Vector Quotient Filters: Overcoming the Time/Space Trade-Off in Filter Design
0x00 基本思路
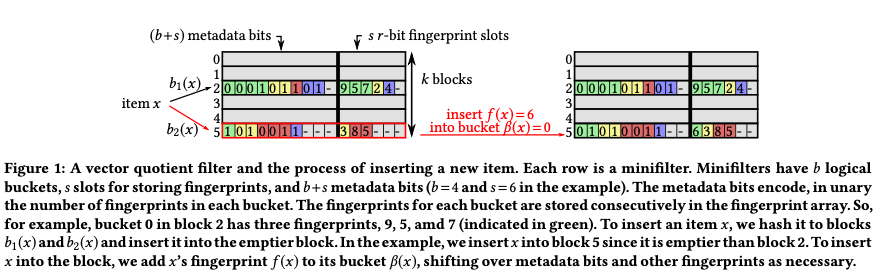
这篇Paper是将要发表在SIGMOD‘21上面一篇关于Filter的文章。Vector Quotient Filters的设计也是使用多个hash函数的设计,每个hash用于寻址一个block,称之为mini-filter。每个mini-filter在内部被划分为多个buckets,bucket保存fingerprint。对一个hash函数计算而来的一个hash值,其拆分为一个logb-bit 的bucket index,以及一个r-bit fingerprint。设一个key到一个bucket的映射关系为β (x ),到一个fingerprint的映射为f(x),添加一个key的过程就是将f (x ) 到bucket β (x )的过程,这样就可以从f(x)和β (x )恢复出f(x),即根据一个fingerprint保存的问题恢复出其完整的hash值。Mini-filter的基本结构如下,可以看出每个item x/key可以选择的block为2个,每个blocks中分为两个主要的部分:第一个部分为metadata bits,另外一个为fingerprint bits。在这样结构上的基本操作:
- 一个min filter的metabits部分保存一个(b+s)-bit bucket-size vector,一个最多支持s个fingerprint。另外的fingerprint bits部分就是保存实际的值。这样设计的一个原因是如果直接使用保存s个rbit的fingerprint的,那么hash冲突就很难处理,每个位置只能保存一个fingerprint。而如果使用固定大小bucket的话,空间利用率会很低,因为很难bucket里面的数据都塞满。这里通过metadata bits和fingerprint bit的组合来实现一个逻辑上不定大下的bucket。每个bucket的边界划分则是根据metadata bits来的,可以从其中看出来,metadata bit中bit 1表示一个bucket边界,前面多少个0表示这个bucket里面有多少个fingerprint。由于metadata bit都是1bit的,消耗内存不大。
- 所以在这样的结构上面,定义一个select操作,和一些succinct结构类型。
select(m,i)表示在bit串m上第i个1的位置,比如select(001000000,0)=2。这样第j个bucket出现的第一个fingerprint的位置为select(m,j−1)−j。对于j > 0 的情况其fingerprint的范围为[select(m,j−1)−j+1,select(m,j)−j),为0时候,开始index为0。这些计算可以通过x86 PDEP之类的特殊指令直接计算。添加一个key的时候,先尝试讲对应的fingerprint fp添加到bucket b,fp选择的位置为select(m,b)−b,后面的数据也顺序往后移动。选择bucket的时候,有2个候选位置,选择更加空的一个。如果都满了会导致添加失败。这个可能添加失败的特性在一些情况下会是一个问题。 - Vector Quotient Filter另外的一个特点是支持是支持删除。这个引入了cuckoo filter中的一个思路,称之为XOR tricks。计算第二个bucket候选位置的时候,通过b2(x)=b1(x)⊕h(x)的方式。这样添加两个key i, j ,如果有
h(x)=h(y) and b-i(x)=b-j(y),则也会有`{b1(x),b2(x)} = {b1(y),b2(y)}j,即第二个候选位置也一样。这样存在两个这样满足条件的时候,可以删除一个而不会导致出错,但是者还是存在一个限制就是要求删除的是实际添加过的。
0x01 评估
关于Vector Quotient Filter的性能、空间使用评估可以参看[1].
