FoundationDB: A Distributed Unbundled Transactional Key Value Store
0x00 基本内容
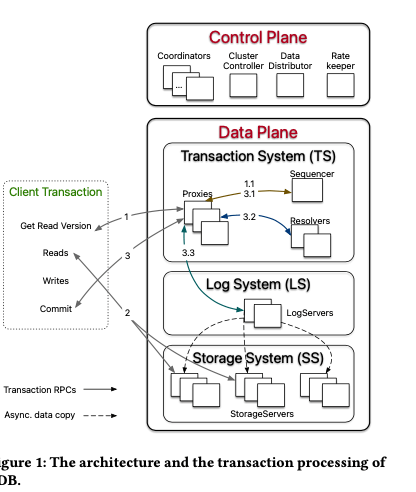
这篇paper描述了FoundationDB整体的一些设计。FoundationDB的基本架构如下。其基本架构和一般的类似相同没有很大的部分,Control Plane负责处理元数据,里面包含多个角色。比如Coordinators其作为哟个Paxos Group存在。其会选举出一个ClusterController,负责监控集群的情况,另外会创建三个进程,分别为 Sequencer, DataDistributor, 和Ratekeeper,分别处理做为一个发好器、监控storage servers的情况以及处理overload protection的问题。在Data Plane方面,这里一个特别是使用了3个组件,和类似的系统对比,多出来一个Log System,LS。LS负责保存来自TS的 Write-Ahead-Log,这个TS为transaction management system (TS),负责处理事务的逻辑。TS中也会有一个Sequencer,另外的足迹为, Proxies 和 Resolvers。TS的Sequencer负责从这里获取read version和commit version的timestamp。Proxies负责处理事务的读写和commit,resolver则主要用于处理事务之间的冲突。StorageServer为一个range分区的存储节点,存储使用的是SQLite的一个修改版本。和多数的类似系统一样,其并发控制也是使用MVCC的机制,另外FDB是没有依赖其它的外部系统的。
0x01 事务
对于一个支持分布式事务的系统来说,其事务处理的流程是一个核心的部分。在FDB中,事务处理的开始由client向一个proxy发送一个请求,获取一个read version开始,即一个read timestamp。这个read version为proxy从sequencer获取,保证每次获取的version都是递增的。在获取了这个timestamp之后,client可以直接向storage servers发送读区请求。而一个写入的数据会暂存到本地的buffer中。在后面commit的时候,将写入的数据,包括read set和write set的信息,发送到一个proxy。Proxy处理事务提交的请求,如果不能提交,向client返回abort的信息,client可以选择重试事务。
-
FDB commit的流程:1. 从sequencer获取一个commit version(Sequencer chooses the commit version advancing it at a rate of one million versions per second);2. 然后,proxy将事务commit相关的数据发送给resolver,这里使用optimistic concurrency control的方式来检查read write冲突。在resolver返回没有冲突的情况下,进入下一步,否则返回abort;3. 事务可以commit的时候,proxy将数据发送个LS来持久化数据。在所有指定的保存这个的log复制返回成功之后,proxy向sequencer报告commit version的信息,然后恢复client。SS会从LS拉去log,应用到本地形成最终的数据。另外FDB对于只读的事务,或者是快照读,其可以直接在本地commit。
-
FDB实现的隔离级别为很高的Strict Serializability。从数据库的角度来看,这里基于OCC结合MVCC的方式实现了SSI的隔离级别。从分布式系统的角度来,由于read version、commit version来自于sequencer,通过这个给出了一个全局的顺序。Sequencer在返回commit version的时候,会带上previous commit version (i.e., previous LSN) ,proxy请求reoslver的时候,除了LSN,即commit version之外,还会有previous LSN(维护这个previous的信息也会有一些麻烦?)。这样 Resolvers 和 Log- Servers就可以指导事务之间commit的一个顺序,按照这个顺序处理以实现strict serializability。Resolver的检查冲突的算法如下,其基本的方式是通过记录ranges最近的commit version,和read version对比,来检查read-write冲突。
Require: lastCommit: a map of key range → last commit version foreach range ∈ Rr do ranges = lastCommit.intersect(range) for each r ∈ ranges do if lastCommit[𝑟] > Tx.readVersion then return abort; // commit path foreach range ∈ Rw do lastCommit[range] = Tx.commitVersion return commit;
Logging Protocol
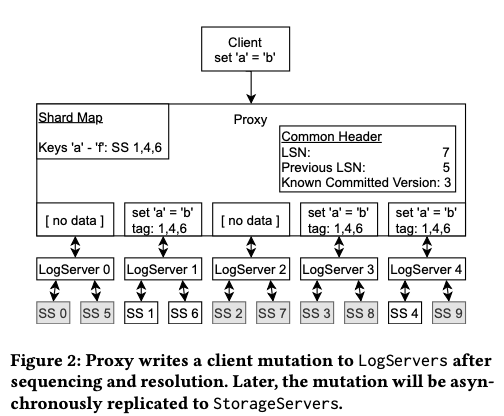
在FDB中,proxy需要提交事务的时候,需要根据一些信息来获取key属于那个range,获取有些storage servers来负责保存这些range的信息。Proxy写log的时候,会想所有的log servers发出请求,但是不同的key range有不同的preferred的log servers,只有那些key range preferred的LS才会收到完整的信息,其它的收到的会是一个空消息。一个log message会包含LSN和pre LSN,还有proxy已知的known committed version (KCV) 。Log servers在数据持久化之后回复proxy,proxy更新KCV的信息。
- 在这样的设计下面,client读取storage servers的时候,可能数据还没有拉取到数据,这个时候就需要根据read version的信息判断,并需要读取操作等待。数据持久化湿在LS做的,这样SS处理的时候就可以先暂存到内存中,然后批量地持久化。
