Efficient Locking Techniques for Databases on Modern Hardware
0x00 基本内容
这篇paper是关于数据库上lock的一些优化,这些内容是在Shore-MT上面做的,可能和Shore-MT的实现也有一定的关系。这里讨论了range locking、intent locks和deadlock detection以及early lock release的一些优化。
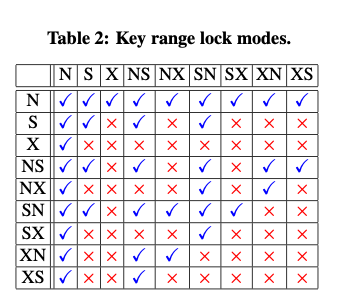
Range locking的一些优化讨论了一些范围锁的内容。上图表示了range lock的一些类型以及其不同类型所之间的互斥关系。其中N表示not lock,而例如 ‘SX’ 表示‘key shared, gap exclusive’,其它类似。这里的一个优化是modes做得很细,优化了之前一些lock方法有些情况没有足够优化的情况,比如缺少‘RangeS-N’ (N stands for ‘not locked’)这样的模式。这种模式在有[10, 20, 30]这样的记录中查询`Select * From T Where T.a = 15时,可以在10上加一个NS-mode (key free, gap shared)的锁,这样key加的是N lock,即没有lock。类似的之前的方案也没有 ‘RangeS-X’ 和‘RangeX-N’ 这样的模式。在这里,一些操作的加锁的方式如下:
-
对于点查询/添加。以下面的查询为例,先找打对应的leaf page,这个时候持有leaf page的S latch。如果匹配到一个key,则加锁SN lock,即key为shared lock,而gap为not lock的锁。这里要处理利用ghost记录来处理delete的情况。而对于不存在的eky,根据情况加锁NS lock。
Data: B: B-tree index, L: Lock table Input: key: Searched key leaf_page = B.Traverse(key); // hold S latch slot = leaf page.Find(key); if slot.key == key then //Exact match L.Request-Lock(key, SN); if slot is not ghost then return (slot.data); else return (Error: NOT-FOUND); else //Non-existent key if slot < 0 then //hits left boundary of the page L.Request-Lock(leaf page.low fence key, NS); else L.Request-Lock(slot.key, NS); return (Error: NOT-FOUND);这样对于记录的点添加也是一样,对于存在key的情况,想要加一个XN锁,即key为X锁,gao为not lock。根据记录是否为ghost作出分别的处理。对于key不存在的情况,根据情况加锁NX锁。然后创建一个sys txn,加入一个ghost key并加是XN锁,最后添加数据。
-
另外一个就是范围查询的处理,对于类似
Select * From T Where T.a Between 15 And 25这样的范围查询,根据其是升序的还是降序的,有没有包括范围边界的key,加上不同的lock。这里会有一些升级到更高的锁来避免一些开销,因为一般的方式为先在starting position加速,移动的时候对于下面的key也想要加速,比如在A位置的时候先在A加上SN的锁,后面的key可能又要加锁。多次操作可能带来额外的开销,这里直接就使用S类型的。For example, an ascending cursor starting from exact-match on A could take only an ‘SN’ lock on A and then upgrade to an ‘S’ lock on the same key when moving on to the next key. However, this doubles the overhead to access the lock table. Instead, the storage manager takes the two locks at the same time to reduce the overhead at the cost of slightly lower concurrency,
另外的一个内容是关于intent locks。这里讨论了如何降低在意向锁上面的一些冲突开销。在这里提出了一个Lightweight Intent Lock (LIL)的方式,在LIL中,除了一个global lock table (GLT),每个txn会维护一个 private lock ta- ble (PLT)。在PLT中会记录事务的intent locks。一个txn要获取一个intent lock的时候,先查询自己的PLT,如果存在则已经获取了。如果没有,则查询GLT,并增加对应lock模式中的counter的计数(The GLT records the count of granted lock requests for each lock mode (S/X/IS/IX).)。全局的操作都是很简单的。如果锁没有立即获取到,这里会用到mutex。在锁被释放的时候,要减少counter的计数。
Algorithm 3: Lightweight intent lock: Request-lock.
