Evolution of Development Priorities in Key-value Stores Serving Large-scale Applications: The RocksDB Experience
0x00 Resource Optimization
这篇Paper主要是Facebook发表的一片关于RocksDB开发、使用过程中的一些经验总结的文章。其内容主要包含了比如RocksDB资源优化方面为何从write amplification转向优化space amplifiction、CPU利用率、以及对一些新技术看法的内容,其次是一些使用总结:
-
写放大是LSM-tree存在的一个问题,不够其实无论是B-tree和LSM-tree也好,都会存在写入放大的问题,特别是写入为随机的key写入的时候,这个放大是很难避免的。优化写入放大也是最近一些关于LSM-tree优化的研究的一个方面。在RocksDB这里起初写入放大的优化是RocksDB在优化方面的主要目标之一。为此,RocksDB之前加入了加入Tiered Compaction的方式。在一些应用场景下面,这个可以将写入放大有Leveled Compaction方式的10–30优化到4-10。Paper中提到,对应一些常见,比如value比较大的情况,将value单独存储也是降低写入放大一种可行的方式。这个功能这个正在准备加入到RocksDB中,称之为BlobDB。
-
随着RocksDB这些年的的发展,发现很多情况下space utilization变得更加重要。实际上,一般应用对于不会利用完硬件的写入寿命,以及写入的负载也没有太多的约束。也就是在很多情况下,写入不会利用完硬件的性能。这个时候优化space显得更加有价值。Rocks通过使用更加激进的Compaction方式减少空间使用带来的收益更多,另外由通过加入Dynamic Leveled Compactio的功能来实现可以动态调整每层的大小,来获取更多的回收掉dead data的机会。减少空间的使用,可以优化成本的问题。
in a random write benchmark: Dynamic Leveled Compaction limits space overhead to 13%, while Leveled Compaction can add more than 25% . Moreover, space overhead in the worst case under Leveled Compaction can be as high as 90%, while it is stable for dynamic leveling. In fact, for UDB, one of Facebooks main databases, the space footprint was reduced to 50% when InnoDB was replaced by RocksDB -
RocksDB另外的一个优化方向是CPU利用率。目前一些研究也认为在存储硬件越来越快的情况下,CPU会成为一个瓶颈,比如SOSP ‘19上面的KVell这篇。而RocksDB优化CPU因为这里认为在实际系统中,会合理配置SSD和CPU,一般的应用也不会使用完硬件的性能。RocksDB认为现在的CPU有足够的计算能力处理这些计算需求。RocksDB这里优化则为了获得更好的成本表现,近几年CPU、内存的成本上涨,而通过降低CPU等的消耗的方式可以来优化成本。在这个具体的技术方面,RocksDB有使用prefix bloom filters在内的一些range filter方面的优化。在range filter方面,最近几年也有一些比较有意思的学术研究。
-
在存储技术方面,最近几年出现了很多新技术,比如open-channel SSDs, multi-stream SSD 以及 ZNS等。而RocksDB对这些新技术持一个不是很感兴趣的态度,因为RocksDB认为大部分应用是space constrained的,这些技术优化更多在延迟等这些性能方面,另外新技术的优化只能少数的应用获益。RocksDB对In-storage computing也认为其用处不大,其带来的收益不是很明确。非易失性内存方面的技术其也认为应用场景不大,一个原因是使用这样的结构,如果将其作为DRAM的一个拓展。想要对RocksDB目前的一些结构进行比较大的改动。而如果将非易失性内存作为主要存储,但是非易失性内存的容量比SSD小不少,而一般应用是space constraint的。非易失性内存另外的一种应用方式是作为写WAL的地方,但是WAL其的空间并不多,单独使用非易失性内存对成本未必划得来。
-
对于disaggregated (remote) storage,RocksDB持欢迎的态度。一般来说通过资源共享是提高利用率一种常见的方式,而disaggregated (remote) storage是实现存储资源共享的一种比较好的方式。CPU资源、存储资源可以按照实际的需求来配置,提高不同资源的利用率。
