The IBM z15 High Frequency Mainframe Branch Predictor
0x00 基本内容
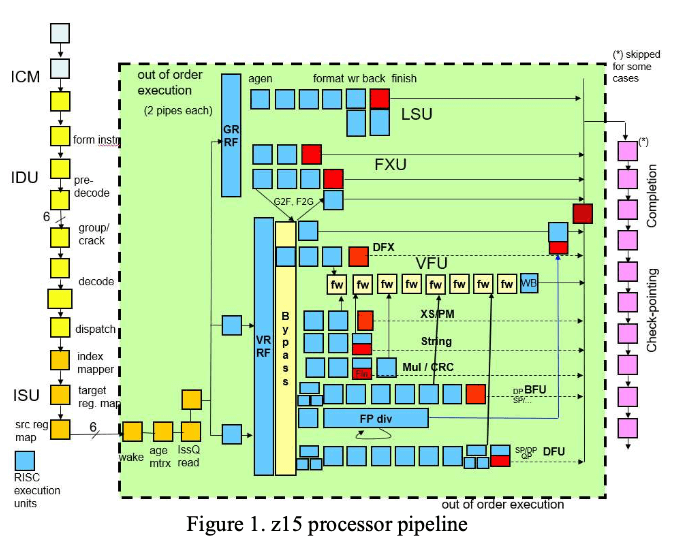
这篇Paper对IBM z15处理其内部的一些结构进行了比较多的描述,比较详细描述了z15的 Branch Predictor,分支预测器的设计。z15是一种非常非常高端的CPU。Paper中给出了其pipeline的示意图。z系列的使用的指令集是一种CISC的指令集,和一般的CPU一样,其也会将指令集转化为一种RISC风格的内部指令去执行。z15有4 level的cache,Level 1和2都是每个CPU核心私有的,而且都是指令缓存和数据缓存分开的,L3为有12个核心的central processor (CP) chip共享,每个256MB,然后每4个通过一个system control (SC) chip通信,这个SC还可以和其它的system drawer通信。这里还维护了另外的一个L4的缓存,大小应该是960MB。
Each of the four CP chips per system drawer communicate with a system control (SC) chip, which in addition to enabling communication across up to 5 drawers on a system, also houses the level 4 cache. Based on the MOESI (modified, owned, exclusive, shared, invalid) protocol, the system maintains an inclusive cache design.
z15的分支预测主要分为indirect and relative branches两种,relative branches有跳转的目标地址,是一个相对于目前指令地址的offset值,而indirect branches预测调用函数的地址,两个寄存器一个作为base,一个作为index,第三个作为 displacement field(位移域)。分支预测这里instruction fetch and branch prediction unit (IFB)这部分处理的。这个IFB会指导instruction cache and merge (ICM) unit,取指令的时候,会尝试根据分支预测从L1中只取那些会执行的指令。通过分支预测,IFB可以尽量让pipeline的front end只做有用的工作。IFB然后交给后面的instruction decode and dispatch unit (IDU)来处理。IDU处理之后的会被发送到instruction sequence unit (ISU)处理,这个IDU是处理一部分乱序执行相关的逻辑。后面就是发送到不同的执行单元处理,比如fixed-point units (FXU), vector and floating point units (VFU),load-store units (LSU)等。另外有 translator unit (XU)处理地址翻译,recovery unit (RU)处理checkpointing。
0x01 Design
Branch Predictor的设计主要要考虑这样的Branch Predictor的几个特性:Capacity,Latency,Throughput和 Direction and Target Accuracy。
- Capacity: Branch Predictor指的是能应对多大的数量分支指令的分支预测。 Branch Predictor能够让IDU这部分尽可能多的做有用的工作对性能有利。z15面临的环境一般是运行大型的程序,其L2 I-Cache都有4MB。BTB是分支预测中一个重要的组件,其记录了一个分支的跳转的地址。如果每5条指令有1条分支指令的情况。z15指令长度平均为5bytes,这样大约为25bytes。计算取32bytes,这样4MB对应到128K的分支。不是所有的branch指令都会导致在BTB中添加一项(all branches are not installed into the BTB, such as statically guessed not taken branches that resolve not taken),如果2条分支指令中哟有1条被添加到BTB中的时候,每个一个cacheline 128B,约4条分支指令,会有2条被添加到BTB中。Paper中提到,在z15处理中,L2的latency为8个cycles,L3位45个,这样L2比L3节省37个。正确的一个分支预测可以节省26个cycles的pipeline delay,即branch restart penalty。这样如果正确预测2个,就节省的时间都超过了一个L2命中带来的收益。所以使用更大的2-level 的 branch prediction tables (BTB2)很有用的。