Data: G: Global lock table, P : Private lock table
Input: i: Index to lock, m: lock mode (IS/IX/S/X)
if P [i].granted[m] is already true then
return;
while Until timeout do
begin Critical-Section{G[i].spinlock}
if m can be granted(∗) in G[i] then
++G[i].granted counts[m];
P[i].granted[m] = true;
return;
if m ∈ {S,X} then
Leave a flag to announce absolute locks(∗);
base_version = G[i].version;
cur_version = base_version;
while cur_version == base_version do
Conditional-Wait(G[i].mutex, 1 millisec);
cur_ersion = G[i].version;
0x01 Deadlock and EarlyLockRelease
这里还讨论了Deadlock 的一些优化。这里使用的Deadlock检测的基本方式为每个core检查自己的dependencies,如果记录到本地,同时这些依赖的信息会发送给其它的core,然后通过聚合这些信息来发现循环的依赖。这些依赖的信息,会被编码为digest,可以使用类似 Bloom filter 的结构来实现。在这样的基础上面,还要处理几个问题这种方式才实际可用。另外一个优化是Early Lock Release(ELR)。之前的方式主要讨论的一个问题,就是如何处理在一个X锁提前释放之后,后面的S锁要求等到加这个X锁的事物提交了,才能返回,这里使用这样的方式:
-
对于lock table中的每个lock queue,加上一个tag。这个tag记录来最近修改数据的一些持久化的信息。一个txn申请lock的时候,会检查这个tag。然后记录下观察到的最大的。如果一个只读的事物提交的时候,检查最大的tag和目前的durable LSN,如果一件持久化了,则可以直接commit。没有的话,想要唤醒log flusher来刷log。对于读写类型的txn,则在其释放X lock的时候,更新期commit log的LSN信息到这个tag。
Algorithm 7: Safe SX-ELR: Commit Protocol Data: L: Lock table, M : Log manager Input: xct: Transaction to commit if xct did not make any writes then //read-only xct Release all locks. (S-ELR: Always safe); M.check durable(xct.max tag); else//read-write xct commitLSN = M.append-commit-log(); // SX-ELR with the commit LSN foreach req ∈ xct.locks do //in reverse acquire-order queue = L.find queue (req.key); queue.release(req); if req.gm ∈ {X, XN, XS . . .} then //update tag queue.tag = max(queue.tag,commitLSN); M.flush_until(commitLSN);
0x02 评估
这里的具体内容可以参看[1].
Controlled Lock Violation
0x10 基本内容
这篇Paper讨论的关于Early Lock Release的一些优化,同样是在Shore-MT上面做的。这里提出的方式称之为Controlled Lock Violation,和ELR的思路类似,但又不是ELR。在Controlled Lock Violation的方式下面,如果一个事务T1看到了之前的一个事物T0的一个修改,T0事务修改的log已经提交到log buffer但是还没有持久化,T1可以在T0仍然持有lock的情况下访问数据。这里统一会处理一个commit dependency的问题,必须使得T0在T1的前面commit。
- commit dependency问题在这里的处理是当做是一个在log中标识high water mark的问题。当一个事务T1违反了lock的原则提前访问了T0的locks保护的数据的情况下。T0这个时候的log必须是已经记录到log buffer中, 这个时候T0 log的LSN是可以指导的。这样T1就可以指导其需要等到哪个LSN持久化完成之后,其才能commit。如果T1是一个有更新的事务,同样地,它也会写入一些log。这个情况下T1的LSN比L0要大,这样数据库原来的逻辑就可以保证在T1可以commit之前T0已经commit了。如果T1是一个只读的事务的话,T1需要有一个等待T0 commit的wait操作。当然前面的事务abort,可能造成需要后面的事务也abort,即“abort amplification” or “cascading abort“问题。Paper中这里提到,当一个事务的log已经走到了log buffer这里的时候,一般不会出现这样的情况,一种cases就是system failure。
- Controlled Lock Violation看上去和ELR是很类似的,但是存在这样的一些差别:1. T0不会提前释放锁,而是一直持有到其commit/abort;2. T1使用的是违反lock规则的方式,另外T1只能在T0的log已经到log buffer的时候,才能违反规则;3. Controlled Lock Violation相比于ELR,其不需要额外的机制等。
