YugabyteDB: A Distributed SQL Database
0x00 基本架构
YugebyteDB,YDB,也是一个开源的NewSQL的设计,和前面的CockroachDB有很多类型的地方,也有很多不同的地方。YDB和CRDB、TiDB之类的一样,总的来说还是模仿F1和Spanner的一个设计,总体架构上也分为实现SQL功能的查询层,YDB这部分称之为Query Layer,实现分布式存储功能的存储层,YDB这部分称之为DocDB。不同的是,YDB查询层和存储层部署的时候就是在同样的节点上面的,没有进行物理上的分离。YDB中对于一个table,也是划分为若干的tablet来保存,划分的方式只是range or hash的方式,一个tablet包含不同的一些部分。在YDB分布式事务的实现也是使用HLC,使用MVCC的方式,实现snapshot和serializable的隔离级别。YugabyteDB的一些特点:
-
YDB使用的在实现上使用了C/C++,理论上可以比一些使用Golang的有更好的实现上的一些优化空间?在Query Layer,支持兼容PostgreSQL的SQL语言外,还支持Cassandra使用的一种CQL。YDB也就是不仅仅支持SQL的模型,还支持文档的模型。兼容PostgreSQL是因为SQL相关的实现好像就是直接从PostgreSQL改来的。总的查询相关的称之为YQL。存储层则使用了RocksDB作为存储。YDB查询层和存储层实际上是部署在一起的,部署在一起称之为Tablet Server。这个是和其它类型数据库一个不同的地方。其特点也可以在下面的关于事务的部分看到。
-
YDB中无论是SQL的模型还是文档的模型,最后都会被表示为Key-Value的形势保存到RocksDB中。其编码KV到方式如下图。Key中包含了3个部分,DocKey子部分包含一个16bit的hash,这个16bit的hash也涉及到YDB一个设计特点。以及主键key,可能使用hash划分 orrang划分的方式。另外SubKey部分对应到tuple中的列。最好的部分为hybrid time 加上write id,这个write id作用在后面会提到。YDB在使用RocksDB的时候只是简单的利用了其key-value存储的功能,好像其持久化保证的WAL,以及事务都不需要,有YDB自己来保证。
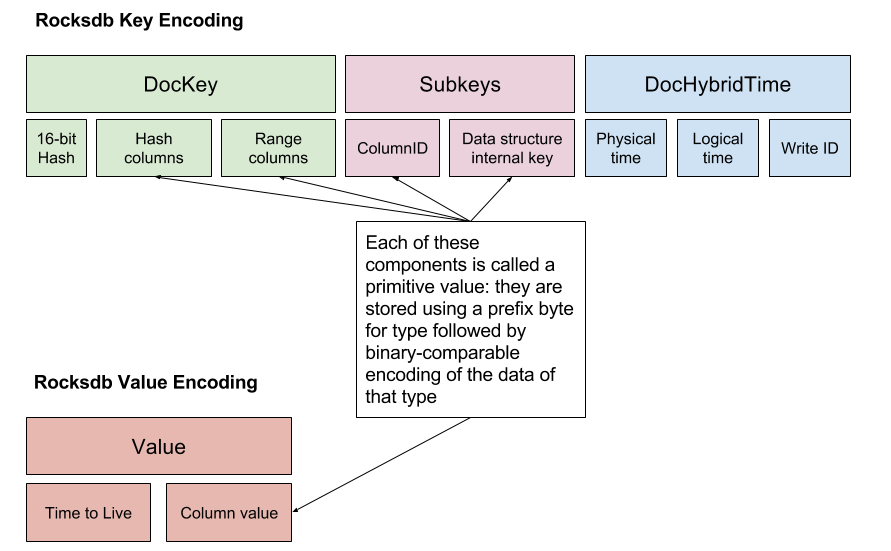
-
这里YDB的一个设计特点是其tuple中每个列都会对应到一个key-value,和一般整个tuple作为一个value的方式不同。可以猜测一下其优点是更新的时候可能可以选择更新,读取部分数据时候额外开销更小,而缺点是可能导致保存的数据量变大,要读取全部的数据时候开销增加。存储数据量可以利用RocksDB的前缀压缩的功能,可能实际上带来的开销不会很大。另外key前面16bit的hash表明了YDB涉及的时候,即使是range分区的方式,也是先使用hash的方式讲整个tablet partition到一定数量的分区,如何在划分为tablet。为一个两层的划分方式。其优点可以看得出来,在一个CRDB和YDB对比的blog[3]中也有提到,hash的优点是在处理一些热点问题时候会有明显的优势;在写入顺序的workload中,其能力上限会明显高于只使用range分区的方式,只使用range分区的方式,顺序写入数据一般有个能力上限,而这个上限基本上就是单机的能力。Hash + range的方式的话scan的性能很显然是很难比得上只使用range的。
0x01 Two Layers