- Latency。分支预测的latency可以用多种方式来衡量/策略,比如pipeline重启之后将前面两个预测目标地址的指令送到L1 I-Cache的时间,重定向到目标指令的时间,比如从L2 BTB(BTB2)取回内容的时间,比如 branch prediction logic (BPL) 部分的预取指令的的逻辑(通过预取来减少L1 Cache Miss带来的开销)。一次由于什么原因导致的complete pipeline restart的操作,可以导致issue队列为空,填充这个也会带来时间开销并形成一个I-fetches flowing也会额外增加delay。
- Throughput,Paper中描述的是分支预测器的吞吐指的是两个方面:1. how fast branch prediction can get branch directions predicted for passing along to the IDU, 2. and in getting the target instruction text of a branch to the IDU。包括预取分支方向和获取指令两个的速度。比如L1 I-Cache缺失的时候最好的情况是后面的L2 I-Cache就命中,如果分支预测器很快作出角色,把指令fetch到L2 I-Cache,这样可以隐藏L3的的延迟。
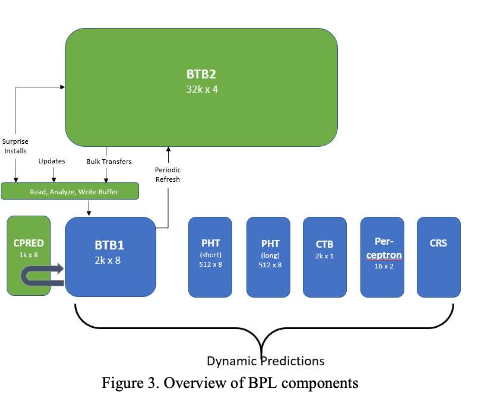
- Direction and Target Accuracy,Accuracy自然就是指的是分支预测的准确度。分支预测很在意准确性,Paper中提到z15中一次错误的预测导致的pipeline停顿可达26个cycles,但是考虑到带来的其它部分的开销(比如打乱out-of-order issue queue),这个开销统计数据约为35个cycles。为了实现更高的准确度,z15的分支预测使用2层的BTB设计,BTB1更小更快,BTB2慢但是更大。另外pattern history table (PHT)和perceptron来提升对direction 预测;而target address提升对changing target buffer (CTB) and call/return stack (CRS)的预测;另外还有一个column predictor (CPRED)(for fast re-indexing of the BTB1 to accelerate the delivery of predictions???)。这些多个部分应该就是组成了一个竞赛预测器。
0x02 Capcacity BTB-Based Design
上面提到的关于Branch Predictor的4个指标有些是相互矛盾的,设计的时候要各种的tradeoff,来实现最终的目的:即实现更高的性能。更大的BTB带来更高的准确度,但是会增加Branch Predictor的延迟,这里和Cache的思路一样使用hierarchical/multi-level的设计,Intel的CPU也采用类似的hierarchical的设计。BTB1可以保存16K个branch跳转的消息,使用2K行,每行8路组相联的设计,而BTB2可以保存128K个,使用32K行,每行4路组相联的设计。
-
BTB2的内容在BTB1中认为缺失的时候访问,只有level 1 predictor的预测采会用于instruction fetching和推测分支的方向和目的地,所以BTB2更像是一个内容的backup。和Cache的设计不同的是,Cache会查询每个cache line可能在Cache中位置,而这里会猜一个想要的内容在不在BTB,之前的设计就是查询了3个连续的可能的(three qualified successive BTB1 search)位置之后,如果还是不存在就假设内容在BTB1中缺失。z15加入的一个功能是在一段时间内预测失败的branch数量超过一定值,就会触发对BTB2的主动查找。一些certain context changing也会触发主动查找BTB2,用于预取和指导level 1的predictor。
-