在Combined Locks方面,paper中也提到Controlled Lock Violation的一些优势,这个Combined locks是比如SIX这样包含了S + IX两种类型的一个组合的lock。假设有一个事务T0在一个file上面持有一个SIX锁,后面的事务只有在和这个锁的某个部分有冲突的时候才需要构建这个dependency的信息,比如只和IX部分的存在冲突的时候。而ELR由于使用提前使用locks的方式,可能造成一些锁信息的丢失,这样可能对实际上SIX锁没有冲突的的时候,也需要记录一个commit依赖的关系。另外的一个例子是range locking,如果一个事务T0在一个value 30上面加上了XS mode (“key exclusive, gap shared”)的锁,另外一个事务T1像申请一个 NX 类型的锁(“key free, gap exclusive” – N stands for no lock)。这里实际上是不需要commit dependency的。如果再有一个事务T2,申请一个SN 类似的锁(“key shared, gap free”),则会产生commit依赖的关系。这里谈到了和前面一篇中提到的ELR的对比:
... With early lock release and a tag in the lock manager's hash table, it is impossible to derive these correct answers. Controlled lock violation makes the correct decision easy: As the NX lock of transaction T1 conflicts only with the read-only part of the XS lock held by transaction T0, no commit dependency is required.
另外,paper中也讨论了一些分布式的情况。比如对于Controlled Lock Violation来说,前面的事务通知后面的事务commit,可以采用register-and-report approach。即后面的事务向前面的事务申请一个依赖关系,前面的事务要commit的时候通知,不够这个实际实现情况应该会很麻烦。
0x11 评估
这里的具体内容可以参考[2].
Releasing Locks As Early As You Can: Reducing Contention of Hotspots by Violating Two-Phase Locking
0x20 基本思路
这篇Paper也是一篇关于Lock提前释放来获取更高并发性的一篇paper。它提出的方案称之为Bamboo,其基本思路也是允许一些事务可以访问X锁的一些规则。允许访问这些locks的一些规则的话,同样的要处理和前面两篇一样问题,比如:1. Dependency Tracking,即前面提到的commit依赖的问题;2. Cascading Aborts的问题,本质上和第一个问题是相同的。Bamboo的方式是在lock的使用角色在owner、waiters之外,引入了一个retired的角色。基本思路如下图。在owner直接释放的方式上面,添加了一个retired的状态,表示其数据的更新已经完成,但是lock目前还不能释放。
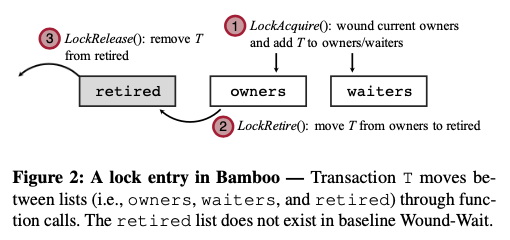
在这样的思路之上,设计这样的基本算法。Bamboo为每个lock添加了一个list,称之为retired。在这个list上面记录了这个lock retired的事务,另外之前就有一个owners和waiters的list。在一个事务更新完成一个数据之后,其可以讲持有这个lock的状态啊边吃retired,即由owners变成retired。这个时候另外的事务可以变成这个lock的owners,然后进行dirty read。通过这些list,可以指导事务之间的一个依赖关系,比如在一个事务T retired之后,这个list后面的事务都和这个事务存在一个 dirty-read-induced dependencies的关系。另外,Bamboo为每个事务添加了一个Transaction.commit_semaphore,遇到一个retired有冲突的情况,则增加这个semaphore的计数,在一个依赖的事务离开retired状态之后,这个semaphore的计数减少。在这样的基本设计下课,lock获取的逻辑如下。这个只有scan的时候,retired和owners都要考虑,另外不同的一个是PromoteWaiters。PromoteWaiters的主要操作为scan这个lock的watier(按照timesamp顺序),如果这个waiter和当前的owner没有冲突,则将这个waiter变成owner,变成owner的时候,需要重处理和retierd的冲突问题。
Function LockAcquire(txn, req_type, tuple)
has_conflicts = false
for (t, type) in concat(tuple.retired, tuple.owners) do
if conflict(req_type, type) then
has_conflicts = true
if has_conflicts and txn.ts < t.ts then
t.set_abort()
tuple.waiters.add(txn)
PromoteWaiters(tuple)
