RAID+: Deterministic and Balanced Data Distribution for Large Disk Enclosures
0x00 基本思路
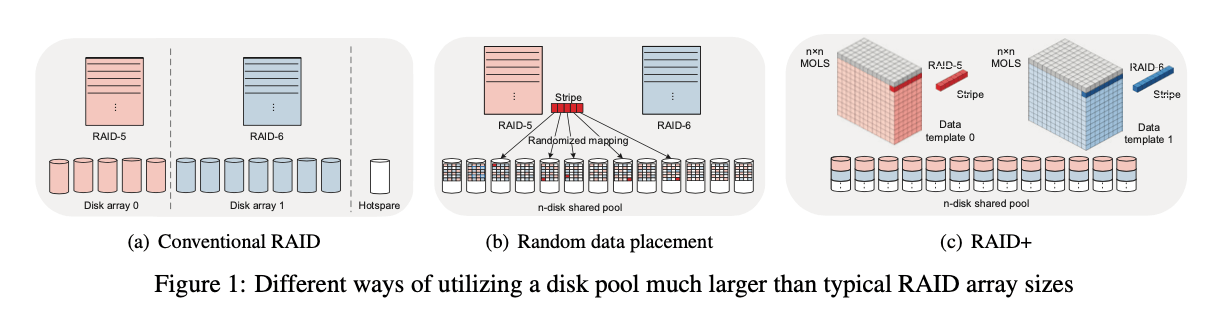
这篇Paper是关于一种新的RAID的方式。随着磁盘的容量的增大,经典的RAID在性能和恢复能力上面已经不太适应了。之后就出现了RAID 2.0。这篇也是使用将数据stripe之后保存到磁盘上面的方式,其特别是利用Latin-square方式,可以得到一个确定性的数据分布方式,与下图所示的使用随机分配data stripe的方式不同。
Latin-square的一个例子就是数独。RAID+这里使用的是多维的。一个例子如下图。n为一个二维的矩形的长度,k表示有几个这样的square。这些squares为正交的定位了每个sqaure对应的位置值都不同。这里如果每个sqaures都是正交的,称之为a set of mutually orthogonal Latin squares (MOLS)。这里可以得到,对于一个n,最多有(n − 1) 个MOLS,最大在n为一个质数的幂的时候。在这种情况下,通过 $L_i(0 < i < n)$ using $L_i[x,y] = i·x+y的方式填充。满足这样数字要求的在4到128之间有4,5,7,8,9,11,13,16,17,19,23,25 27, 29, 31, 32, 37, 41, 43, 47, 49, 53, 59, 61, 64, 67, 71, 73, 79, 81, 83, 89, 97, 101, 103, 107, 109, 113, 121, 125, 127, and 128这样的42个,如果不是这样的数的时候,也可以通过划分的方式,比如 60-disk pool可以划分为(11+49), (23+37), (8+11+41)之类的。
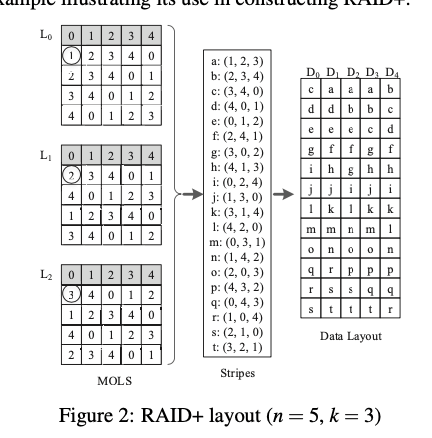
在上面的Latin-square的基础之上,数据的发布使用2中方式,一种是正常的方式,这种方式尽量保证数据均匀方式;另外一种为interim layout,在一些磁盘故障的情况下使用。normal layout:对于k个squares的情况,一个RAID+ layout template的构造通过直接去k个square对应位置的值即可,即$S_{x,y} = {L_0[x,y],L_1[x,y],…,L_{k−1}[x,y]}$,可以保证连续的blocks在不同的磁盘上面,每个磁盘上面的数据是均匀的。这里第1行被忽略掉的。所以是n(n-1)个。这里这些stripe排序的时候,可以选择不同的策略,RAID+将一个subsequent stripe的header为前一个tail的时候,称之为Sequential-read friendly ordering,如果为前一个tail的$S_{x,i}(0) = S_{x,i−1}(k − 1) + x$称之为Sequential-write friendly ordering。这里最后映射到disk的时候,上图画的方式为逐步填充Data Layout这个表格的方式。比如第一个k-block stripe为a(1,2,3)。填充表格的D1,D2,D3。如果是b(2,3,4),继续填充。由于D2以及填充了一个a,则b填到下一行,以此类推。
0x01 有故障磁盘的情况
在有一个磁盘故障的时候,表示为Df。假设这个f为0,在图2中的layout中,收到影响的如下图所示。只要是有0磁盘在的stripes,都会收到影响。这里将有故障的,转移到其它的磁盘上面,如下图所示。填充的方式就是一次填充D0中收到影响的部分。数据恢复的时候,可以使用并行的方式利用其它磁盘的带宽。
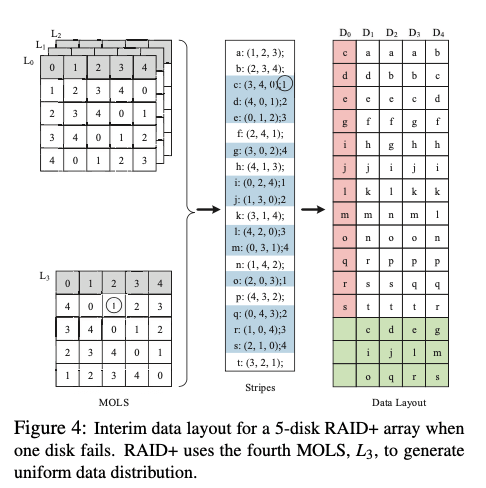
在多个磁盘故障的时候,在可以容忍故障的数量的范围之内,可以在一个磁盘故障的基础上一次操作,虽然会带来少量的数据不平衡:
when a RAID+ pool keeps losing disks (without disk replacement), Monte Carlo simulation shows very slight imbalance in data distribution (CoV of up to 0.29%), while system experiments show application performance degradation of up to 6% (except with sequential read, where RAID+ loses the benefit of its unique read-friendly addressing when more disks fail).
0x02 评估
这里的具体信息可以参考[2].
FusionRAID: Achieving Consistent Low Latency for Commodity SSD Arrays
0x10 基本思路
这篇Paper出自清华,主要是为了 优化SSD Array中一些延迟的表现,这里提到SSD性能比HHD好得多,但是其可能的spike tail latency也明显得多,这里就主要使用了两种方式来实现Consistent Low Latency:
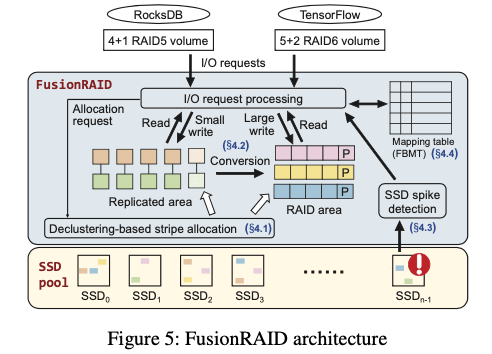
- 第一个就是写入的时候根据写入的大小写入到不同的区域,对于小数据量的写入,直接写入到一个replicated区域,数据复制写入两份,避免更新RAIS的一些编码来降低开销,后面会使用后台任务将replicated区域的数据转到RAID区域。小数据量写副本,通过后台的转移是一种比较常见的方式,在前面的Facebook Tectonic中也有提到这种的方式;而对于大数据量的写入,直接写入到RAID区域就ok了。
-
FusionRAID在将replicated区域的数据转到RAID区域操作过程中,这里做了一个in-position转化的方式,replicated是如下图所示的的情况,复制写入的时候,找到两个区域合适长度的区域,在写入的时候预留了一个parity block的空间。这样的话转化的时候可以直接计算出parity block,并写入到之前预留的空间之内。直接转化为RAID模式,然后回收复制写入的另外一个区域的空间即可。
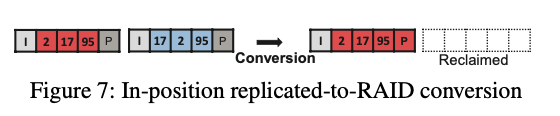
-
另外一个是处理SSD的尾延迟的问题,SSD由于内部的一些特点,比如GC之类的,其尾延迟可能比较高,性能不会很平稳。这里使用的方式为运行时检查Spike的情况,然后将请求Redirection到其它状态较好的SSD上面。。这里使用的方式通过将时间线划分为time solt。对于每个SSD,记录下最后若干的solts中以及dispatched的pending的 requests数量,然后使用一个straggler counter记录pending时间超过一个阈值t的请求的数量。一个请求在被发出的时候会增加对应time solt中request counter的计数,在请求完成的时候会在将对应time solt的请求计数减1。这个time solt使用滑动窗口的方式,来记录最近的一段时间并淘汰之前的数据。在这个time solt窗口滑动的时候,最早的time solt中还没有完成请求数量会增加到一个straggler counter中。如果这个straggler counter的计数超过了一定的阈值,则认为其出现了延迟增加的情况。在发现了这样的情况之后,通过将请求转移到其它的SSD来解决。
-
另外的内容是关于FusionRAID的元数据的,其使用一个Block Mapping Table (BMT)来记录逻辑块到物理块的一个映射关系,另外一个是Block Pairing Table (BPT),记录一个block对应的replicated write block。这个使用64KB的较大的块来减少元数据的量,导致的一个问题会有更多的partial block updates。处理这种一般就是读出数据重现更新、组织之后在写入。为了减少这个的开销的,这里的优化方式是 append partial updates的方式,有partial更小,则会在BMT中中记录一个flag,然后一些结构来记录写入的partail 更小,所以是一种out of place更新的方式。
0x21 评估
这里的具体哪可以参考[2].
