Distributed Transaction Without Centralized Sequencer/TSO
0x00 Spanner: Google’s Globally Distributed Database
这里总结的是分布式事务在没有一个中心化的Sequencer/TSO下如何实现。关于这个部分,影响最大的也是来自Google的一篇paper,即Spanner在OSDI ‘12上面发表的这篇。其核心思路是在引入了一个不确定的时间区间,然后通过使用atomic clock来尽可能得降低这个不确定的时间区间并保证这个不确定的区间在一个确定的bound内。差值在这个bound之外的timestamp,Spanner就可以直接知道timestamp之间的先后关系,在这个bound之内的,Spanner会在实现上处理这个问题,从而实现了完全分布式的时钟,满足linearizability。Spanner数据保存到分布式文件系统之上,这个和一些开源实现直接使用本地的KV Store存储数据不同。同样其也需要讲这个的key range拆分为更小的的部分,称之为tablet。每个tablet对应到一个paxos group来实现多个副本的存储。在这样的基本架构之上,对于读写事务:
- 一个paxos group中会有一个leader,处理paxos的一些逻辑之外,其还会维护一个lock table和实现transaction manager的一些功能,这个和事务功能相关。事务读取操作的时候,会讲读取请求发送到对应group的leader,加上一个read lock之后如何读取数据。Lock需要知道放弃事务的client还是存活的,所以会定期发送keepalive的消息来告知leaders事务还是存活的。数据的写入都是先buffer在本地。在commit的时候,使用2PC提交的方式进行:1. Spanner中一个事务会选择一个paxos group的leader作为Coordinator,协调者,然后向所有的所有参与的paxos group的leader发送一个commit的消息,消息中包含选择的协调者的ID以及要写入的数据。非协调者的leader在收到消息之后,先请求write locks,然后选择一个prepare timestamp,通过paxos写入一个prepare record日志。后面每个参与者会通知coordinator其选择的prepare timestamp。选择这个prepare timestamp都是要求必须大于之前赋予其它事务的timestamp,即严格增加的特性。也可以看出Spanner的一个特点是一部分协调的工作是client来完成,client直接广播消息,这个应该是考虑到spanner为广域网/全球部署设计的。
- Coordinator同样会申请write locks,但是不会处理prepare phase。在收到其它leader的消息之后,选择一个timestamp作为commit的时间戳。这个commit timestamp必须要 >= 其它leaders选择prepare tiestamp,也要求大于此时它收到过的commit消息时刻的TT.now().latest,还要大于其赋予之前事务的任何timestamp。Coordinator通过paxos写入一个commit记录。此时,commit事务不能马上apply,来完成对事务的commit,还需要一个等待的操作,需要等到
TT.after(s)成立之后。之后Coordinator发送commit timestamp给client和其它的participant leaders。每个participant leader在收到这个消息之后,写log记录下事务的结果。然后使用相同的timestamp来apply操作,并释放锁。
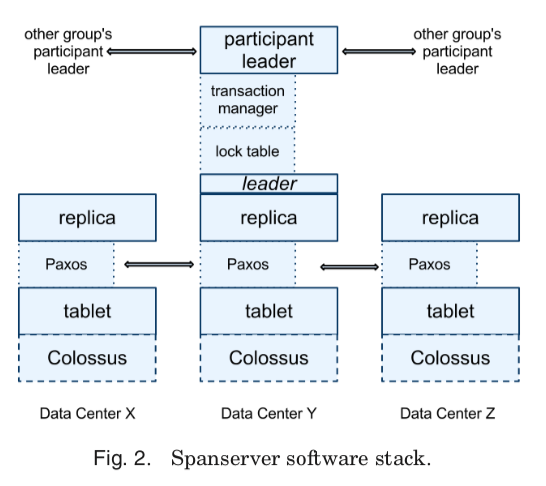
Spanner的读写事务中读写操作都需要加上对应的locks,这个应该是为了处理读写事务之间的读写冲突问题。而其另外支持的read-only事务和snapshot -read,都是不需要加锁的,其利用MVCC来实现读写事务和只读事务之间的读写不相互阻塞。这样Timestamp管理是保证事务正确性的重要内容。Paxos group中的leader通过lease来维护一个和不会给后面可能的leader切换之后重叠的lease interval,默认情况下每个lease长度为10s,在一次写入操作时候默认被续约。Leader切换之后,后面的leader需要等待前面leader最大的租约内的时间戳S-max满足TT.after(smax)成立。对于一个写入事务,其使用2阶段锁的方式,timestamp可以在所有锁被获取之后、任何锁被释放之前赋予。Spanner关于tiemstamp更多的一些东西:
