Dynamic Branch Prediction with Perceptrons
0x00 基本内容
这篇Paper是关于使用Perceptron,感知机来做分支预测的。根据目前找到的一些资料,基于Perceptron和TAGE模式的分支预测是现在的高性能CPU里面很常用的分支预测方式。通过Perceptron做分支预测的方式基本思路是将一些参数值,每个计算一个weight,这里是实际上对于每个参数都是一个一元一次方程。对歌weight对应一个简单的Perceptron。其表示如下: \(\\ y = w_0 + \sum_{i=1}^n x_i \cdot w_i.\) 在这里做分支预测的时候,x-i的取值只会是-1 or 1,对应到分支不跳转 or 跳转。每个x在运行的时候训练出一个对应到w,然后根据上面的式子计算出y,如果结果为负数,则branch不会跳转,否则认为其会跳转。剩下的几个问题就是: 1. x从哪里来?2. 如果训练w。对于第一个问题,x-i实际上就是 global branch history 中对应的bits。对于第二个问题,其训练的方式为,令t = -1 if branch not-token else 1,定义另外一个阈值a。训练方式:
if sign(y) != t or |y| <= a then
for i := 0 to n do
w_i = w_i + t*x_i
end
end
上面在目前预测错误 or 计算出来的绝对值不大于一个阈值的时候,对每个weight进行+1 or -1,其中x_i和分支结果一致的时候会增加,否则减少。设置阈值应该是为了避免倾向性太强,以免出现情况变化的时候不能及时反映。Perceptron涉及到一个线性可分的问题,如果存在一个hyperplane将正、负分到两个部分,则为线性可分。这里提到一般情况下会是线性可分的,在不能线性可分的情况下,也会实现比较好的性能。在这样的思路上面,基于Perceptron的分支预测器的组成可以是:系统中有由多个Perceptrons组成的一个table,使用那个Perceptron使用分支指令的地址hash得到一个index。一个Perceptron就是一个vector register。其预测值根据前面的方式来进行计算。在分支得出结果之后根据前面的思路进行更新。这样可以调整的参数主要有使用多长的history,weight值以及阈值a的设定等。
An Optimized Scaled Neural Branch Predictor
0x10 基本思路
这篇Paper是使用Perceptron做分支预测的一些优化。从这篇Paper中的数据来看,使用常用的benchmark,Perceptron分支预测器的正确性比起TAGE的要差一点。在这里其预测方式被改进如下,计算方式和前面基本的Perceptron Branch Predcitor类似,主要是加上了bias wight,以及一coefficient。这里W为一个二维的weights的向量/数组,其值咋[-64,+63]之间,对于每行里面的第一个weight,其称之为bias weight,其余的称之为correlating weights。h为global history的长度,这里使用的大小为258,H为保存global history的register。A为一组地址信息,保存了执行了的branch的地址信息,这里值保存了低位的9bit,这样类似于记录了一个执行的路径。C为一个scaling coefficients的数组,记录的时候在前面基本的Perceptron Branch Predictor计算方式上加了这个系数,其目的是发现不同的history bit对当前分支的影响的不同程度的影响,这个在TAGE中的思路是使用不同历史长度的bank来做预测,有些思路相同的的地方,这里系数的选择为C[i] = f[i] = 1/(a+b*i)。之前的论文参数a b的选择根据一个经验选择,不是根据训练而来,而这里后面会提出一个优化就是训练这个系数数组。根据经验选择这个系数一般是观察到最近的history bit对目前分支影响越大,而越远的history影响就越小。
function prediction (pc: integer) : { taken , not_taken}
begin
sum := C[0] × W[pc mod n, 0]
for i in 1..h by 8 in parallel
k := (hash(A[i .. i + 7]) xor pc) mod n
for j in 0 .. 7 in parallel
sum := sum + C[i + j] × W [k, i + j + 1] × H[i + j]
end
end
if sum>=0 then
prediction := taken
else
prediction := not_taken
end
end
在这种的基本设计下面:
