RobinHood: Tail Latency-Aware Caching — Dynamically Reallocating from Cache-Rich to Cache-Poor
0x00 基本思路
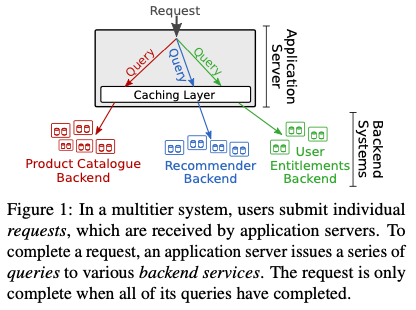
这篇Paper的思路是比较直观的。它的目标是优化如下图所示系统中request的tail latency。这种系统在现在的互联网服务中很有代表性,其特点是一个用户的请求,会导致很多个请求不同backend的请求。这样导致的一个问题就是其请求的latency和所有请求backend的最大的延迟是有很大关系的。这种tail latency的优化之前也有很多:比如使用load balance的方法,不过其缺点是不同的backend负载不同的时候不能处理。另外一个方式是动态的调整某个backend的大小,即动态扩容,但是其缺点是在这样的stateful的场景下面很难快速扩缩容。之前也有使用cache的方式,但是一般都是静态为每个backend分配cache空间的方式。RobinHood观察到,PCT99的latency一般和cache miss的请求关系比较大,但是cache miss的请求也不一定就到tail latency,因为cache miss里面的请求也可能比较快的完成。RobinHood认为如果将那些队cache大小不敏感的backend使用的cache资源分配给那些对cache大小更加敏感的backend的话,能够有效地降低tail latency。基于这样的思路,RobinHood的设计就是如何在不同的backend之间共享并动态分配cache资源。
0x01 方法
在上面的基本思路之上,首先是一个basic RobinHood algorithm。在这个实现中,RobinHood会不停地回首一个backend的cache空间,每次1%。然后统计latency的变化,通过这个变化来发现cache-poor状态的backend。这个操作在要给周期∆ 内进行,这里定义为∆ 为5s。在这样一个时间窗口内,会统计每个请求的延迟。由于这里的目标是优化PCT99的latency,所以统计中会特别注意latency在P98.5 到P99.5之间的请求。对于这些请求,RobinHood会追踪其请求的backends中最慢的backend的ID。然后使用一个request blocking count (RBC)来几个这个backend,这个RBC值最大的就更可能是瓶颈所在。Paper中解释了选择这个指标的原因:对于延迟最大的backend,其并不一定会导致最终请求的延迟很大,而慢的请求中出现的慢的backend更加可能是最终慢的原因。在这个基本的方式之上,RobinHood还进行一些方面的优化:
-
基本的RobinHood算法存在的一个假设是,cache空间的改变会很快反映到查询的latency上面。但是实际上这个是存在一个过程的。RobinHood会监控为一个backend分配的cache空间和其已经使用的cache空间,如果分配的和使用了的直接的差值超过了30%的话,这些backend会被暂时忽略。
-
实际的请求会被复制均衡到多个的app servers,而实际中这些servers接收到的请求不一定是系统的。所以这里每个app server分配cache空间的请求是独立作出的。而RBC统计服务还是一个全局的服务,
... as long as two controllers exchange RBC data, their cache allocations will quickly converge to the same allocation regardless of initial differences between their allocations. Specifically, given ∆ = 5 seconds, any RobinHood cache (e.g., a newly started one) will converge to the average allocation within 30 minutes assuming all servers see sufficient traffic to fill the caches.
0x02 评估
这里的具体信息可以参考[1].
Size-aware Sharding For Improving Tail Latencies in In-memory Key-value Stores
0x10 基本思路
这篇Paper的思路在KV Store中,通过分别处理不同size的key-value,来实现更好的tail latency的思路。这个思路应该不是一个新的了,Paper中的描述也没有太多特别的地方。一般的In-Memory的KV Store是作为Cache使用,而大部分的key-value pair都不会很大,但是如果存在一些比较大的,就可能对一般的请求的tail latency造成影响。这里将想办法来将不同size的key-value分开处理。
- 这里讨论的是在一个用户态的network stack下面,系统为small kv和large kv分配不同的CPU核心。又一般In-Memory KV Store的sharding的方式是通过key-hash处理的。这里就想要一个类似router的角色。这里的解决方式是通过处理small kv的CPU核心来处理进来的请求。对于GET请求,处理small kv的核心然后去查询对应key的信息,然后大小不超过一定的阈值,就直接处理,如果超过了一定的阈值,则转交个处理large kv的核心来处理。对于PUT请求,处理思路是一样的,不过大小在接受到请求的时候就已经知道了。
- 另外一个问题是如何确定这个阈值。这里会统计一个关于size class的histogram,这个工作叫个CPU 0来完成。这里需要统计出来size的 Nth percentile,统计的时候以epoch为周期统计,更新histogram的时候,会使用Hcurr[i] = (1 − α)Hcurr[i] + αH[i]这样类似TCP更新RTT的信息的方式来更新,即考虑到目前epoch的统计,也不会完全舍弃之前的统计信息。
- 怎么划分small核心和large核心通过一个cost function决定,目前是通过处理一个请求需要的network packets来计算的。
0x11 评估
这里的具体信息可以参考[2].
