 1: Proxy Leaders,MultiPaxos中,leader的bottleneck是比较明显的,在一般的没有使用其它优化的MultiPaxos中,处理一个请求会发送至少3f+4个消息。这里的思路是将leader的工作分为ordering和broadcasting两个部分。这里的方式是引入了一个Proxy Leader的角色,这里会加入>= f+1 个的proxy leaders(proxy leader的数量应该和算法的正确性没有关系,f+1个就可以容忍f个节点故障)。Leader在接受到一个client的请求command x的时候,会讲这个command加上一个log entry i,即一个log的位置信息发送代proxy leaders中的一个。后面发送给acceptors、接受acceptors恢复以及发送chosen value的工作都是proxy leader来我完成。在有这个proxy leaders的情况下,leader处理一个请求的处理的消息的数量变为了2。
Bottleneck: leader
Decouple: command sequencing and broadcasting
Scale: the number of command broadcasters
这种思路有点控制流和数据流分开的意思,和之前的一些发布过的优化方式是基本一致的,这里的抽象描述更好一些。一般实现的思路下,proxy leader会是集群中的结点,和acceptors是同一个进程。如果这样的话,在负载比较低的时候,这个优化反而可能会增加latency,如果proxy leaders的角色是clients实现的话,这样的思路就和SDPaoxs,S-Paxos这些优化的思路类似的。
Compartmentalization 2: Acceptor Grids
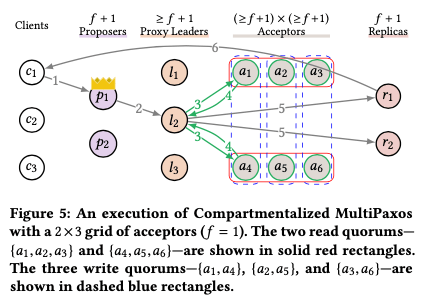
这个 Acceptor Grids的思路从Flexible Paoxs中而来,可以看作是Flexible Paxos具体的一种实现,解决的是acceptors的bottleneck。其思路如下图,一般的Multi-Paxos在Phase 1和2的操作都需要至少和f+1,即一半以上的acceptors交互,f+1这个集合一般称之为quorum。而这里优化为read quorum和write quorum,只要保证Phase 1和2的操作这两个quorum有交叉即可。
Bottleneck: acceptors
Decouple: read quorums and write quorums
Scale: the number of write quorums
Paper这里的一个思路是使用grid的方式,将acceptors分为read quorums (the rows {a1,a2,a3} and {a4,a5,a6})和write quorums (the columns {a1,a4}, {a2,a5}, {a3,a6})。这里有3组的write quorums,每组只需要处理1/3的command即可。这里增加write quorums的机器数量也会导致需要增加read quorums的机器的数量,
Also note that increasing the number of write quorums increases the size of read quorums which increases the number of acceptors that a leader has to contact in Phase 1. We believe this is a worthy trade-off since Phase 2 is executed in the normal case and Phase 1 is only run in the event of a leader failure
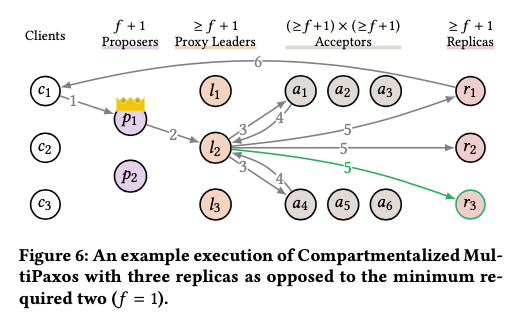
Compartmentalization 3: More Replicas
这里的优化是增加replicas的数量,即基本思路如下图。一般的Multi-Paxos中,增加replicas的数量也会增加leader需要处理的工作,所以增加replica未必增加了性能。但是这里compartmentalization解决了leader的bottleneck,增加replica数量对性能的影响就和之前影响不同。增加replicas也可以对增加性能有利,比如如下图,虽然replicas需要执行所有的commands,但是只要有一个回复client,增加了replicas的数量,就每个replica需要回复操作的数量。另外这个compartmentalization和还有另外一个有点,和另外一个优化Leaderless Reads相关。