- Training,这里训练的方式和前面基本的Perceptron Branch Predcitor是一样的,在预测失败 or sum值不超过一个阈值a的时候,weights就会被更新。更新的逻辑为w_i = w_i + t*x_i。对于bias weight,分支跳转的时候就会增加,否则减少。
- History Update一般使用shift register的方式,由于要考虑到执行目前的branch的之后,前面的一些branch结果还没有出来,所以这里使用2个history,其中speculative version对于没有出结果的branchs使用预测的结果,而non-speculative version更新为实际是否调整的值。在发现预测有错误的时候,需要将speculative version更正。
- Adaptive Threshold Training的目的是动态地选择合适的阈值a。设置一个固定的阈值可能到情况变化时候反应太慢,或者是其它的问题。基本的思路是在预测错误的时候减少这个预测,在一个low-confidence预测正确的时候增加这个值。
这里还使用了其它的一些优化:1. 同时使用Global History和Per-branch history,而不是仅仅使用Global History。对于Per-branch history的weights和Global History为分开保存;2. 训练Coefficients,训练这个系数的目的是发现不同history bit不同的”重要性“,其基本思路是在获知branch跳转的结果之后,如果一个位置的history给出的结果是对的,则给这个位置的系数增加一个值,否则减少;3. 选择阈值a的时候,前面基本的Perceptron Branch Predcitor选择一个固定的阈值,这里改进为选择可以对不同的branch选择不同的阈值,而且这个阈值会动态训练。一个branch选择哪里阈值也根据其地址组织一个阈值的数组。4. 这里还有的一个优化是使用一个Branch Cache来记录那些分支到目前为止的观察总是跳转 or 不跳转。
Virtual Program Counter (VPC) Prediction: Very Low Cost Indirect Branch Prediction Using Conditional Branch Prediction Hardware
0x20 基本思路
这篇Paper的是优化使用Conditional Branch Prediction一些方式/硬件来优化Indirect Branch Prediction,这篇Paper被下面关于Samsung Exynos CPU的那篇提到。Indirect Branch和Conditional Branch一个地址是同一条跳转指令可能跳转到不同的地方,典型的就是虚函数调用。Virtual Program Counter (VPC) Prediction的基本思路是将一条Indirect Branch看作是多条virtual branchs,这样在BTB中,一条Indirect Branch可能对应到多个entries。在可能对用到的多个entries中,一个个查找(可以实现为并行查找)记录为调整的entry,第一个找到的记录为调整的目标地址作为这个Indirect Branch的调整目标。其基本的预测算法如下:
Algorithm 1. VPC prediction algorithm
iter := 1
VPCA := PC
VGHR := GHR
done := FALSE
while (!done) do
pred_target := access_BTB(VPCA)
pred_dir := access_conditional_BP(VPCA, VGHR)
if (pred_target and (pred_dir = TAKENÞ)) then
next_PC := pred_target
done := TRUE
else if (!pred_target or (iter > MAX_ITER)) then
STALL := TRUE
done := TRUE
end if
VPCA := Hash(PC, iter)
VGHR := Left-Shift(VGHR)
iter++
end while
预测是否调整的时候使用GHR,测试多个可能的情况的策略是使用Left-Shift(VGHR)的方式。在BTB命中且预测为跳转的时候,就取当前迭代获取到的值,如果BTB不命中,或者是迭代次数条多,则跳出循环。因为第一次预测的时候,Branch Predcitor还不清楚当前是否为Indirect Branch,则需要通过访问BTB来获取相关的消息。继续循环的时候VPCA使用PC和迭代次数的hash值,VGPR使用上次的VGPR左移位而来。在这样的思路之上另外一个问题就是如何训练这个Branch Predictor:
-