0x01 Lessons on Serving Large-scale Systems
这部分描述了一些RocksDB从做为构建大型系统的一个部分的时候得出的经验:
-
一些分布式的系统使用RocksDB作为后端存储的时候,其会利用RocksDB来保存数据的shards。这个在很多利用RocksDB实现的分布式数据库系统,比如TiDB,CockroachDB中就是这样的事。而这里讨论了一个节点上面存在多个shareds的时候资源管理的一些经验。RocksDB为此加入了在同一个节点上面可以全局限制线程数量、内存使用的等的功能,通过设置resource controllers的方式,
... When running in single process mode, having global resource limits is important, including for (1) memory for write buffer and block cache, (2) compaction I/O bandwidth, (3) compaction threads, (4) total disk usage and (5) file deletion rate (described below), and such limits are potentially needed on a per-I/O device basis. Local resource limits are also needed, for example to en- sure that a single instance cannot utilize an excessive amount of any resource. -
在一些分布式系统下面,其有自身的保障数据持久化的策略,来保证系统的可靠性和可用性,比如通过Raft、Paxos之类的方式来复制数据。在这些机制的存在,对RocksDB的WAL要求就不那么高,为此RocksDB提供多种模式的WAL,在一些情况下可以减少强制持久化数据到磁盘带来的开销。
-
这里还提到了还一些工程上面的经验:1. 比如删除文件的时候,需要有一个rate limit。因为在SSD上删除文件会导致SSD的TRIM操作,引起SSD 内部的一些比如GC的操作的话,可能引发一些问题;2. 比如data format compatibility方面,在configurations管理的一些总结;复制和备份的一些功能等;
0x02 Lessons on Failure Handling and Interface
这部分讨论了RocksDB在实际过程中的一些经验教训总结:
-
从故障处理中得出的一些经验:数据静默损害是比较常见的,而且很多的数据静默错误会传播。数据的完整性保护想要需要多个层面的数据完整性校验,比如从Block integrity,File integrity, Handoff integrity等这些方面。另外一个是end-to-end 的数据完整性校验,最好能保证全路径都有数据校验。
-
从key-value接口中的出的一些经验。这里谈到来一个timestamp的优化。RocksDB使用的MVCC的timestamp为内部生成的。在很多系统会使用自己的版本逻辑,在使用RocksDB作为后端存储的时候,这两个版本的逻辑可能可以合并,能够应用带来一些优化的空间。
Segcache: a memory-efficient and scalable in-memory key-value cache for small objects
0x10 基本思路
这篇paper是关于内存key-value cache一篇优化的文章,主要关于内存方面的一些优化,整体的内容偏向工程实践上面的一些优化。Paper首先先分析了现在的一些in-memory key-value cache,比如redis、memcached,在内存使用上存在的一些问题。比如TTL的问题,一般使用lazy的方式回收过期的对象造成内存占用偏大,可以回收内存不能及时回收;另外一个问题是key-value元数据带来的额外空间,比如memcached stores 56 bytes of metadata with each object;还有的问题是内存管理的方式带来的,比如常见的使用slab方式管理内存的时候,不可避免的会有很多内存碎片,内部的or外部的,这些碎片无法使用造成内存浪费。所以这里提出的3个基本的优化思路就和这3个问题相关:
-
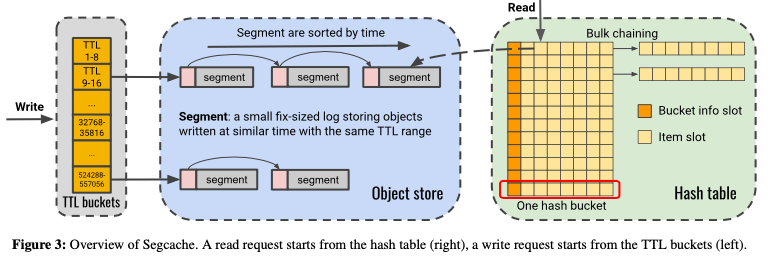
Be proactive, don’t be lazy。为了及时回收掉TTL过期的对象,直接一个个全部扫一下肯定是开销太大,影响到整体的稳定。Segcache的做法是引入了TTL Buckets,将TTL相近的对象直接放到一起,在其中的对象都过期的时候直接整个的回收。其基本的思路如下图所示。对于每个TTL bucket里面的对象,其被组织为fixed-size的一系列的segment,组成一个list。另外整体的hash table索引会引用这些segments里面的数据,