Bobtail: Avoiding Long Tails in the Cloud
0x20 基本内容
这篇Paper关于Amazon上EC2平台网络通信Tail Latency的优化,经过分析定位到不同节点之间的网络通信Tail Latency太大是由于计算节点的原因,而不是网络的原因带来的。在进一步分析之后,将问题定位到是Xen Hypervisor中一些机制,在CPU密集和IO密集的VM混部的情况下,即mix workloads,会导致这样的问题。目前Amazon Cloud好像已经淘汰了Xen,使用一个基于KVM改进的Hypervisor。
-
在Paper中的版本中,其使用的是某个版本的Xen,其VM Scheduler使用一个credit-based的方式,默认情况下给每个VCPU分配30ms的CPU时间。一个VCPU在用完credit之后,CPU会被调度给其它的还有credit的VCPU使用。对于一个负载不大的VCPU,可以进入接受到IO中断之后进入一个BOOST state,调度的时候会被优先的到调度,主要是优化这些VCPU处理这些数据的性能。这个优化是是OS调度器中一种常见的优化思路,即认为这样的进程是交互式的进程,对延迟更加敏感。即使是加上了这样的优化,Xen的调度器对于延迟敏感的应用也是unfair。多个VM共享CPU的时候,有些VM可能需要等待很长的时间。
-
为了证明是Xen调度器上面的缺点导致的网络RTT的tail latency很高。这里使用了一个4个CPU Cores的机器来模拟。发现:混合部署IO密集性和CPU密集性的VM之后。特别是当CPU密集性的VMs使用的VCPU核心数量超过了实际的CPU核心数量的时候,这个现象变得很明显。进一步测试发现,CPU密集的应用消耗CPU的比例也和RTT tail latency相关,那些总是消耗调度器给的全部CPU时间的,反而不会出现这样的情况,而消耗在30%-90%的比较明显。这个现象通过BOOST state优化可以解释:这些CPU密集又没有完全消耗完CPU时间的,会得到BOOST的“优化”,从而占据更多的CPU资源。而且进一步测试中发现,比起平均的CPU故障,一次CPU密集操作的持续时间影响更大。
The takeaway is that even if a workload uses as little as 10% CPU time on average, it still can cause a long latency tail to neighboring VMs by using large bursts of CPU cycles (e.g., 10ms). In other words, average CPU usage does not capture the intensity of a CPU-bound workload; it is the length of the bursts of CPU-bound operations that matters.
基于上面的发现,就需要给出一个优化思路。在Cloud的环境下,多租户共享资源是难以避免的。这样优化思路就是聚焦于避免这样的mix workloads出现。
0x21 方法
实现Bobtail的优化思路,想要获取一个Hypervisor的调度情况,这样想要获取调度器带来的delay。由于不仅仅是IO中断收到这样调度delay的影响,一般的interrupt-based events也会有同样的问题。这里就使用了一个运行一些操作然后sleep的程序来测量这个delay。这个程序会循环地sleep 1ms,然后策略wake up之后经过了的时间。一般情况下,这个时间会略微超过1ms,但是在调度delay的时候,这个时间会明显变长。在测试中发现,这个测量可以很好地识别出来调度的delay,
when two or more VMs are CPU-intensive, the number of large delays experienced by the victim VM is one to two orders of mag- nitude above that experienced when zero or one VMs are CPU-intensive. Although the fraction of such large delays is small in all scenarios, the large difference in the raw counts forms a clear criterion for distinguishing bad nodes from good nodes.
在这个基础上面,给出一个Instance Selection Algorithm,算法是比较直观的。测量M此delay延迟的情况,如果次数小于一个Low阈值,则认为instance是Good的,超过了Hight阈值的,则认为是Bad的,在这其中的需要查看网络的情况。这里的出现的一个问题就是如何选择这2个阈值,而在运行中变得Bad的,可以选择通过选择一个Goog的替换的方式解决。这个算法中,有三个主要的参数:M、Low Mask和High Mask,参数调整一般是逐步尝试的过程。Paper中描述的是M设置为600K,大约100s时间,通过测试Low Mask选择13,High Mask的值为Low Mask的5倍。
Instance Selection Algorithm:
numdelay=0
for i = 1→M do
sleep for S micro seconds
if sleep time ≥ 10ms then
num delay++
end if
endfor
if num delay ≤ LOW MARK then
return GOOD
endif
if num delay ≤ HIGH MARK then
return MAY USE NETWORK TEST
endif
return BAD
0x22 评估
这里的具体内容可以参考[3].