- Spanner是满足external-consistency的系统,可以保证后面开始的事务可以看到先提交的事务的修改。对于tiemstamp,就要求如果一个事务T2开始在另外一个事务T1 commit之后,要求T2的commit时间戳必须小于T1的commit时间戳。即一个事务ti start event和commit event的绝对时间为ti-start-abs-ts和ti-commit-abs-ts。即这样要求t1-commit-abs-ts < t2-start-abs-ts。一个coordinator为一个事务T赋予一个commit timestamp的时候,要求这个时间戳不能小于TT.now().lastest,即目前可能时间的最大值。如何通过Commit Wait的操作,来使得不同事务之间的commit ts是一定满足其先后顺序的。
- 再来看Spanner中一个时间戳对于读的影响。Spanner每个replica维护了一个safe-ts,记录了每个副本up-to-date的最大的timestamp。小于这个safe-te的读取操作,这个replica就是可以直接读取的。这个safe-ts定义为min(safe-paxos-ts, safe-tm-ts),即safe-paxos-ts定于为已经apply的最大的写入操作tiemstamp,而 safe-tm-ts记为transaction mamager的safe time。safe-tm-ts在存在prepared事务的情况下,即2PC第一个执行完成的情况下,定义为∞。因为收到prepared但是没有commit事务的影响,safe time不能确定,但是可以根据papered的事务的prepare tiemstamp获取一个下界,就是这些prepared事务中最小的prepare timestamp - 1。读取的时候,对应的read ts如果小于这个的话,就可以直接读取。此外Spanner每个paxos group记录了一个last-ts,如果没有prepared的事务,则为最后一次写入操作的tiemstamp。读取的时候也可以通过这个判断可见性。
- 对于一个Read-Only的事务,赋予一个时间戳read-ts,然后只想以这个ts为基准的snapshot read。如果确定这个read-ts是一个值的考虑的问题。如果赋予这个这个ts为TT.now().latest,是可以满足正确性要求的,但是可能由于写入操作而操作需要这个读操作等待,另外一个选择最新的时间戳,可能从非leader副本中读取的时候,可能这个副本还没有完整获取到最新的数据。总结一下,Read-Only的事务,前面提及到的safe-paxos-ts是为了处理从非leader副本中正确读取, 而safe-tm-ts发表是为了处理读写事务时间上的冲突可能造成阻塞。
Paper中还提到safe-tm-ts的一些问题,即如果存在一个prepared的事务,就会导致safe-ts无法推进,后面的读取操作就无法进行,但是这个时间戳和前面的写操作不一定冲突。优化这个问题,Spanner使用的一个方法维护一个fine-grained 的从key ranges 到prepared-transaction timestamps的映射,如果不是在range内,则不会是冲突的。另外的一个优化是对last-ts,一个事物刚刚commit的情况下,可能仍然导致读被delay。这个优化的方式引入一个细粒度的key ranges 到 commit timestamps映射,避免一些false conflict。另外是对于safe-paxos-ts的,对safe-paxos-ts的一个优化是在没有写入的情况下,这个时间就不能往前推进,同样会导致阻塞。Spanner的方式是维护一个 MinNextTS(n),为到paxos sequence number到n-1是最小可能赋予的时间戳,即后面写入的时候,会赋予其比这个更大的时间戳。而follwer得到这个消息的时候,可以直接讲自己的时间戳推进到这个MinNextTS(n) − 1。对于单个paxos来说,这个MinNextTS要保证会赋予在这个leader的lease访问之内。
