ROART: Range-query Optimized Persistent ART
0x00 基本思路
这篇Paper出自清华,是关于ART在NVM上面范围查询的优化。ART是一种优化版本的Radix Tree,主要是使用不同大小的node来减少内存、路径压缩来减少内存的使用。这里针对NVM环境上ART范围查询优化提出了3个方面的优化:
-
Leaf compaction:lead compaction的思路是将一些leaf接口压缩保存到其上面的inner节点中,思路如下图。这里的lead compaction将一些对leaf结点的指针压缩到leaf array中。这个更像是一种实现上的优化,如下图所示,如果一个leaf array包含m个leaf指针,如果一个结点下面的一个subtree,包含的leaf结点数量小于m,就可以将这个subtree压缩保存到这个结点的leaf array中。这里通过将一些leaf结点和上层的结点保存一起,可以优化range查询的性能。
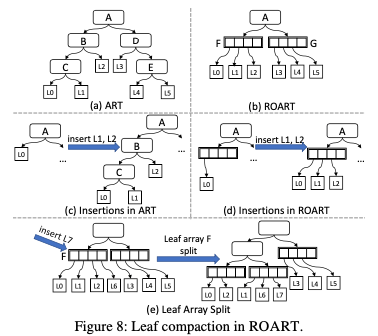
ROART这里ART的整体结构没有改变,原来的ART添加、查找和删除算法也没有太大的变化。这里leaf array里面的数据是没有排序的,所以查找操作如果查找到了了leaf array,需要一个遍历对比的操作。这里使用了一些hash table中使用的优化方式,将一些bits的hash tag保存到指针中。利用了现在的指针只使用了48bit的特点,将高16bit保存为key的一个hash值,对比的时候可以先对比这个来避免取回实际的key做比较操作,这个是比较常见的一个优化。添加的时候需要考虑到leaf array可能满来,满来的话需要一个silit操作,基本方式也是将原来结点中的leaf array取出来根据radix tree要满足的一些特性来分裂操作。
-
Minimizes persistence overhead,减少持久化开销主要是优化ART node的结构。ART基本的node结构如下,ROART通过使用entry compression (EC)的方式将N4, N16, 和 N48类型的几个字段优化到8byte的空间,比如使用讲不同的字段压缩包村到一个8byte值中的方式,比如使用
|empty: 8-bit | key: 8-bit | pointer: 48-bit|的方式来分配64bit的空间。另外的一个是通过Selective Metadata Persistence减少需要持久化的元数据。比如一些可以通过其它部分恢复出来的数据就不要去保证持久化,而是通过维护一个全局的generation number (GGN)(每次启动自增)和每个结点维护一个generation number,在对比上的情况下说明结点元数据非最新,需要恢复处理。而恢复处理之后,会将结点的GN更新为GGN。还有就是split操作过程中的一些减少sfence的优化。这里实际上就是一种类似epoch的机制。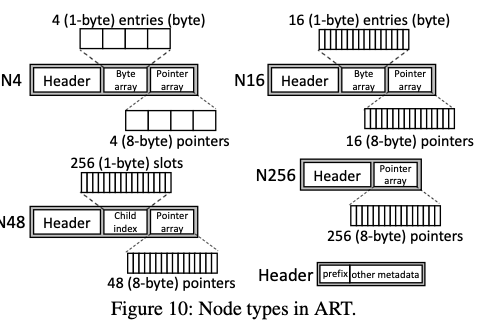
-
Fast memory management。具体方式参见论文。由于NVM作为内存管理的话,分配带来持久化的开销也是需要优化,这里减少这个开心的思路是直接不去持久化分配相关的元数据。恢复重启之后,这里需要使用check操作检查处理那些被分配来但是实际使用的空间。ROART的内存管理基本思路是全局pool加上thread-local pool的2 layers的设计。全局的first layer使用默认128MB大小的page来管理数据,这里使用中的page会使用一个owner_mapping来分配给了哪一个线程,另外使用一个free page list来记录page的空闲情况。Second layers使用从first layer获取的page,使用free_chunk_list记录不同size class的分配对象。GC的方式使用机遇epoch的方式,这里和ROART使用类似ART-ROWEX的并发控制方式配合。First layer由于操作频率低,这里相关的元数据是每次持久化的,而第2层则尽量利用在recovery从实际的结构信息来恢复,避免内存分配的结构消息想要持久化增加开销。这个思路很多都使用类似的思路,而这里具体怎么做更多是一个工程上的问题。
0x11 评估
这里的具体内容可以参考[1].