YDB的一个特点是在Query Layer支持多种的协议,兼容PostgreSQL和Cassandra。其查询部分的功能实现为YQL,和存储部分的DocDB部署在同一个TServer中,YDB关于Query Layer除了同时支持PostgreSQL的SQL以及Cassandra的CQL,相关的资料并没有很多的描述。在CRDB和YDB一篇对比的文章[3]中,也将到了YDB的查询层的一些问题。CRDB的查询层实现为一个 fully-distributed SQL engine,包含了为分布式查询做的各种优化。而YDB直接从PostgreSQL改,为其增加了访问存储层的LSM-Tree的实现,这些访问方式实现在下层的DocDB distributed KV之上。CRDB将其描述为在一个巨大KV系统上实现单体数据库,而不是一个分布式数据库(Rather than a distributed SQL database, Yugabyte can be more accurately described as a monolithic SQL database on top of a distributed KV database).
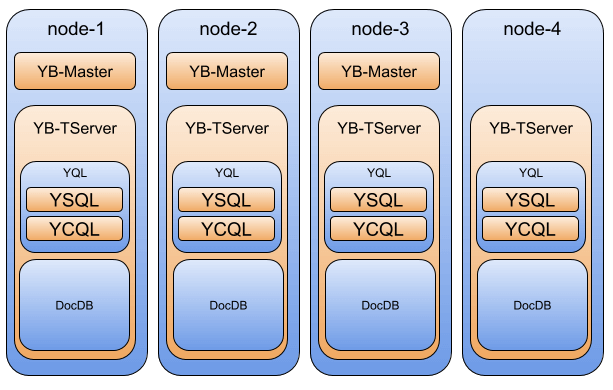
YDB的Storage Layer,在YDB的文档中,Storage Layer部分的主要功能为事务、sharding、复制和存储。其中存储基本上是利用了RocksDB,且只利用了其基本的Key-Value功能。保存的Key-Value中数据的编码方式如上所述。YDB很多的事务逻辑实现在存储层,但分布式事务和YQL部分也是有很大关系的。如下面分布式事务部分写入操作的图所示,Transition Manager部分处于YQL中,负责处理整个分布式事务的推进。在数据复制方面基本的复制使用的为raft协议,完成在tablet层面的多副本,除此之外,引入xCluster replication功能来实现在不同YDB集群的复制,有特点的是这个xCluster复制支持单向的master-follwer方式的单向复制,也支持双向的复制。使用跨集群的复制看上去会加上不少的限制。YDB还引入了一个read replicas的功能,其拓展了raft的功能引入了一个observer的角色(在其它地方也有称之为learner的),这个observer只是负责接收写入的数据,但不能处理写入操作。复制到read replicas是异步的,不会增加写入的延迟,从read replcias可能读取到较老的数据,但是比eventual consistency的要方便处理。
0x02 分布式事务
前面提到的,YDB和CRDB一样,在分布式事务执行过程中,基本方式是使用Percolator的2PC方式。同样地,YDB开始写入的记录为一种处于未提交状态的事务,称之为provisional records,而一般的记录称之为regular(permanent) records。和CRDB不同的是,YDB一个tablet保存的时候,provisional records的数据和regular的数据保存在不同的RocksDB实例上面。其在KV上存储的格式如下图所示。将临时记录分开保存的一个好处:一是可以方便scan出临时的记录,在清除abort的事务的数据时候更有效;另外一个优点是在read操作的时候,对于provisional records的数据,要求的处理方式是不同的,在不同区域保存一定程度上可以简化操作的垃圾;还有一个优点就是在不同的RocksDB实例可以针对临时数据和一般数据使用不同的storage、compaction和flush的策略。