一次BTB2的上市最多可以查询到128个branch的数据,在BTB1和BTB2之间会有一个staging queue,用于两者时间的数据传输。这里还有一个在z15上被取消了的BTB preload (BTBP)结构,之前起到暂存地(staging ground)和过滤的作用,会过滤掉一些冗余(比如已经存在的)和无用的内容,内容由这里移入BTB1要求在这里的时候有一个命中,另外BTBP也作为一个victim buffer(应该是起到在给一次机会的作用),这个BTBP的设计和一些缓存替换算法的思路类似,但是这个结构会增加BTB1的大小,增加这里的面积和电力消耗。之前BTB1使用两个search ports,z15上用一个实现主要的搜索操作(use a single search port covering twice the address space per search),而另外的一个用于实现类似之前BTBP的功能(通过对要添加到BTB1中的branch进行一个一个read-analyze-write(???)操作)。BTB2命中的数据会先写入到staging queue,这里会利用第二个search port在添加到BTB1之前会查找在BTB1中存在与否。
-
在zEC12这一代,使用的是24K BTB2 和 4K BTB1的设计,使用一种semi-exclusive的算法,而在z15这代改为一种semi-inclusive(semi-exclusive, semi-inclusive中semi的原因??? 猜semi-inclusive的原因是因为这里周期性刷到BTB2)。这里加入了一个定期刷新的功能让BTB2更新为BTB1中新的状态(a periodic refresh feature that attempts to keep the latest BTB1 learning fresh in the BTB2),因为没有BTBP作为victim buffer。另外技术进步BTB2有了更大的空间。这样BTB2作为了BTB1的一个近似的超集,BTB1中的数据会以LRU方式周期性地写回到BTB2,而且这个操作隐藏在一般的search动作中,
Rather than burning the power and reading out all prior content of an about to be evicted branch at the time a new entry is going to be installed, the periodic refresh algorithm hides this process under normal existing pipeline search actions.BTB1中一次未命中会导致一个计数器增加,计数器达到一个阈值之后,会导致一个淘汰一些entries到BTB2的动作。
0x03 Integration into The Processor
这部分讨论的是如何将branch predictor集成搭配处理器中。常见的一些方式比如将branch predictor作为指令fetch 或者是指令decode的一部分。这个位置可以直接获取到一个branch指令的地址,区分出方式 or 非分支指令。放到这个位置的缺点是对跳转的branch,会有一个redirection penalty,另外影响到了I-Cache的预取。z15的做法是将branch predictor作为单独的一个部分,称之为asynchronous lookahead branch predictor,应该是 branch predictor相对执行指令的pipeline相对独立,其预测的“进度”一般会在执行指令逻辑的pipeline的前面。Pieline restart的时候,branch predictor随着instruction fetching操作一起重启。之后branch predictor就相对独立运行自己的逻辑,也使用流水线的方式。
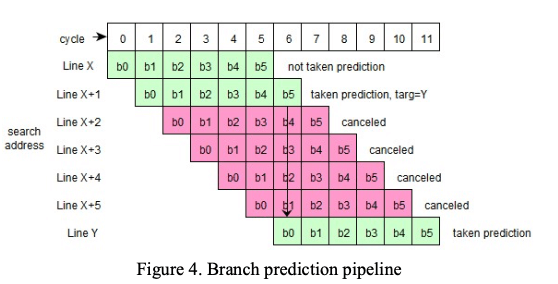
- 如下图所示,branch predictor的预测逻辑为一个6-stages的流水线。逻辑开始之后,从当前的指令地址(PC)开始,根据目前的地址和BTB中跳转的目的地址来搜索后面会出现/预测会出现的分支指令。Branch predictor运行的时候,在第1个cycle,称之为b0 cycle去索引BTB中对应的位置。在b1 cycle分为BTB array中的数据,在b2 cycle得到这里的metadata。在b2 和 b3 cycles中进行hit detection已经相关的操作,在b4 cycle中包含target地址在内的预测决策被准备完成,在后面的b5 cycle中交给IDU 和 ICM 部分使用。在b5 cycle的时候,如果预测一个branch会跳转,则分支预测器的pipeline会对自己进行redirect操作,跳到target地址在运行。
-