Segcache uses 1024 TTL buckets, divided into four groups. From one group to the next, the time width grows by a factor of 16. In other words, Segcache uses increasingly coarser buckets to efficiently cover a wide range of TTLs without losing relative precision for typical TTL buckets.Segments list中是按照creation time排序的,又有相似的TTL。这样后台主动回收的时候,先直接scan第一个segment,如果已经过期,则直接回收里面全部的数据,然后继续处理后面的segment。这样后台scan的时候,只需要扫描少量的数据,而不是全部的key-value。
-
Maximize metadata sharing for economy。Segcache根据TTL来对对象进行分配,作为一个个segment保存。Segment大小约为1MB,使用类似log-structured的方式来写入数据。这样,比起slab那样根据size来将对象归类的,能够尽量避免内存碎片,提高内存利用率。在hash table的实现上,其使用object-chained的方式。但是每个hash bucket是8个solts,而不是1个。这样因为在小对象的情况下,hash table之类的结构本身带来的开销也很大。使用组/bucket的方式而不是使用单个的方式可以减少这些结构的元数据的量。另外在object metadata上,其基本思路是使用sharing的方式:在一个segment内的对象使用同样的create time数据;在一个hash bucket内部的对象使用同样的 last-access timestamp, spinlock, cas value, 以及 hash pointer等。
-
Perform macro management。对于in-memory key-value的,如何在内存使用达到一个阈值的时候驱逐出合适的数据回收空间也是一个重要的内容。和前面处理TTL类似,segcache驱逐数据的时候也是segment粒度进行的。这个方式一个问题是segment驱逐的粒度比较大,可能导致比较“热”的数据被驱逐。Segcache引入来一个merge-based eviction的方式。在驱逐segments的时候,将其中访问可能性更高的读取出来合并到新的segment(s),
The segments merged during each eviction are always from a single TTL bucket. Within this bucket, Segcache merges the first N consecutive, un-expired, and un-merged (in current iteration) segments. The new segment created from the eviction inherits the creation time of the oldest evicted segment.这样剩下的问题就是如何发现访问可能性比较大的对象。这里没有使用count-min sketch之类的结构,因为其对大量的访问不频繁的数据并不友好。Segcache的做法是在hash table内一起保存了一个1byte的
approximate and smoothed frequency counter (ASFC)。ASFC分为两个部分,在其frequency小于16的时候(4bit),计数每次请求加1。超过了之后使用当前计数的倒数作为概率加1。另外每个hash bucket里面记录了一个last access timetamp,Segcache会通过这个时间戳来限制每秒最多给frequency counter加上1,以此来避免一些请求突发造成的影响。另外frequency counter不能一致增加,需要一种aging/老化的策略。常见的老化的策略比如dynamic aging, or window-based frequency。Segcache使用的方式在驱逐操作的时候,会对保留对象的计数重置处理。
0x12 评估
这里的具体内容可以参看[2].
参考
- Evolution of Development Priorities in Key-value Stores Serving Large-scale Applications: The RocksDB Experience, FAST ‘21.
- Segcache: a memory-efficient and scalable in-memory key-value cache for small objects, NSDI ‘21.