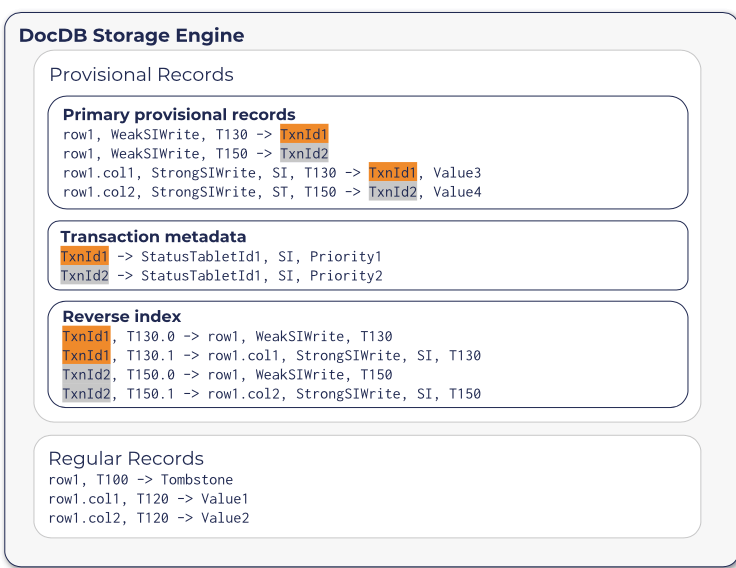
YDB中provisional的记录有3种不同的类型,这些记录保存到RocksDB中,会有一个1byte的prefix。YDB中也会有一个primary key,写入为provisional记录的时候,其格式如上图所示,这行数据同时作为一个可以被撤销(revocable)的锁。以在snapshot隔离级别下,将一行数据的一列数据设置为一个值的时候,其会在provisional记录部分中写入两行数据数据(这个事务的时间戳为1516847525206000,事务ID为 7c98406e-2373-499d-88c2-25d72a4a178c,写入数据值为value1)。对于row写入的记录锁类型为WeakSIWrite,而对于对应的列写入的为锁类型为StrongSIWrite。
row, WeakSIWrite, 1516847525206000 -> 7c98406e-2373-499d-88c2-25d72a4a178c
row, column, StrongSIWrite, 1516847525206000 -> 7c98406e-2373-499d-88c2-25d72a4a178c, value1
另外一种类型的provisional记录为事务元数据的记录,以事务ID为key,值包含了记录了事务的状态的StatusTabletId、事务的隔离级别以及优先级等。需要包含一个StatusTabletId字段的原因是在hash分区方式的时候,事务ID对应到那个tablet是不确定了,这里使用直接记录的方式。还有就是reverse idnex类型的记录,以事务ID + HybridTime时间戳 + write ID作为key,value为primary provisional 记录的 key。使用这个记录可以有事务ID定位到primary provisional keys。加上write ID是因为一个事务对应provisional记录有多个,示意如上图。YDB中事务状态的记录不是使用直接记录到primary record中的方式,而是写入到一个单独的区域,保存的方式使用DocDB本身来保存。这个状态记录以事务ID为key,value中记录了事务的status((pending, committed, or aborted),事务的commit hybrid timestamp以及参与了这个事务的tablets的ID列表。后面两个字段,在事务没有commit的时候为空。
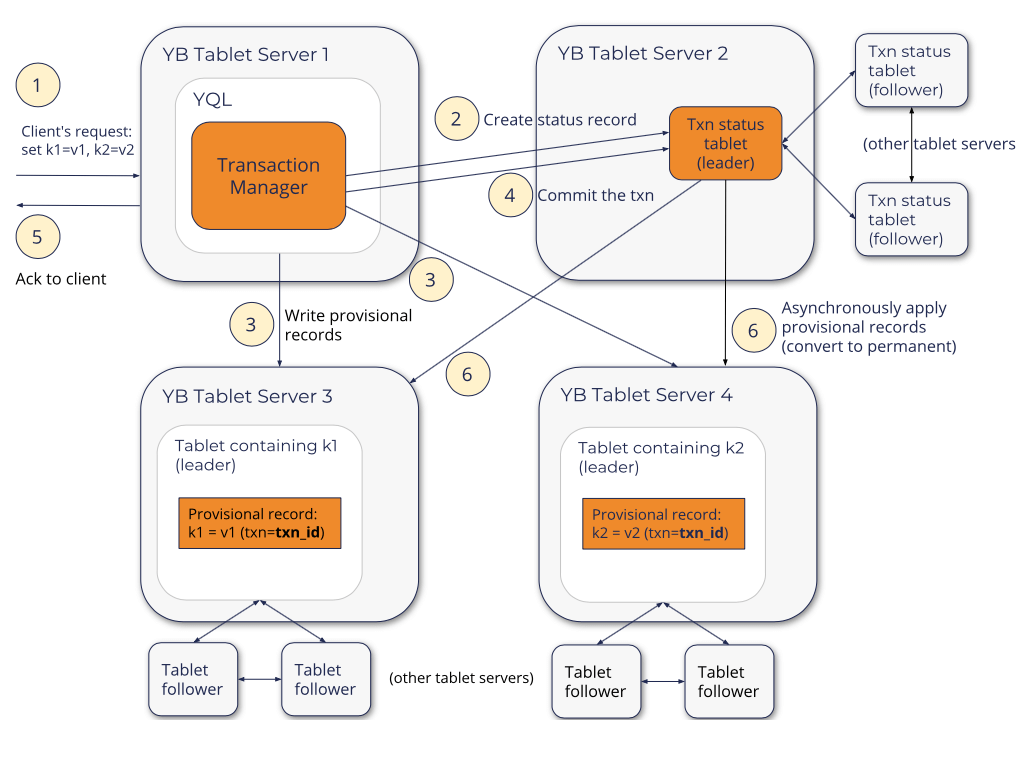
YDB中RW事务执行的基本流程如上图所示,以如下的一个简单的write-only的事务为例。事务开始的时候以赋予这个事务一个全局唯一的ID,然后选择一个tablet来保存这个事务状态的记录,然后在选择的tablet中创建一个事务status记录开始。选择tablet的时候可以选择这个tablet的Raft group的leader就和使用transaction manager在同一个节点上面的,这样可以降低Raft操作带来的延迟。后面进入一个2PC的过程:
- 第一步写入provisional的记录,记录中包含事务ID、value和provisional hybrid timestamp的数据。其中provisional hybrid timestamp为一个临时性的timestamp,一般不会是最终的commit timestamp。在写入provisional记录的过程中,遇到冲突的时候想要abort事务 或者是 重启事务。在完成provisional记录的写入时候,可以commit的情况下,通过原子地将事务状态记录改为committed来完成事务的提交,之前写入的provisional记录也变成了事实上committed的记录,完成这个时候就可以返回结果给client。