Branch predictor的pipelin虽然相对独立运行,但是会和processor pipeline会有一些同步操作(points of synchronization),比如pipeline restart之后。一般来说,branch predictor预测的进度会早processor pipeline的前面,但是有些情况下可能不会,使用需要一个等待的操作来等branch predictor预测的进度到processor pipeline运行的位置。 Branch predictor会对IDU部分来更新自己搜索到哪里了的信息(how many streams of instructions (which end with taken branches), and how many bytes within the current search stream have been searched. )Branch predictor会使用预测的结果来指导ICM部分来进行指令fetching操作。在没有branch predictor的信息之后,ICM都是顺序处理,而在收到branch predictor的信息之后会根据这些信息来调整fetch地址的地址。另外,branch predictor的预测信息也会被IFB部分使用,这些信息被保存在一个global prediction queue (GPQ) 队列中,等待被使用。其它部分使用分支预测的结果也是通过队列的方式,如果这些queues满的话,会导致后面的信息添加不进去。
-
这里还需要处理指令fetching操作顺序fetch指令且已经超前了branch predictor的预测,而branch predictor预测这个分支会调整。这种情况下IDU可能已经处理了一些指令。这里需要对超前回去的一些指令进行舍弃,并冲预测的目标地址重新开始操作。Paper中提到这里会有很多实现上的复杂性/麻烦。另外的一个麻烦是BTB中使用的partial tagging,可能会导致预测的target地址为一个错误的指令起始地址 or 在一个非分支指令上预测等的一些麻烦等。另外还有一些就是查询BTB的时候,可能在BTB中查不到结果,这种branch称之为surprise branchs。对于这样的分支指令,使用静态预测的方式。比如对于非条件调整指令和loop branchs,总是预测会调整,而一般的条件分支预测不会跳转。
-
前面提到z15改变了搜索BTB的方式,由之前的每周期通过2个read ports搜索64bytes的方式变成了通过一个read port搜索64bytes的方式,并增大了BTB1组相联的组大小到8路。z15支持SMT,2个SMT线程使用每周期交替的方式使用read port。Paper中提到,z15的BTB1使用了更大的line size,会导致增大没有发现branch predictions的概率(为什么增大???)。对于这个问题,z15的优化方式是引入了一个SKOOT (Skip Over OffseT) predictor。基本的方式是在BTB中加入了一个字段,记录了到下一个next predictable branch需要跳过了的64bytes的line的数量。初始的时候这个字段为unknown的状态,然后根据后面的信息来更新:
It is initialized to an “unknown” state which does not perform any skipping. Over time, it is updated based on where the subsequent branches are found on the target streams, only decreasing except when being updated from the unknown state. SKOOT was also incorporated into the stream-based column predictor (CPRED) which is otherwise similar to z14
这里预测一个branch跳转到branch指令执行完成,然后去更新branch predictor中相关的信息会有较长的时间。其可能导致的一些问题。。比如paper中距离的一个例子:
... scenarios like a weak-taken loop branch that is repeatedly predicted taken from this state and is usually resolved taken, but sometimes not-taken can cause updates to the weak not-taken state.