Chucky: A Succinct Cuckoo Filter for LSM-Tree
0x10 基本内容
Chucky这篇提出了的Filter则是面向了具体的环境,不是一个通用的设计。LSM-tree中,使用Filter来提高lookup性能,因为可以大概率排除那些不包含这个key的level中的查找操作。而 LSM-Tree结合Cuckoo Filter之前的一个设计是从另外一篇Paper中来的,Chunky这里做了很多的优化。其基本的思路是,不在每个SST使用一个filter,而是总体上使用一个整体的Cuckoo Filter。这个Cuckoo Filter的一个特点是,其中还保存了这个hash值对应的最新的一个key所在的level。这样如果查询一个不存在的key,就可以直接返回。而查询一个存在的key的时候,可以直接过滤掉一些level。其基本的操作思路如下:
- 这个Cuckoo Filter,CF,中的每一项会包含一个fingerprint和一个level ID。查询的时候,查询候选的两个bucket,fingerprint匹配的情况下,会以level从新到旧来查询。在memtable flushed到磁盘的时候,其中的key被批量地添加到这个CF中,其中tombstone记录同样会被添加。对应之前匹配了一个的,会添加一个新的对应到最新的level,原来的保存。而在两个都占了的情况下应该是取代一个旧的。另外一个维护操作发生在compaction的时候,对于obsolete的entry,会进行移除操作,而level发生了改变,也需要进行更新。
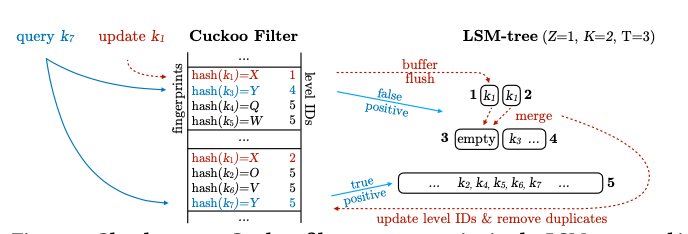
基本的思路没有太多特别的地方,不过这里可能的一个地方是一整个大的Filter都需要放到内存的话,会不会导致内存问题。Paper中也引入了一些的压缩保存的机制,比如剋对Level ID使用Huffman Coding的方式来压缩,因为其保存到Filter中Level ID的频率区别比较大。然后在Lelvel使用变长的编码之后,在CF的entry内也使用变长的编码,配合其达到一个Alignment的效果。
0x11 评估
这里的更多的空间使用上、压缩策略以及性能等的分析可以参看[2].
Conditional Cuckoo Filters
0x21 基本思路
这篇paper是多Cuckoo Filter的一个优化。Cuckoo Filter存在的一个问题是在数据存在比较大偏斜/skew的时候,很容易导致FPR的快速变差。导致这个问题的原因是Cuckoo Filter保存fingerprint的位置数量是固定的,一般为2个bucket,bucket一般为几个的数量。Conditional Cuckoo Filters提出的解决方案是两个:一个是在太多冲突的fingerprint的时候,将fingerprint vectors/bucket转换为一个bloom filter,另外一个方案是使用一种chain的方式,允许一个key使用的候选位置超过2个buckets:
- 对于第一个方法,设置要转化为的bloom filter的hash函数个数为numHash= $\frac{|a|}{#a}\frac{d}{d+1}\log2$,其中|a|表示一个bucket的bit数量,#a表示值的数据,d表示一个fingerprint有d份copies。Bloom filter选择大小为 d·s − 2(|k| + ⌈log2(d)⌉),其中s为size of single entry,k表示the size of the key fingerprint。这里又个问题是如何得到numHash个hash值。从Paper中的描述来看应该是对现在存在的重复的,都加到一个Bloom Filter中,多个hash值则使用现在要加进来的那个计算。添加之后Cuckoo Filter中的重复的可以移除?每个entry应该还要记录一个flag来来表示在Bloom Filter中也有记录。
- 对于第二个方法,基本方式是在前面两个候选位置中重复的fingerprint超过一个阈值之后,通过结合前面两个候选位置和要添加的fingerprint来hash运算得到下一个bucket的位置。查询的时候如果目前一个fingerprint的copies数量超过阈值,则同样要chaining式查询。这样如果支持删除的情况下,应该是要从后面删起。
参考
- Vector Quotient Filters: Overcoming the Time/Space Trade-Off in Filter Design, SIGMOD ‘21.
- Chucky: A Succinct Cuckoo Filter for LSM-Tree, SIGMOD ‘21.
- Conditional Cuckoo Filters, arXiv.