Function PromoteWaiters(tuple)
for t in tuple.waiters do
if conflict(t.type, tuple.owners.type) then
break
tuple.waiters.remove(t)
tuple.owners.add(t)
if ∃(t’, type) ∈ tuple.retired s.t. conflict(type, t.type) then
t.commit_semaphore ++
# move txn from tuple.owners to tuple.retired
Function LockRetire(txn, tuple)
tuple.owners.remove(txn)
tuple.retired.add(txn)
PromoteWaiters(tuple)
Function LockRelease(txn, tuple, is_abort)
all_owners = tuple.retired ∪ tuple.owners
if is_aborted and txn.getType(tuple) == EX then
abort all transactions in all_owners after txn
remove txn from tuple.retired or tuple.owners
if txn was the head of tuple.retired and conflict(txn.getType(tuple), tuple.retired.head) then
# heads: leading non-conflicting transactions
# Notify transactions whose dependency is clear
for t in all_owners.heads do
t.commit_semaphore−−
PromoteWaiters(tuple)
对于lock retire的操作,基本的内容就是将一个事务从owner list移动到retired list。另外在LockRelease的操作:1. 如果本事务abort了,而且是EX类型的锁,则后面相关的事务都需要abort。Commit情况下的relese,要更新commit_semaphore。另外的一个内容是什么时候使用lock retire,paper中的方案是最后一次更新一个tuple的时候。什么时候是最后一次访问,可以通过programmer annotation或者是program analysis的方式来实现。
0x21 Optimizations and Abort
在基本的方法之上,paper中还讨论了一些优化的设计,主要有这样的几点:
-
No extra latches for read operations,对于一个read请求,其可以直接在lock acquire的时候就retire。如果后面不会写入读取了的tuple,则可以将读取了的一部分的数据保存到一个暂存区中。
-
No retire when there is no benefit,在一些情况下retire的情况没有收益,这里是通过在等待commit_semaphore上面的时间来判断,
We use a simple heuristic where writes in the last 𝛿 (0 ≤ 𝛿 ≤ 1) fraction of accesses are not retired. ... . However, if a transaction turns out to spend significant time (i.e., longer than 𝛿 of the total execution time) waiting on the commit_semaphore, we will retire those write operations at the end of a transaction. -
Eliminate aborts due to read-after-write conflicts,在前面的方法中,一个事务申请一个S锁的时候,会abort已经在这个lock上面的更低优先级的写操作的事务。这里因为Bamboo保存了一个local copy,这样就可以让一个tuple有多个的没有提交的更新,实际应用的时候还需要解决读取那个版本的问题:
The optimization naturally fits Bamboo as it allows for read-modify- write over dirty data and multiple uncommitted updates can exist on a tuple. However, the idea cannot be easily applied to existing 2PL as reading uncommitted data is not allowed hence there exists only one copy of the data. -
Assign timestamps to a transaction on its first conflict,另外一个timestamp怎么选择的问题。
0x22 评估
这里的具体内容可以参看[3].
参考
- Efficient Locking Techniques for Databases on Modern Hardware, ADMS ‘12.
- Controlled Lock Violation, SIGMOD ‘13.
- Releasing Locks As Early As You Can: Reducing Contention of Hotspots by Violating Two-Phase Locking, arXiv.