导致这个问题的原因是更新分支预测需要的数据需要分支执行完成,而这两者之间实际太长。这个可能导致在其之间的一些预测出现错误,比如这里提到的 weak-taken loop branch这样类型的分支指令,因为信息没有及时更新。这里的解决方式是引入了speculative BHT (SBHT) 和 speculative PHT predictor (SPHT),其基本思路是先使用预测的结果来更新预测需要的数据。这些predictors有更少的entries,用于追踪这样的weak-token的分支。更新SBHT和SPHT的时候,假设之前的预测是正确的,相关数据被添加到其中。后面的预测的时候,先使用这里的预测。后面等到分支指令执行完成的时候,在将其数据更新到BHT、PHT中,SBHT和SPHT中的相关数据则被移除。
0x04 Direction Prediction
Branch Predictor的核心结构就是BTB1,其中BTH和BTB分别处理 direction 和 target的预测。这里BTH使用经典的2bit saturating counter的结构,一般情况下作为主要的方式。BTH适合预测总是倾向于发生 or 不发生的分支,那些有一些更复杂pattern的分支就不是应对。有些分支倾向于怎么跳转和到这个branch时的执行指令的路径相关,最典型的例子就是for循环,一般来说循环跳出的逻辑在循环最后次成立。预测的时候希望能预测跳出的条件什么时候满足,z15和之前的系统都使用了一个 Global Path Vector (GPV) 的结构,起到一个记录达到这个branch之前,前面发生了跳转了一些的branch的地址信息。这个追中的branch数量在z15中被提高到了17个。而那些没有发生跳转分支不会参与到GPV中信息的改动(这里涉及到一个re-index操作,这个具体是???)。
- 一个跳转了的branch,,选择这个branch在的地址的某些bit,hash为一个2bit的值上,称之为branch GPV,然后将这个消息移入main GPV中。17个branch组成的GPV就是34 bits。这里也使用了2-level的预测方式中的Pattern History Table (PHT)。在z15中,这个PHT被从1个table修改为2个,a short和a long table。两个tables的行数是一样的,都使用通过GPV和当前branch指令的地址计算得到的一个index寻址这两个tables。short table使用GPV中最近9个branch的消息,而long table使用了17个。这里使用的是TAGE算法的一个变体。
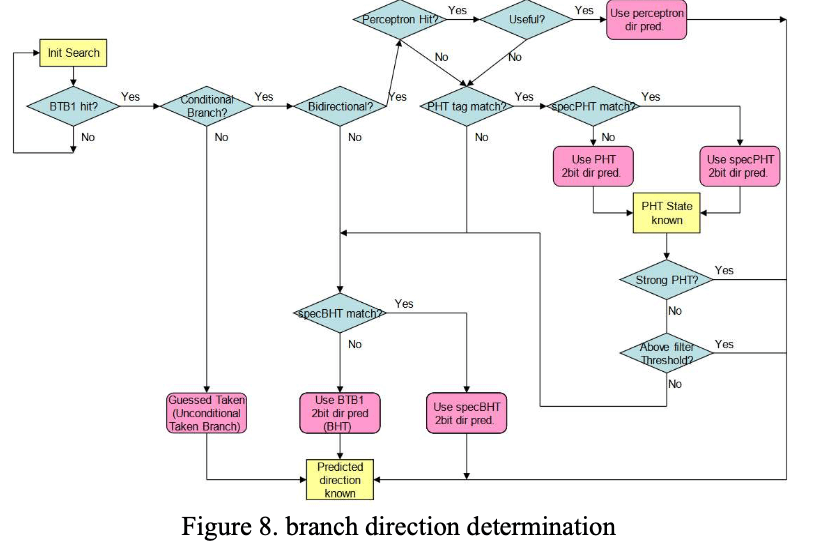
- 在分支预测错误的时候会更新TAGE PHT tables。在BTB1中会记录下这个branch出现了可能跳转 or 不跳转的情况(这样应该是为了实现几乎总是会发生 or 不发生跳转的分支),然后就去更新TAGE PHT。TAGE PHT中每个entry还会记录一个usefulness值,entry只能在usefulness值为0的时候才能被覆盖写。在TAGE PHT中添加新的entry的时候,会选择usefulness值为0的位置。如果两个tables都为0,则选择short table和long table以2:1的比例选择。通过short table预测的错误的时候会将其新的entry添加到long table中。这里这么设计猜测应该是BHT这样使用2bit counter的方式比较适合预测那种总是倾向于跳转 or 不发生的跳转,在如果发生了跳转和不跳转的情况之后,就过渡到使用使用TAGE PHT的方式。所以这里在预测的时候,如果BTB1中记录的一个branch发生了两种情况,则会使用工具TAGE PHT预测的结果。在使用这个TAGE PHT之后,一个 branch prediction tracking (Global Prediction Queue) 结构就会被用于在这个branch完成之前保存其状态。