Facebook’s Tectonic Filesystem: Efficiency from Exascale
0x00 基本架构
这篇Paper是关于Facebook的一个分布式文件系统,Tectonic。这种类型的分布式文件系统最经典的设计为GFS。但是GFS的设计存在一些取舍,这些tradeoff可能在今天就不是很适合了。所以近些年出现另外的分布式文件系统的设计,其特点比如使用分布式的Key-Value or 数据库等代替取代GFS中使用逻辑上单个的Master,元数据保持到内存中的设计;使用分布式的存储池系统来代替Chunk Store。总体上元数据和数据的存储都变得更加解耦,都是用更加通用的分布式存储系统,而这个Distributed FS更加聚焦在维护文件系统的语义上面。Tectonic 也是一个类似的设计。Tectonic整体的架构为见1. 元数据通过hash partition的方式保存到一个分布式的key-value store中,2. 数据保存到一个分布式blob store中,3. 另外在multitenant有不少的一些内容。
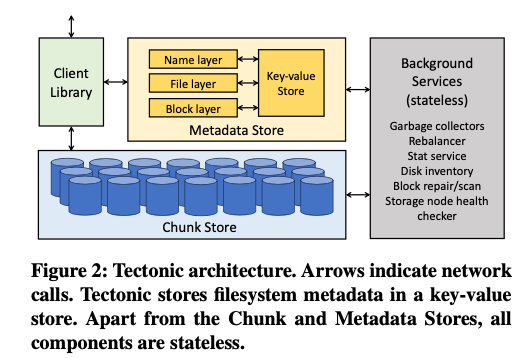
Tectonic的总体架构如上图所示,在Tectonic中:
-
Chunk Store就是一个一般的Object Store,其保存了数据的Chunks,其由文件的Blocks组成。Paper中这里描述的是
Chunks make up blocks,paper这里描述的简短,不是很清楚。从上下文来看,应该是Tectonic中的文件系统又一些blocks组成,block在chunk store中,一些block组成来一个chunk。也就是chunk作为chunk store层面的抽象,而block为FS层面的抽象。而在操作的时候,block做为单个的逻辑单元和持久化单位。而Chunk Store更像是一个Block Store,一个Chunk最终保存到storage node的文件系统之上。这里storage node来保存chunk,而不是使用裸盘等更加激进的方式。做这样的一个Chunk Store会有不少的内容,但是paper中对这里没有多少的描述; -
Block写入的时候会被EC之后写入,根据EC编码RS(r,k)的配置将数据拆分为r个data chunks和k parity chunks,在保存到不同的fault domains内。对于不同类型的数据,会选择不同的EC配比。这里对于短生存时间的文件,会使用更小的配比,比如3+3。Client直接写入Chunk Store。写入chunks选择那些磁盘在考虑了fault-daomins之外,也不是随机选择的,而是会维护一些固定数量的Copysets,在data unavailability和reconstruction load之间取一个平衡。因为如果是随机选择的,即copysets数量非常多,较短时间内有多个disks故障的情况下丢失数据的可能性会更大,而copysets太少的话,数据恢复的带宽受限;
-
元数据转化为key-value的形式保存到一个分布式KVS中。映射方式对于文件路径上的信息,就是id+name的方式,通过不变的id加上变的name组合,方便rename的操作。对于文件的数据,通过file id映射到block id,在通过block获取到保存到哪里的chunks的消息。这个kvs使用的是其ZippyDB。在数据分区上,这里选择了和一般不同的hash分区的方式,其优点之一是可以避免掉一些热点的问题;
-
在上面的元数据和数据不同的服务之外,还有诸多的后台服务,比如rebalance、GC和一些后台数据收集和数据检查的一些服务。这些里面有不少在工程实现上,也应该是比较麻烦的,比如GC,paper中对这些没有描述。

0x01 Multitenancy
这里后面就花了较大的篇幅来介绍Tectonic Multitenancy的特性,其希望使用一个 approximate (weighted) fair sharing,基本的思路是一个资源共享,又能在不同的tenants之间实现资源隔离。Tectonic先将资源分为不同的类型: non-ephemeral 和 ephemeral两种类型,前者指的是存储容量之类的会长期占用的资源,而ephemeral指的是想Storage IOPS capacity 和metadata query capacity这样的的占用会快速的变化的资源。