- 后面将provisional记录改成regular记录为后台异步进行。这部分的套路基本上是Percolator的模式。后台异步修改记录的时候,YDB通过写入一种特殊的apply 格式的记录到Reft Group中,这个记录包含了事务id和commit ts的信息。Raft在apply这样的‘apply’记录的时候,会找到之前写入的provisional记录,写入regular的记录并移除掉provisional的记录。完成了这些数据的转换之后,就可以删除事务状态的记录。
START TRANSACTION;
UPDATE t1 SET v = 'v1' WHERE k = 'k1';
UPDATE t2 SET v = 'v2' WHERE k = 'k2';
COMMIT;
对于只读的事务,在事务开始的时候获取一个ht_read,ht read可以选择YQL engine所在的tablet server,也可以选择一个相关tablet的saft time,选择后者可以减少一些可能的等待时间。因为YDB使用的也是HLC的时间戳方案,同样要求处理一个不确定区间的问题。另外YDB使用Percolator的2PC模式同样也可能遇到不能确定是否committed的值,也要通过查询事务状态处理,在必要的时候要写着事务commit or 尝试abort事务 or 清理abort数据的操作。YDB定义了一个global_limit,这个global time的值为physical_time + max_clock_skew。读取数据的时候要求等待这个ht read变成saft time,然后在执行读取的逻辑:
- 对于ht_record ≤ ht_read的情况,则数据对事务可见;对于ht_record > definitely_future_ht的情况,则对该事务不可见。这个definitely_future_ht第一个执行可以理解为就是global_limit;对于在ht_read < ht_record ≤ definitely_future_ht之间的,则不能确定,需要讲事务ht read设置为ht record之后在重启事务。重启操作可能导致的是事务过多次的重启,YDB的解决方式是DocDB层面返回给SQL层一个tablet相关的local_limit,值为这个tablet的saft time,保证了低于这个local limit的数据不会是在事务重启之后写入的,后面重试事务的时候,其hr record大于这个local limit肯定就是对当前事务不可见的,重试的definitely_future_ht 设置为 min (global_limit, local_limittablet)。
Saft time是YDB中的一个定义,以YDB中事务开始赋予的时间戳ht read的获取方式相关。先考虑事务在一个tablet执行的情况。为了满足一致性读的语义,要求这个事务读取条件的记录不会再有小于这个时间戳的更新。在leader发生切换的时候,为了避免后面leader的赋予写事务一个可能导致破坏一致性读语义的时间戳,选择这个ht read的一种方式时选择 last committed record的hybrid time,就可以前面的要求。这种方式的一个问题时如果一个tablet最近没有更新操作的话,这个ht_read就相当于被暂停了,可能导致一些问题(比如有设置TTL的情况)。为了解决这些问题,YDB在一个raft group中,引入了一个hybrid time leader leases。