在Branch Predictor的预测正确的时候,其的基本思路是:在这次预测的迭代次数predicted-iter之前对应的entries,做不会跳转的更新,对于当前迭代次数predicted-iter的entry,做会跳转的更新,并更新replacement_BTB相关的消息:
Algorithm 2. VPC training algorithm when the branch target is correctly predicted. Inputs: predicted_iter, PC, GHR iter := 1 VPCA := PC VGHR := GHR while (iter < predicted iter) do if (iter = predicted iter) then update_conditional_BP(VPCA, VGHR, TAKEN) update_replacement_BTB(VPCA) else update_conditional_BP(VPCA, VGHR, NOT-TAKEN) end if VPCA := Hash(PC, iter) VGHR := Left-Shift(VGHR) iter++ end while -
在预测错误的时候,可能存在两种情况: 一个是预测的目的地址错误,另外一个是预测调整与否错误,即wrong-target 和 no-target两种情况。对于第一种情况,这里的思路是对于在迭代范围内的,如果BTB有对应的记录,则做不调整的更新,如果已经存在了预测正确的目的地址(由于迭代在后面而没有被预测的时候使用),则对这个保存了正确目的地址但是没有被使用的做正确预测的更长(并且更新迭代到这个正确的 or 到最大次数 为止)。对于没有存在目的地址预测的情况,会考虑往BTB里面添加一个entry,而添加的位置会优先考虑被BTB-Miss or 使用 LFU策略选择的地址:
/* no-target case */ if (found_correct_target == FALSE) then VPCA := VPCA corresponding to the virtual branch with a BTB-Miss or Least-frequently-used target among all virtual branches VGHR := VGHR corresponding to the virtual branch with a BTB-Miss or Least-frequently-used target among all virtual branches insert_BTB(VPCA, CORRECT_TARGET) update_conditional_BP(V P CA, V GHR, TAKEN) end if
Evolution of the Samsung Exynos CPU Microarchitecture
0x30 基本内容
这篇Paper是关于Samsung Exynos系列的CPU Microarchitecture的发展历程,这里主要的内容是描述了其branch predcitor,u-op cache和prefetch功能的发展过程。关于branch predcitor的基本情况: Exynos系列架构的CPU从M1发展到M6的之后,制程也从14nm提升到了5nm。其branch predictor主要是基于Scaled Hashed Perceptron (SHP)的方式,并加入其它的一些优化措施。其BTB分为了几个部分,0-bubble TAKEN micro-BTB (μBTB)使用local-history hashed perceptron (LHP)来预测,1-2 bubble TAKEN main-BTB (mBTB)使用SHP的方式,而还有一个另外的Level-2 BTB (L2BTB)做为一个更大的保持BTB信息的地址,为了处理Indirect Branch的预测,这里也使用了VPC的思路,引入了一个virtual address-based BTB (vBTB)。对于返回地址预测,使用Return-Address Stack (RAS)的方式。
-
第一版的SHPT的方式,使用8个1024个weight的表,每个项会记录sign,magnitude以及一个“local BIAS”的信息,每个表都是使用hash of the global history (GHIST)(每个历史的bracnh记录一个bit),hash of the path history (PHIST)(每个历史的brach记录其地址的2-4位)和hash of the program counter (PC)组合而来。这里应该是就是这个8个tables都使用这3三种信息的某种组合方式来寻址。记录weights和的时候,signed BIAS weight会被double之后计算。权重和不小于0的时候预测为跳转,否则为不跳转。在更新策略上,也会使用动态绝对阈值的threshold training algorithm,对于目前记录为Always-TAKEN会做一个优化。在每8个对应一个cache line的组织方式上,引入VPC方式的逻辑,会有另外的一个Virtual BTB做为overflow情况下的补充。