0x01 CockroachDB: The Resilient Geo-Distributed SQL Database
CockroachDB,CRDB,是开源实现的分布式数据库系统中最有名的之一,好像是第一个使用HLC来模仿实现Spanner的事务模式的数据库。CRDB标准的2PC方式的事务实现,来自Percolator和Spanner,不过时钟这里使用了HLC。但是CRDB在基础的版本之外,还加入了很多的优化实现,比如Parallel Commit、Transaction Pipelining、1PC、Non-blocking Transactions等。CRDB基本的事务的2PC实现方式:
- 第一步为writing,写入可能是写入事务状态记录,这个事务状态记录也同样是写入到下层的KV系统内。事务状态包括
PENDING,STAGING,COMMITTED, orABORTED。另外一些CRDB都称之为locks,对于内存中不持久化的Unreplicated Locks,一般和并发控制相关。另外就是临时写入的数据,称之为write intent。CRDB也将其当作是一种lock,Replicated Locks。Write intents写入之后,如果检查发现了新数据的commit,则事务可能会重启,也可能因为冲突而导致事务abort。 - 第二步为commit,先就是检查事务的状态记录,在可以commit的情况下将其改为committed的状态,则完成事务commit,此时即可返回。异步进入后面的cleanup过程,讲之前写入的write intent数据变成一般的数据。这里CRDB做了Parallel Commit,优化到在第一步完成之后就可以返回给client。
CockroachDB使用的MVCC的并发控制方式,在这里使用的时间为HLC。HLC有物理时钟和逻辑时钟两部分组成,这样就可以保证HLC的值总是大于等于wall time。使用这个HLC的一个问题就是如果保证不同节点上面的时钟的偏差在一个bound内。CRDB引入一些操作尽量避免出现这些问题:一个是range lease包含了一个start和end的时间戳,leaseholder只能在这个范围内服务。一个range的不同的lease是没有相交范围的。一个 Range’s Raft log的写入会带上range lease的序列号。复制成功的时候,这个序列号被再次检查,是否对得上currently active lease。如果对不上写入会被拒绝。如果在不能保证这个max offset在一个区间内的,CRDB一些操作就不能满足linearizability,但是还是可以满足serializability(While serializable consistency is maintained regardless of clock skew, skew outside the configured clock offset bounds can result in violations of single-key linearizability between causally dependent transactions.)。为了尽可能地减少的这种情况,CRDB会周期性地检查 clock’s offset,超过配置的最大值的80%的时候,会让一个节点self-terminates的方式来处理。
- CRDB中为一个range赋予一个raft group来实现这个range内的更新都复制到多个副本。一个range leaseholder的节点才可能对这个range进行读写操作。一般情况下,CRDB中leaseholder就是raft group中的leader,但是和raft protocol中的leader lease并不完全是一回事,是两个不同的角色,其可能不是同一个节点。而且这个节点的写入知发送到raft group的leader来进行写入的(A single node in the Raft group acts as the leaseholder, which is the only node that can serve reads or propose writes to the Raft group leader ),读取的时候直接从leaseholder的节点获取,不用经过raft。如果这两个节点不同,在lease renewal的时候会尝试讲这两个角色转移到一个节点上面。引入leaseholder的主要是为了解决一个group中可以提供读写的节点的lease在HLC时间上是相互不相交的?