-
这个hybrid time leader leases和raft group中leader的lease是一个类似的概念。在leader给follerws发送AppendEntries请求 or 心跳请求的时候,会带上一个hybrid time lease expiration time,简称
ht_lease_exp,这个ht lease exp由目前的hybrid time加上一个值计算而来,比如目前的hybrid timestmap + 2s。Followes在收到请求之后,会回复leader一个承诺就是不会在赋予后面的事务 <= ht_lease_exp 的时间戳。这样就可以通过raft的方式维护了majority-replicated的hybrid timestmap watermark。 -
在引入了这个hybrid time leader leases之后,定义当前的majority-replicated hybrid time leader lease过期的时间为
replicated_ht_lease_exp。这样对于读取请求, safe timestamp可以根据如下的选择如下几个中最大的一个:1. raft中最后一个committed的entry的hybrid time;2. 如果raft log中存在没有commit的log,选择地一个没有commit的log的hybrid time减去一个 ε (ε is the smallest possible difference in hybrid time) 和 replicated_ht_lease_exp 中较小的一个;3. 如果不存在没有committed的log,选择当前的hybrid time和replicated_ht_lease_exp 中最小的一个。可以看出,最后一个提交了的entry的hybrid time作为读取的ht read总是ok的。
前面讨论的是只有一个tablet参与的情况,如果设计到tablet参与的事务,如果ht read选择了其中一个的safe time,在读取另外的tablets的数据的时候,需要等到这个选择的ht read在另外的tablets上也变成safe time。还有的一个问题就是如何支持从follwer读取,只从raft角度来看,follwer读已经有了一个解决方案。YBD这里选择的方式是从follwer读取可能读取的过时的一些数据,有用户来进行选择。Follower同样也会设计到一个safe time的问题,但是前面的safe time计算的方式只能在raft group的leader上使用,YBD的解决方式时在AppendEntries的时候就带上这个safe time的信息,这种方式从follower读不一定能读取到最小的数据。
参考
- YugebyteDB Transactional IO path: https://docs.yugabyte.com/latest/architecture/transactions/transactional-io-path/.
- YugebyteDB Single Row Transaction: https://docs.yugabyte.com/latest/architecture/transactions/single-row-transactions/.
- Yugabyte vs CockroachDB: https://www.cockroachlabs.com/blog/unpacking-competitive-benchmarks/.