Exploiting Combined Locality for Wide-Stripe Erasure Coding in Distributed Storage
0x20 基本思路
之前RAID更多是磁盘的之间的数据分配,后面RAID 2.0的发展,使得这个数据的分配更加细粒度,变成了block层面的RAID。这样就和很多RC的方式越来越像了。这篇关于Wide-Stripe EC的一个Locality的问题的paper出自华科。其是关于Wide-Stripe EC的数据位置放置有如下左边两种方式的讨论,一种在partiy locality方面更好,一种在topology locality方面更好。而这里的提出的combined locality就是这两者的一个结合.
-
Partiy locality一般的思路是使用locally repairable code (LRC),下图(a)中是一个Azure’s Local Reconstruction Codes (Azure-LRC) 的例子,(n, k, r) Azure-LRC将每r个数据块计算一个local parity chunk,一个data chunk丢失会导致访问r个chunk,另外还会计算
n − k − ⌈ k / r⌉个global parity chunks,应对一次丢失多个data chunks的情况,其最多可以容忍任意的n − k − ⌈ k / r⌉ + 1个chunk丢失。这里的方式倾向于将每个不同的chunk都放到不同的rack。另外的一种就是topology locality,其基本思路是减少跨racks的repair bandwidth,一个修复操作访问尽量少的racks。这里将这种模式称之为(n,k,z) ,即将k个data chunks编码出总共n个chunks,放置到z个racks中。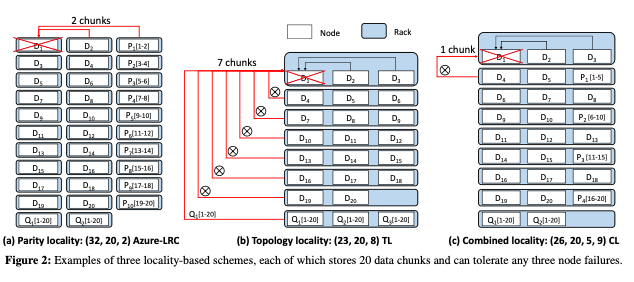
-
这里提出的combined locality结合了两个特点,通过将Partiy locality和opology locality的一些特点结合到一起,来获取两者的一些优点。其参数记为
(n,k,r,z),即将k个data chunk编码为总共n个chunks,其中r个local parity chunks,放置到z个racks中。计算可知每个chunk丢失需要访问的rack为(r + 1)/ f − 1个,可以容忍丢失能力和Azure-LRC是一样的。其数据布置的方式可以参考上图的C,其构建的方式访问分为2步:- 在一定的参数要求下面,找到Azure-LRC的(n, k, r)参数,然后以一定的方式放到z个racks: 对于(n, k, r)的Azure LRC,其有
n = k+⌈k/r⌉+ f −1,其中n为chunks总数,k为data chunks的数量,f为可以容忍的chunk丢失的数,r为丢失一个chunk修复操作需要访问的chunks数。设冗余系数为γ,则有n / k ≤γ,则有⌈k/r⌉ ≤ k(γ −1)− f +1,根据这个找到最小的r。 - 根据r计算出n。放置到z个racks的方式: 对于每个local group,放置r + 1个chunks,即r个data chunks加上一个 local parity chunk,到(r + 1)/c个racks中,其中c为一个rack内的chunk数,可以通过设置 c = f来最小化跨rack的修复流量。
- 在一定的参数要求下面,找到Azure-LRC的(n, k, r)参数,然后以一定的方式放到z个racks: 对于(n, k, r)的Azure LRC,其有
0x21 评估
这里的具体哪可以参考[3].
参考
- FusionRAID: Achieving Consistent Low Latency for Commodity SSD Arrays, FAST ‘21.
- RAID+: Deterministic and Balanced Data Distribution for Large Disk Enclosures, FAST ‘18.
- Exploiting Combined Locality for Wide-Stripe Erasure Coding in Distributed Storage, FAST ‘21.