SpanDB: A Fast, Cost-Effective LSM-tree Based KV Store on Hybrid Storage
0x10 基本思路
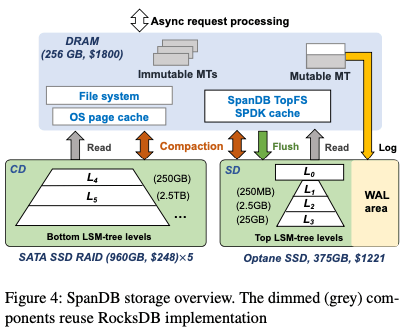
这篇Paper出自中科大。SpanDB的思路是使用高速的SSD来保存WAL、top levels的数据,而选择将低层更大量的数据保存到一般的SSD中,实现高性能的同时可以权衡成本。一般而言,LSM-tree对写WAL的性能最敏感,而最近写入的数据,一般会在top levels,其可能访问的频率也越高。而low levels的数据,其量更大也一般认为其数据较”冷“,这种思路是很常见的数据分层的思路。SpanDB的基本结构如下图,Paper中描述的集中于高速的部分,基本的几个优化方式是讲一些操作异步话,另外使用SPDK等利用好新的高速硬件的性能。
0x11 Async & WAL
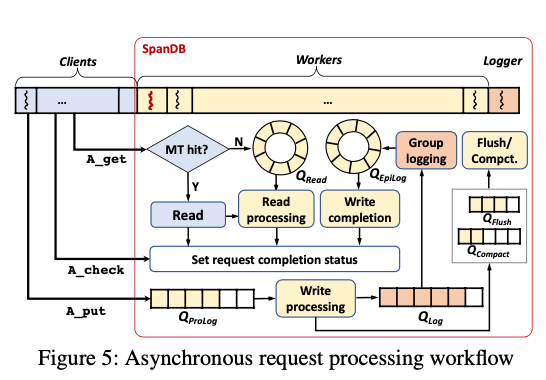
RocksDB使用的接口是同步的接口。SpanDB增加了异步的接口,看上去更像是为了配合SPDK的机polling的方式,基本的代码示例如下。使用的风格是向一个queue里面添加请求,然后轮训哪些请求完成了。这里优化了数据在memtable中的情况,在这种情况下,数据会直接返回走同步的逻辑,避免异步的一些开销。这里增加了A_get, A_put, 和 A_check这样的异步的接口:
Request *req = null;
while(true){
if(req == null)
req = GenerateRequest();
LogsDB->A_put(req->key, req->value, req->status);// issue async req
if(!(req->status->IsBusy())){
pending_queue->enqueue (req);
req = null; // ready to generate next req
}
for (Request* r in pending_queue){
if (A_check(r->status)==completed) { // check outstanding reqs
pending_queue.remove(r);
custom_process(r);
}
} // end for
} // end while
这种方式在实现上,内部维护了一些queues,如下图所示。读区的流程,会先去memtable里面查找,存在则直接返回。而不存在memtable的时候将全球添加到read的队列,有内部的读区流程进行处理。对于写入,会先添加到一个prolog队列,在经过写入逻辑的处理之后生成log entry,然后听见到log队列。这里都会讲数据打成batch来处理提高吞吐。这里的flush/compaction的队列来自RocksDB原来的逻辑。进入数据写入的流程。打成batch的数据进入epilog队列完成最后的一些操作,比如写memtable和设置status。
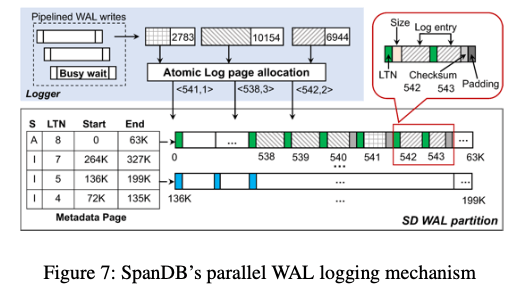
在WAL的设计上面,和RocksDB不同的是使用专门的一个刷log的worker来处理这个工作。这个设计和前面的async接口应该是对应的关系。在SD设备上,SpanDB会预先分配一些pages用来写WAL,每个pages会使用一个log page number(LPN)来标识。另外讲pages分为固定数量的log page groups,每个group会保存一个memtable的日志数据。SpanDB复用RocksDB的log file number作为log tag number (LTN),会记录在page的开始,用于恢复操作。在下图的例子中。Memtable中记录了LTN,也记录了在WAL空间中的维护,在一个memtable被flush到磁盘上面之后,对应的空间就可以被回收了。
-
这里的Logger是多个,写的时候也会是并发地写WAL。并发写的时候,会发出一个write buffer,之后会使用一个原子的log分配机制获取到一个写入的page。在一个Papge中,使用LTN记录这个page的所属关系。另外会记录一些原数据、校验和log本身的数据。并发写不能保证落盘的数据,这里记录下顺序是在发生在前的,会赋予一个更小的lower sequence number。
-
恢复操作的时候,会先读区metadata page来恢复log page groups的关系已经group的范围。这里提到的一个要处理的问题是一个group中可能包含了之前老的数据,需要一种方式来区分。为了避免使用将page清0的方式带来的额外开销,SpanDB使用的方式是服用LTN作为一个page color,
the LTN is always written at the beginning of a page, the pages themselves reveal the location of the last successful writes. Recall the metadata page maintains the current/active LTN (the one with status “A”) – a page within this group but with an obsolete LTN has not yet been overwritten from the current MemTable. -
写WAL的IO一般希望其有更高的优先级:1. SpanDB使用的方式是为WAL的IO请求分配单独的IO队列;2. 另外讲flush/compaction每次的IO减少,有RocksDB默认的1MB减少到64KB,减少flush/compaction可能带来的IO资源争用;3. 也会限制flush/compaction操作线程的数量。
由于SPDK绕开的page cache,这里使用了一个自己实现的cache来代替。这里还有的一个问题是如何处理数据迁移的问题,SpanDB通过动态地检测负载情况来决定数据的保存的位置,是CD还是SD。一般情况下level更小的数据量更小,更加可能保存到SD上面的,但是SpanDB并不限制下层的level在SD上面而level更小的在CD上面的情况。
0x12 评估
这里的具体内容可以参考[2].
参考
- ROART: Range-query Optimized Persistent ART, FAST ‘21.
- SpanDB: A Fast, Cost-Effective LSM-tree Based KV Store on Hybrid Storage, FAST ‘21.
- REMIX: Efficient Range Query for LSM-trees, FAST ‘21.
- MatrixKV: Reducing Write Stalls and Write Amplification in LSM-tree Based KV Stores with a Matrix Container in NVM, ATC ‘20.