- 对于ephemeral类型的资源,tectonic认为将tenant作为粒度来管理资源不是一个好的方式,因为一个tenant内部也会有不同的workload,不同的性能要求,另外一个是因为application数量太多,管理起来会比较麻烦。所以Tectonic使用的方式将application分为TrafficGroups的方式,一个group里面的应用类型的资源要求,而不同的tenant可以将其不同的应用划分到不同的group。一个Tectonic集群里面一般支持50个左右的TrafficGroups,每个会分配一个TrafficClass,其表示了对性能的一个要求和获取资源的一个优先级。
- 也就是说Tectonic利用Tenants 和TrafficGroups,在TrafficClass的方式下实现ephemeral资源隔离。每个tenant会分配到其可以得到的一定的ephemeral资源数量,然后这些ephemeral资源会被再tenant内划分给tenant内不同的TrafficGroups。如果一个tenant中某个TrafficGroup的资源过剩,则可以通过降低其TrafficClass的方式提供给其它的TrafficGroups使用,再剩余的也可以通过同意的方式分享给其它的tenants。这里就是一层TrafficGroup 加 tenants,在加上TrafficClass几个层面的一个Multitenancy的方式;
- 对于全局的资源共享方式的实现,在client的层面其client library会使用一个rate limiter服务来请求做一个limiter。请求的时候会根据自己的TrafficGroup,同tenant内其它的TrafficGroup,以及其它tenants的顺序,检查有没有剩余的资源。有得时候在去请求,否则会等待 or 拒绝请求。对于服务node的层面,metadata和data节点本地的资源,也会使用一种local resource sharing的机制,基本方式是通过一种 weighted round-robin (WRR) 的方式,在会超出本地资源容量的时候不给一个TrafficGroup分配资源。另外要考虑的一些问题是要避免小IO请求收到大IO请求的影响,还有就是如何尽量保持高优先级对性能的要求。Paper中描述的一些方式有: 在低优先级/lower TrafficClass的请求还剩余足够的时间去完成它的请求的时候,可以先让给高优先级/higher TrafficClass 先操作;另外一个是会限制操作过程中的非高优先级的请求的数量等。
Paper中还提到tectonic为一些具体业务进行的一些专门优化:
- 比如针对Data Warehouse的应用,比如对不同类型的文件使用不同配置的EC编码,对于 write-once-read-many使用方式最一些特定的优化等,比如buffer数据到一点大小之后再去写入,在这种情况下close文件之后再去读区数据,这样一致性就在buffer数据的方式下也能保证;
- 另外为了优化tail latency,使用了一种quorum writing的方式,也利用了hedge请求的思路,但是不是使用发送多个实际请求的方式,而是讲探测请求提前到实际请求之前的方式。这个方式解决了hedge请求带来额外IO的缺点,基本方式是在发送请求之前,先发送一个reservation请求,使用reservation请求先返回的节点写入数据。比如按照EC 9+6写入的时候,可以先向19个存储结点发送reservation请求,选择先返回的15个写入实际数据,14个返回成功之后就返回结果给client。
- 另外一个是对blob存储的一些优化,比如其对低延迟的一些需求,其使用的方式是partial block quorum appends。其通过写3副本,ack 2个的时候就可以返回来降低延迟。而为了降低存储的开销,和小对象在写入延迟上面做一个tradeoff,这里先写副本,然后在转编码为EC的方式。
0x02 Production总结
这里主要是实际应用过程中的一些总结。
参考
- Facebook’s Tectonic Filesystem: Efficiency from Exascale, FAST ‘21.