GPQ中会保存没有采用的预测结构预测的结果(这里描述的环境下面会采用的是TAGE PHT预测的结果)。如果这里TAGE PHT预测的结果是对的,而另外结构(short TAGE PHT or BHT)预测的结果是错的,则会增加usefulness的计数值;而如果TAGE PHT是错的而另外的结构预测的是对的则会减少usefulness的计数值。如果预测结果都相同,则不改变。这样的方式可以让预测正确的entry在table中保存更长的时间,而预测不正确的更早的淘汰。为了解决一些情况下weak TAGE PHT prediction的问题,比如说上下文切换之后,这里会使用一个weak filter,主要通过一个weak prediction counter记录的计数值来判断。
- TAGE PHT的方式能够比较好预测根据code path history来决定影响到是否调整的分支,但是有些情况可能比较难处理。这里也引入了一个基于神经网络的perceptron branch direction prediction。一般branch predictor用的perceptron不会很复杂,这里用了32个perceptron entries,使用16行每行2路的方式,可以同时给两个线程使用。PHT之类的方法对于GPV中的不同的path history bits给的权重是相同的,而这里的perceptron的方式会给这些bits不同的权重,从而来分析那些path history bits是对目前的branch调整与否影响最大的。根据path history bits和对应的权重计算出来的一个sum,来决定分支是否跳转。每个GPV中的bit对应到一个人weight,如果分支最后跳转了,对应到GPV bit为1的权重会增加,其它的会减少。如果没有跳转,则GPV bit为1的会减少,其它的增加。另外还会使用一个virtualization的操作来减少存储相关数据需要的空间,根据Paper中的描述,应该是将那些与目前分支相关性不是很大的GPV bit作为一个虚拟存在的,而不实际保存。
- 这里提到z15的perceptron entires数量并不多,其主要也是对一些比较难预测的branch进行预测。所以比较理想的情况是只使用perceptron来预测那些其它方式,即TAGE PHT、BHT方式不能很好预测的branch。这里就引入了一个replacement algorithm来实现这个目标,这个算法基于usefulness 和 protection limit这些机制。因为使用perceptron作出预测,需要有一个learning的过程,所以最好在这个过程中需要不会被replaced。一个新的entry添加进去的时候,会被赋予一个非0的protection limit,来避免被覆盖(只能覆盖protection limit为0的)。usefulness用于决定一行里面的entries哪个被替换(z15 2路组相联)。在初始的时候,会先使用TAGE PHT 或者是 BHT的预测结果,并且会也让perceptron predictor去预测。如果其它predictor预测错误,而perceptron predictor正确,则增加usefulness值(另外如果这个值低于一个阈值的话,其和其它predictor预测失败也会增加这个值),相反情况则减少。如果这个usefulness高于一个阈值,则perceptron predictor会变成优先选择的。
- Direction prediction的决策流程:主要设计到BHT, TAGE PHT 和 perceptron几个预测方式。如果没有在BTB1中标记为无条件分支,则当做有条件的来处理。然后看一个branch是否发生了跳转or不跳转两种情况,如果是,则看perceptron预测器,如果在perceptron中满足且标记为useful,则使用perceptron预测的结果。否则先考虑使用short or long speculative TAGE PHT tables做预测,分支在这里没有的话使用main short and long TAGE PHT tables。另外这里会有一个weak filtering的逻辑,也可以导致改变为使用另外TAGE PHT tables或者是BHT来做预测。