- 在发生故障的时候,Sequencer会从Coordinators读取之前的transaction system states,并给这个states加上锁,避免有其他的sequencer同时处理recovery的流程。从之前的信息中获取Log Servers的信息之后,禁止它们继续处理请求。然后创建新的Proxies、Resolvers和LogServers。然后停止了前面的LogServers之后,Sequencer会将新的信息写入到Coordinators中,然后重新接受请求。FDB这里的恢复是通过重新创建一些系统状态来恢复。
- 另外的一些信息恢复,对于Proxies 和Resolvers 来说由于其是无状态的,处理起来比较简单。而对于LogServers,需要保证前面数据都能够正确地恢复。这里的一个核心要点是如何确定上次redo log的末尾,这个末尾称之为Recovery Version (RV),这个应该是整体的tail。另外一个Durable Version (DV)表示一个log server最大的持久化了的version,另外也会记录来自proxy的KCV的信息。如果log复制的数量为k,log servers的数量为m,则在收到超过m-k个old log server的回复之后,Sequencer可以知道previous epoch’s end version (PEV),即取这些回复中KVC最大的一个。这个PEV表示这个version之前的数据是被完整复制的,另外选择为DVs中最小的一个作为RV。对于在[𝑃𝐸𝑉 + 1,𝑅𝑉]之间,复制到目前的Log Servers。
- 在事务处理上面,FDB也引入了许多的优化。比如事务的批量处理。另外FDB也支持一些原子操作,比如atomic add、 compare-and-clear, 和set- versionstamp之类的,这些操作可以减少读取value的一些操作。
0x02 容错
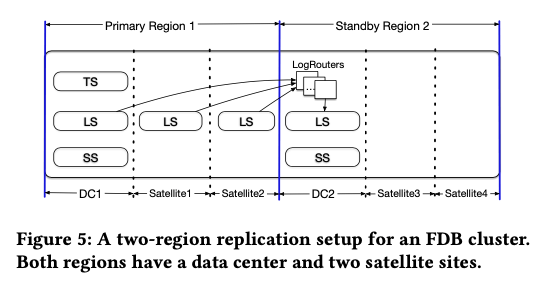
FBD复制使用多种的方式,在metadata的复制方式上,其使用Active Disk Paxos的方式。Log为同步地复制f + 1个副本,而Storage Server为异步从Log Servers复制的方式。由于FDB事务依赖于一个逻辑上中心话的Sequencer,这样对于跨地域的系统部署是比较麻烦的。FDB另外引入了一些geo- replication的功能。对于跨区域的复制,FDB可以使用同步 or 异步的方式,写入的时候如果使用同步的方式的话,必然带来写入延迟大大增加的问题。FDB的解决方案中,以下面的两个区域的部署方式为例,其会设置其中的一个为primary region,这个region中会包含完整的系统部署,比如TS、LS以及SS,而standby region中,参与的只有LS和SS。一个region之中,可能会有多个的数据中心。
-
下图中,跨地域复制是通过复制Log完成的,一个region里面的log写入会被同步的复制到各个DC。而这些数据写入复制到另外的region的时候,为了避免增加写入的延迟,只能是使用异步复制的方式。FDB通过使用LogRouters的一个组件来复制。
-
在primary region不可用的时候,就需要一个failover的操作,将primary调度到standby region。而对于个DC中Satellite机房的failover目前是手动处理的。而failcover操作到standby的reigon之后,其不一定有全部的log数据(might not have a suffix of the log)。此时DC1不可用的时候,DC2 中会启动一个新的 transaction management system,log servers这个时候从region 2的这些DCs中启动。另外这个recovery的过程中LogRouters还需要从region1 存活的机房中拉取最后的一些log数据。
-
这就设置到log复制到一个region的其它机房的一些问题。这里可以看出DC 2在处理 DC1 failover的时候,其不一定有全部的数据。FBD会将log数据复制到region 1的另外一些肌肤,以便于在DC1故障的时候也能拉取到最近的log数据。Log复制到同一个region的DCs有不同的策略:1. 同步复制到优先级最高的Satellite,这个故障之后次高的会被同步复制到;2. 同步复制到优先级最高的两个Satellites,其中一个故障之后回到方案1的方式;3. 和第2的不同是只会等待一个返回成功,
In all cases, if no satellites are available, only the LogServers in DC1 are used. With option 1 and 3, a single site (data center or satellite) failure can be tolerated, in addition to one or more LogServer failures (since the remaining locations have multiple log replicas). With option 2, two site failures in addition to one or more LogServer failures can be tolerated.
FDB的另外一个特点是其实现了一个Deterministic Simulator,可以模拟系统中多很多组件,来进行故障注入等的测试。FDB从设计的开始就注意这些分布式系统如何来测试、debug等。以及故障注入测试为例,其可以模拟一下的一些等的内容。另外为了确定下的模拟,还实现了一个Flow的编程语言/测试框架。
The FDB simulator injects machine, rack, and data-center level fail-stop failures and reboots, a variety of network faults, partitions, and latency problems, disk behavior (e.g. the corruption of unsynchronized writes when machines reboot), and randomizes event times. This variety of fault injection both tests the database’s resilience to specific faults and increases the diversity of states in simulation.
0x03 评估
这里的具体信息可以参看[1].
参考
- FoundationDB: A Distributed Unbundled Transactional Key Value Store, SIGMOD ‘21.