C3: Cutting Tail Latency in Cloud Data Stores via Adaptive Replica Selection
0x30 基本思路
这篇Paper优化Tail Latency的思路是自适应的动态选择请求的副本,其优化的对象是在Cassandra上面做的,移植到其它的分布式系统也应该没什么问题。一个client选择一个从自己角度来看latency最低的副本是一个直观的优化。Paper中认为之前的方法存在一些问题:实际的系统中,性能的抖动是常见的,通过负载来进行replica选择比较困难。Paper中以least-outstanding requests strategy (LOR)的策略为例,没给client选择请求的replica的时候,选择进行中的请求最少的一个。但是LOR的策略没有考虑到每个replica处理请求的速度。Cassandra使用的Dynamic Snitching根据也存在一些问题,比如不能很快地根据系统变化进行调整。这里提出的方法称之为C3,其核心有两个部分:1. Replica Ranking,client使用要给cost function对于server进行排序;2. Distributed Rate Control and Backpressure,这个是为了处理可能导致的都去请求一个较快的replica的问题,需要哟个rate limit。
0x31 方法
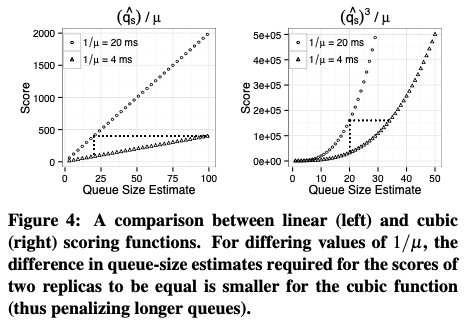
C3的核心之一就是replica ranking,这个replica ranking是每个client独立处理的。优化tail latency主要是要减少replica的queue size和server time。其中queue size,server time通过replica的返回的信息来获取,responsetime(响应时间)通过请求响应的时间来得到。然后通过Exponentially Weighted Moving Averages (EWMA),指数加权移动平均的方法转为一个更加平滑的值,queue size为q-a,server time为u-a。另外为了考虑多个client并发请求带来的影响,对于每个server,client会维护一个进行中请求数量的计数器os,client计算queue size的时候,会使用一个估计值q-e,这个值为q-e = 1 + os*w + q-a,这里w是一个weight参数值,w一般设置为client的数量。ranging servers的时候,通过q-e / u-a来处理的话,Paper中认为存在一些问题,可能会导致更长的queue size。比如下图。paper中使用的一种cubic,三次方的计算方式,来达到penalizes longer queue lengths的效果。其scoring function表示为 \(\\ Ψ_s = R_s - 1/u_s + q_s^3/u_s.\) 其中R为response time,而q为前面处理过估计的queue size,1/u为sever time。
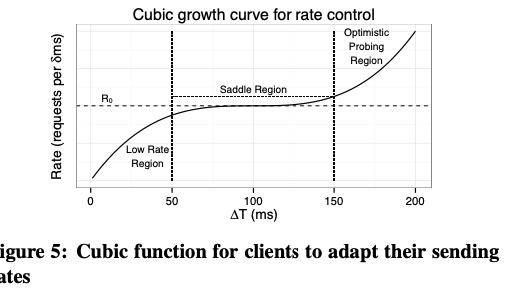
Rate control and backpressure则是为了处理clients都去请求较快的server又造成问题,这里引入了CUBIC拥塞控制算法的思路。每个client维护一个 token-bucket based rate-limiter,限制一个时间窗口内像一个server发送的请求数量。发送rate即为srate,接受到响应的rate记为rrate,这里的目标就变味了让这两个rate尽量match。如果发送的速率小于接受的,C3的增加srate,srate通过如下的方式得到, \(\\ srate = γ \cdot (\Delta T - \sqrt[3]{(\frac{\beta\cdot R_o}{γ})}) + R_0\) 其中∆T是从上次rate-decrease操作到现在的时间,R0称之为saturation rate,为上次rate-decrease操作时的rate。如果接受的rate小于发送的,则srate通过乘以β来减小。γ 为一个参数(desired duration),即三次函数中desired duration的宽度相关的值。
将前面两个主要的部分结合到一起,就构成了如下的算法:

0x32 评估
这里的具体内容可以参考[4].
参考
- RobinHood: Tail Latency-Aware Caching — Dynamically Reallocating from Cache-Rich to Cache-Poor,OSDI ‘18.
- Size-aware Sharding For Improving Tail Latencies in In-memory Key-value Stores, NSDI ‘19.
- Bobtail: Avoiding Long Tails in the Cloud, NSDI ‘13.
- C3: Cutting Tail Latency in Cloud Data Stores via Adaptive Replica Selection, NSDI ‘15.