- CRDB使用Follower Reads来实现一些只读事务的操作,需要在SQL加上一些指示性的东西。满足Follower Reads要满足这样的一些条件,一个是对于一个时间戳为ts的事务,可以读取的数据不会在后面被更新,另外一个就是要去这个non-leaseholder replica已经有了这些数据。也就是要去满足non-leaseholder replica执行一个时间戳为ts的只读事务的时候,leaseholder不能在执行比这个ts还还要小的写入操作,另外就是这个non-leaseholder replica 的raft log的prefix要足够支持执行这个事务。为了满足这些条件,每个leaseholder会记录下进行中的操作,并周期性地通知一个closed timestamp,表示不会在接受小于这个closed timestamp的写入事务,
CRDB和下面的YDB在intent/provisional数据和事务状态格式数据上存在一些不同和区别,可以看出来其设计上的思路。在CRDB中,一个事务ID为一个UUID,保存到事务状态记录的时候,状态可能为PENDING, STAGING, ABORTED, or COMMITTED,另外为一个K/V key。这个保存事务状态记录的时候,选择的第一个range的start key作为这个事务的anchor key的一部分,然后在后面拼接事务相关的suffix和事务ID。这样保存的时候就讲range内这类数据聚集到了一次。另外写入write intent的时候,其key就是按照CRDB编码方式编码而来的key,而一般的数据为key+timetamp。这样一个key写入intent的时候,只能同时写入一个,达到了lock的效果。保存的值为关于这个事务的一些元数据,比如事务的ID、时间戳、epoch和优先级等信息,另外一个写入的数据为key1 加上选择的timestamp作为key,value为实际要保存的数据。这样的一个好处是,事务要commit的时候,如果最终选择commit ts就是这里写入时候选择的ts,知需要讲不带version的key删除即可。这里和下面的YDB实现上有些不同。
key0 + version0 -> valueOfKey0
key1 -> Metdata{...}
key1 + intent-ts -> valueOfKey01
0x02 Transaction in YugebyteDB
YugebyteD的分布式事务总体上和大体的方式上,也是使用CockroachDB的思路。YDB分布式事务的实现也是使用HLC,使用MVCC的方式,实现snapshot和serializable的隔离级别,模仿Spanner方式一种开源实现。当然和CRDB在实现上还是存在很多的差别。这里只谈它在Doc中提到的一些关于分布式事务的内容: 和CRDB一样,在分布式事务执行过程中,同样开始写入的记录为一种处于未提交状态的事务,称之为 provisional records,而一般的记录称之为regular(permanent) records。和CRDB不同的是,YDB一个tablet保存的时候,provisional records的数据和regular的数据保存在不同的RocksDB实例上面。其在KV上存储的格式如下图所示:
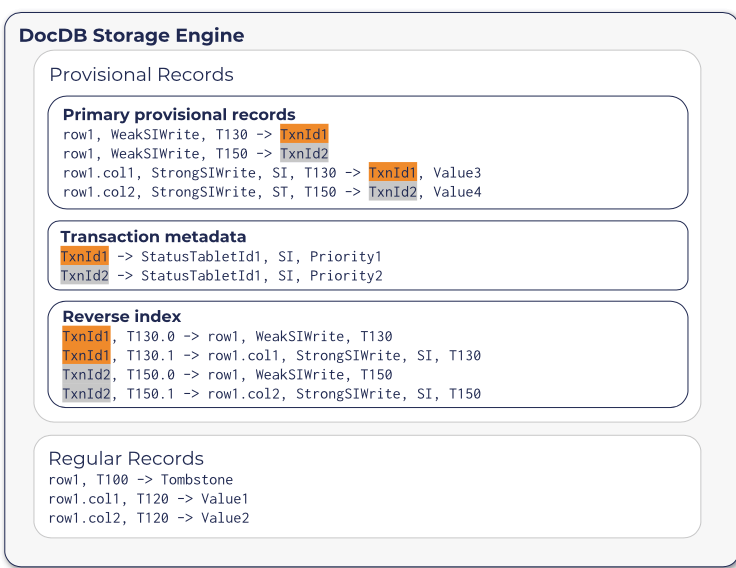
其中一种类型的provisional记录为事务元数据的记录,以事务ID为key,值包含了记录了事务的状态的StatusTabletId、事务的隔离级别以及优先级等。需要包含一个StatusTabletId字段的原因是在hash分区方式的时候,事务ID对应到那个tablet是不确定了,这里使用直接记录的方式。还有就是reverse idnex类型的记录,以事务ID + HybridTime时间戳 + write ID作为key,value为primary provisional 记录的 key。使用这个记录可以有事务ID定位到primary provisional keys。加上write ID是因为一个事务对应primary provision记录有多个,示意如上图。YDB中RW事务执行的基本流程,以如下的一个简单的write-only的事务为例:事务开始的时候以赋予这个事务一个全局唯一的ID,然后选择一个tablet来保存这个事务状态的记录,然后在选择的tablet中创建一个事务status记录开始,后面进入一个2PC的过程:
- 第一步写入provisional的记录,记录中包含事务ID、value和provisional hybrid timestamp的数据。其中provisional hybrid timestamp为一个临时性的timestamp,一般不会是最终的commit timestamp。在写入provisional记录的过程中,遇到冲突的时候想要abort事务 或者是 重启事务。在完成provisional记录的写入时候,可以commit的情况下,通过原子地将事务状态记录改为committed来完成事务的提交,之前写入的provisional记录也变成了事实上committed的记录,完成这个时候就可以返回结果给client。
- 后面将provisional记录改成regular记录为后台异步进行。这部分的套路基本上是Percolator的模式。后台异步修改记录的时候,YDB通过写入一种特殊的apply 格式的记录到Reft Group中,这个记录包含了事务id和commit ts的信息。Raft在apply这样的‘apply’记录的时候,会找到之前写入的provisional记录,写入regular的记录并移除掉provisional的记录。完成了这些数据的转换之后,就可以删除事务状态的记录。