Bottleneck: replicas
Decouple: command sequencing and broadcasting
Scale: the number of replicas
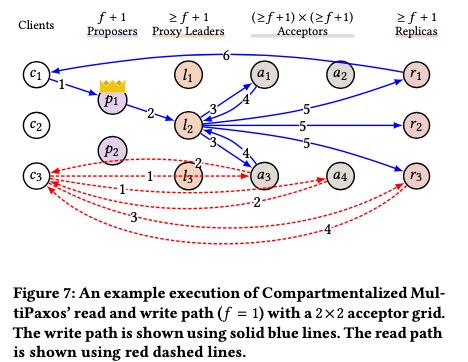
Compartmentalization 4: Leaderless Reads,
这里的思路是避免read的操作也走leader的路径,即将read path和write path的路径分离。这里使用的思路是从Paxos Quorum Reads (PQR)中而来。Client要进行一个读操作的时候,其先发送PreRead消息到一个read quorum的acceptors集合,在接收到这个消息之后回复一个PreReadAck⟨wi ⟩消息,其中⟨wi ⟩为这个acceptors已经voted的最大的log entry的index(the largest log entry in which the acceptor has sent a Phase2b message),这个wi称之为vote watermark。当一个clients接收到一个read quorum的PreReadAck消息的时候,从接收代的wi中得到最大的一个,然后向任意的replica发送Read⟨x,i⟩请求。一个replica在接受到这个Read⟨x,i⟩请求之后,需要等待index为i的log被执行才能回复这个请求。
Bottleneck: leader and replicas
Decouple: read path and write path
Scale: the number of read quorums
0x02 Batching
Compartmentalization 5: Batchers, 批量处理请求是增加吞吐的一种常用的方式,一般的如MultiPaxos加入Batch的优化是由leader来收集一批的请求,然后处理。对于处理当个的请求,replica只需要回复一个client,而处理一个batch的请求的时候自然要回复一批的clients。加入batch优化的时候,ledaer实际上承担了forms batches和sequences batches两个工作,这里为分割这两个工作引入了一个batcher的角色。这里加入了至少f + 1个batchers(batcher的数量应该和算法的正确性没关系,f+1个就可以容忍f个节点故障)。这个batcher添加到proposers的前面,将请求成批之后在发送给leader。Read batching的方式也write的方式类似,client随机选择一个batcher发送其请求,然后batcher对于一个batch X,发送PreRead⟨⟩消息给一个read quorum,根据其回复计算watermark i,,然后发送给Read⟨X,i⟩一个replica执行读操作。(这个优化可能可以增加throughput,对latency应该是不利的。)
Bottleneck: leader
Decouple: batch formation and batch sequencing
Scale: the number of batchers
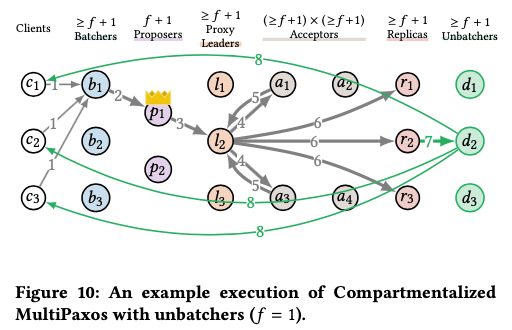
Compartmentalization 6: Unbatchers,增加了batcher之后,replica回复的时候需要回复一批的client,这样会增加replica的overhead。这里的replica实际处理了执行command和回复clients的工作。通过引入一个Unbatcher的角色,这里就将其拆分为两个部分,基本思路如下图。一个replica执行完一个batch的command的时候,将结果随机发送给一个unbatcher,然后由unbatcher将结果回复给clients。
Bottleneck: replicas
Decouple: batch processing and batch replying
Scale: the number of unbatchers
0x03 评估
这里的具体信息可以参考[1].
参考
- Scaling Replicated State Machines with Compartmentalization,arXiv.