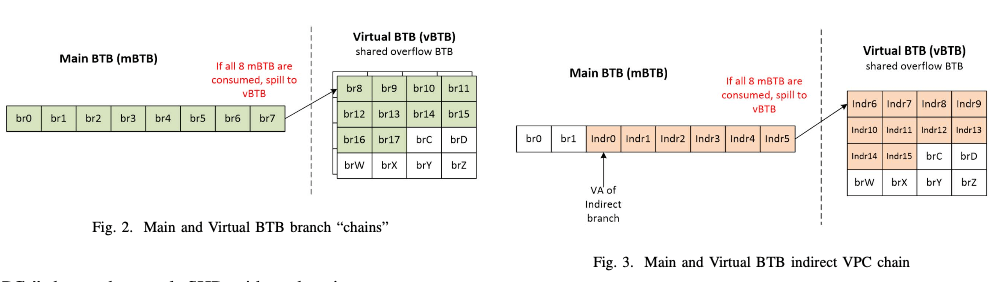
-
为了优化上面的基本方式预测TOKEN的branchs带来的two-bubble penalty的问题,有引入了一个micro-BTB (μBTB),其可以实现zero-bubble的预测,不过容量相对比较小。其具体思路这里没有具体描述,引用的是一份专利。其基本思路使用一个机遇graph的方式,将一些具有相关性,调整/不调整情况下转移到下个位置有规律的组织成一个graph,根据这个graph来预测。这个根据branchs组织而来的graph中,边范围T-LINK和N-LINK两种,对应到 跳转 和 不跳转 的情况。这里会有一个seed branch的概念,即选择哪条指令开始构建这个graph。这里具体的方式paper中没有说明,在另外的衣服专利文件中。
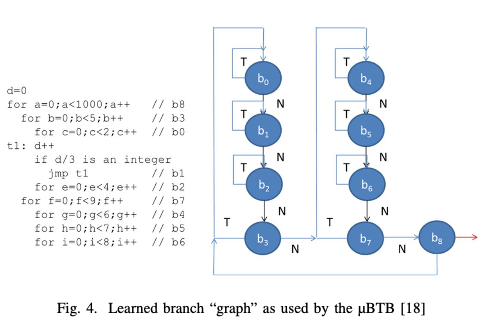
-
根据paper中的描述,后面的M3、M4主要是branch predictor一些结果容量上的增加。到了M5,这里引入了一些优化。其中的一个是将之前的针对always-TOKEN的分支one-bubble redirect优化到zero-bubble,并可以在often-TOKEN的分支上面也使用。主要的思路是通过replication的方式,即将often-TOKEN和always-TOKEN的分支的目的地址分支到其predecessor branches的main-BTB的中,这样一个branch的预测在mBTB中查找的时候,除了可以提供这个branch预测的信息之外,如果其下一个branch为often- or always-TOKEN的分支,则下一个调整的预测地址也可以获取到了。这样增加了预测吞吐的同时,也会带来更新的storage开销。而且这里会和uBTB的作用有一些冲突,uBTB可以预测chain zero-bubble的特点也有其一些作用,这里会使用一种启发式的方式来决定使用那个。
-
另外一个优化是在一次预测失败之后,接着几个会调整的branchs指令带来的pipeline不能填满的问题。如下图所示,一个预测错误之后,开始执行block A(每个fetch的宽度为6),由于在一次预测错误之后,uBTB会被关闭直到遇到下一个seed branch指令。由于预测2个cycles的开心,在pipeline的stage-3的时候,预测其会跳转到block B。这样之前顺序fetch的A+6和A+12的block就不会被使用,转而去fetch Block B。同样在B的中会有一个会跳转的话,又会遇到同样的问题。
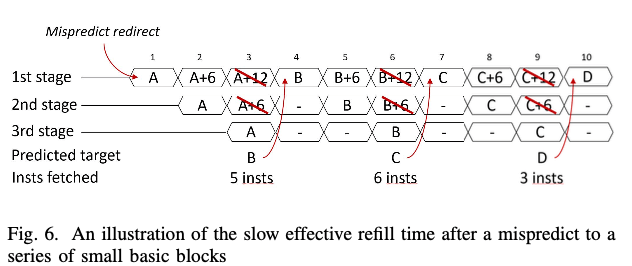
这里的优化思路是使用一个Mispredict Recovery Buffer (MRB)结构。在认为一个关于一个branch的预测是low-confidence的时候,它会记录下来后面3个最可能的fetch addresses。在一个错误的预测发生之后,如果MRB命中,则可以直接使用MRB中记录的地址信息来fetch指令。
-
在M6架构上面,branch predictor被进一步改进,主要改进了JavaScript这样语言运行带来了更多的indirect branch的问题。其加入在vBTB之外,还加入了一个Indirect Target Storage,使用255 sets 4 ways结构,使用一种hash寻址的方式。之前的vBTB的方式仍然保留。发展到m6的时候,branch predcitor占用的storage cost从M1的98.9 KB增长到561.5KB,mispredicts-per-thousand-instructions (MPKI)降低到2.54。
另外一个是关于Branch Predictor带来的Security的安全性的问题,比如近些年出现的比如Spectre之类的,利用CPU预测执行来获取攻击的方式。
参考
- Dynamic Branch Prediction with Perceptrons, HPCA ‘01.
- An Optimized Scaled Neural Branch Predictor, ICCD ‘11.
- Virtual Program Counter (VPC) Prediction: Very Low Cost Indirect Branch Prediction Using Conditional Branch Prediction Hardware, TRANSACTIONS ON COMPUTERS ‘09.
- Evolution of the Samsung Exynos CPU Microarchitecture, ISCA ‘20.