START TRANSACTION;
UPDATE t1 SET v = 'v1' WHERE k = 'k1';
UPDATE t2 SET v = 'v2' WHERE k = 'k2';
COMMIT;
对于只读的事务,在事务开始的时候获取一个ht_read,ht read可以选择YQL engine所在的tablet server,也可以选择一个相关tablet的saft time。因为YDB使用的也是HLC的时间戳方案,同样要求处理一个不确定区间的问题。另外YDB使用Percolator的2PC模式同样也可能遇到不能确定是否committed的值,也要通过查询事务状态处理,在必要的时候要写着事务commit or 尝试abort事务 or 清理abort数据的操作。YDB定义了一个global_limit,这个global time的值为physical_time + max_clock_skew。读取数据的时候要求等待这个ht read变成saft time,然后在执行读取的逻辑。这个判断的逻辑基本是和CRDB是一样的:
- 对于只读事务先考虑事务在一个tablet执行的情况。为了满足一致性读的语义,要求这个事务读取条件的记录不会再有小于这个时间戳的更新。在leader发生切换的时候,为了避免后面leader的赋予写事务一个可能导致破坏一致性读语义的时间戳,选择这个ht read的一种方式时选择 last committed record的hybrid time,就可以前面的要求。这种方式的一个问题时如果一个tablet最近没有更新操作的话,这个ht_read就相当于被暂停了,可能导致一些问题(比如有设置TTL的情况)。为了解决这些问题,YDB在一个raft group中,引入了一个hybrid time leader leases。这个ht lease exp由目前的hybrid time加上一个值计算而来,比如目前的hybrid timestmap + 2s。Followes在收到请求之后,会回复leader一个承诺就是不会在赋予后面的事务 <= ht_lease_exp 的时间戳。这样就可以通过raft的方式维护了majority-replicated的hybrid timestmap watermark。
- 在引入了这个hybrid time leader leases之后,定义当前的majority-replicated hybrid time leader lease过期的时间为
replicated_ht_lease_exp。这样对于读取请求, safe timestamp可以根据如下的选择如下几个中最大的一个:1. raft中最后一个committed的entry的hybrid time;2. 如果raft log中存在没有commit的log,选择地一个没有commit的log的hybrid time减去一个 ε (ε is the smallest possible difference in hybrid time) 和 replicated_ht_lease_exp 中较小的一个;3. 如果不存在没有committed的log,选择当前的hybrid time和replicated_ht_lease_exp 中最小的一个。可以看出,最后一个提交了的entry的hybrid time作为读取的ht read总是ok的。
前面讨论的是只有一个tablet参与的情况,如果设计到tablet参与的事务,如果ht read选择了其中一个的safe time,在读取另外的tablets的数据的时候,需要等到这个选择的ht read在另外的tablets上也变成safe time。还有的一个问题就是如何支持从follwer读取,只从raft角度来看,follwer读已经有了一个解决方案。YBD这里选择的方式是从follwer读取可能读取的过时的一些数据,有用户来进行选择。
参考
- Spanner: Google’s Globally Distributed Database, OSDI ‘12.
- CockroachDB: The Resilient Geo-Distributed SQL Database, SIGMOD ‘20.
- Transaction Layer: https://www.cockroachlabs.com/docs/stable/architecture/transaction-layer.html
- Living Without Atomic Clocks: https://www.cockroachlabs.com/blog/living-without-atomic-clocks/.
- YugebyteDB Transactional IO path: https://docs.yugabyte.com/latest/architecture/transactions/transactional-io-path/.
- YugebyteDB Single Row Transaction: https://docs.yugabyte.com/latest/architecture/transactions/single-row-transactions/.