0x05 Target Prediction
Target预测用于预测不止一个branch target地址的分支。比如在多个地方使用的函数,其return的地址就可能会不同的情况。z15使用changing target buffer(CTB) 和 call/return stack heuristic predictor来处理这个问题。CTB保护2K个逻辑entries( four, 512 entry SRAM arrays),每个entry包含一个target address,另外还有一个 virtual instruction address tag(类似cache的tag,用于确定是某条branch的跳转信息)。使用GPV计算而来的一个index来定位到entry。在z/Architecture架构中是没有现实的call - return指令的,这里使用 branch target distance来作为一个启发式的方式去发现call - return的操作。
-
这里使用pipeline去探测这样的call - return操作指令pairs。对于已经处理完成的调整指令,会计算一个分支指令地址与其调整目的地址之间的一个距离,如果超过了一个阈值,则next sequential instruction address (NSIA)部分会保存一个completed taken branch到one-entry deep stack,并标记为valid。然后这个后面完成的分支指令,如果其target地址和这个里面保存的地址match的(需要加上offset值,应该是指令长度的值),且为valid的,则更新BTB1中对应branch的一些metadata,标记其可能是一个return操作。
-
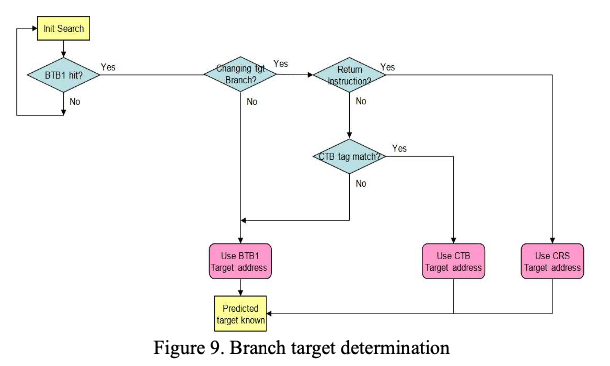
z15先通过BTB1中的数据来预测target地址,如果预测错误,因为这个预测值根据之前的调整的target地址预测的,则就会去认为这个调整是multi targets的,然后就会是使用 CTB or CRS。如果一个branch被标记为multi targets的,则会先去查看是否被认为是一个return操作,如果是,则利用CRS提供的target地址,如果不是则尝试使用CTB。其决策的流程比上面的要简单一些。BTB1中预测target地址错误的情况下,也会保存下这样的一个地址信息,但是会在CTB中添加一个entry,如果CTB预测的结果错误,其entry会被更新为实际的target地址。
-
这里使用CRS作为预测的target地址的方式的时候,如果预测错误,则是识别call/return pair操作的时候错误,想要将BTB1中相关的出这个被认为是return操作但是预测错误。这样后面预测的时候就不会去使用CRS预测的结果,转而使用CTB or BTB1。类似于加入一个blocklist的策略,这里还有个给二次机会的策略,即在一定情况下会从blocklist中移除一个,
Such blacklisted branches are given a second chance through amnesty – every Nth completing wrong target branch that was blacklisted is removed from the blacklist, provided it still resulted in a successful call/return pair matching.
0x06 评估
这里的具体内容可以参看[1].
参考
- The IBM z15 High Frequency Mainframe Branch Predictor, ISCA ‘20.
