Transaction Optimzations in CockroachDB
0x00 Parallel Commit
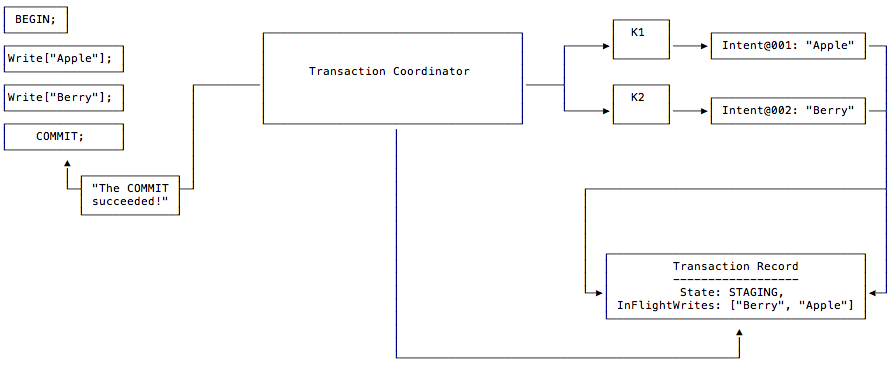
CockroachDB在事务优化方面,在开源的分布式数据库中,是做的比较多的。比如引入了Parallel Commit、Transaction Pipelining、1PC、Non-blocking Transactions等诸多的优化,这些优化好像也影响了后面一些系统的优化策略。以Parallel Commit为例,因为CRDB使用类似于Percolator的2PC的执行方式,其要进行网络交互比较。Parallel Commits操作则使得commit的操作可以异步执行。其优化的思路来自于:一个如果一个事务的所有写入内容都被复制完成之后,2PC的第一步prepare返回了ok,则后面的commit操作是一定能够完成的。所以到了这里就可以先返回成功再去实际地/异步地commit。为了实现这个功能,CRDB引入了一个staging的事务状态,表示一个事务操作的所有写入是否都复制完成了。在Paper[1]中提交到的数据,这个优化取得的效果很明显。其基本思路如下图,其写入的时候:
- 按照CockroachDB基本的分布式事务流程,会先创建一个事务状态记录,transaction record。CRDB选择在第一个range写入这个状态记录估计也是方便来实现在第一个写入操作的时候和事务状态记录一起创建。在引入了 Parallel Commit 和 Lazy Transaction Record Creation优化之后,这个方式存在了一些变化。如下的一个事务流程,在使用Parallel Commit的时候,第一个操作写入一个key “Apple”。第一次写入操作的时候并不会创建一个事务状态记录,写入这个write intent包含指向事务状态记录的信息此时并不存在。每个write intent会赋予一个唯一的sequence number 。另外在CRDB引入了Transaction Pipelining的优化之后,写入的操作可以在操作没有完成的时候就进行事务后面的操作。在写入第二个key “Berry” 时,操作的过程和写入第一个的一样,如果使用了Transaction Pipelining也不需要等待write intent的写入实际完成。
- 后面进入事务commit的操作过程。Client在发送了一个client的指令之后,Coordinator会创建一个staging状态的事务状态记录,并在其中记录下这个事务会写入的key列表。在等待写入操作都完成之后即可返回。事务状态为staging且所有写入都完成的时候,实际上就是一种implicitly committed,而事务状态为committed为一种explicitly committed。而对于读操作,遇到了staging状态的事务写入的write intents,读取操作会先确定相关的事务是否在正常进行过程中。这个通过coordinator和状态记录之间的heartbeating来确定。如果是,则读取操作对应的事务会等待。
- 另外和事务commit相关的优化为1PC 优化,这个优化在很多的2PC方式中都会用到。基本上就是一个事务只会涉及到一个range的时候,就是一个非分布式事务的commit操作,可以直接1PC操作完成。
上面描述的过程,实际上是一个Parallel Commit,Lazy Transaction Record Creation 和 Transaction Pipelining几个优化同时使用的一个操作过程, Transaction Pipelining体现在两次写入操作之间,后面没有依赖于前面的写入可以不用等到前面的写入完成之间操作。Lazy Transaction Record Creation则是指不按照基本的分布式事务流程一上来就创建事务状态记录,而是等待要commit的时候才创建。Parallel Commit在这个例子中则体现在写事务状态记录的时候,不用等待前面的写入操作都完成,可以和这些操作并发进行,此时创建的事务状态为staging。
0x01 Lazy Transaction Record Creation & Transaction Pipelining
从上面可以看出,Lazy Transaction Record Creation的优化是尽量避免一上了来创建事务状态记录。这也可以带来一些好处:最明显的就是对Parallel Commit的支持,CRDB这种支持交互式事务的系统,一般是一开始不知道要写入的那些数据的。这样在要commit的时候,再去创建事务状态记录,就可以直接记录上之前写入的key列表。这样避免在创建事务状态记录之后有修改的操作。CRDB中事务状态记录主要起到3个左右,
1. The write operation commits;
2. The TxnCoordSender heartbeats the transaction;
3. An operation forces the transaction to abort;
对于第一个作用,要处理的是在事务状态记录没有的时候,读取操作遇到了一个write intent的数据怎么处理?这个需要一种在事务记录不存在的时候判断事务存活的逻辑。第二个问题是通过这个事务状态记录来判断事务的存活性,即类似于一个TTL,需要TxnCoordSender的heartbeat操作来续这个TTL。对于第二个问题,没有事务状态记录的情况下,存活性的判断旧改为判断write intent记录到目前的时间,在一定的范围阈值内,则认为其是对应的事务是存活的,否则则可以执行一个abort的操作。第一个问题的处理也应该是使用同样的方式处理。
Transaction Pipelining
事务操作过程中,不同的操作一般的情况下就是先后执行。最直接的方式是每次操作都成功之后在执行下一个操作,这样的方式性能方面会有比较大的问题。而这里优化的方式是Write Pipelining,即每个操作可以直接返回结果,然后异步的执行操作。在Commit的时候再去评估一个操作是否成功。CRDB中了样看出Transaction Pipelining和Parallel Commit是比较配合使用的。
- 在这种情况下,Coordinator通过一些数据记录在inflightOps中,知道目前正在操作中的操作。一个操作在不是commit操作的情况下,且和前面的操作没有重叠,这个操作就可以pipeline执行,不用等操作结构返回。如果一个操作和前面的操作有重叠,就需要等待前面的操作被复制完成,这个称之为pipeline stall。实际的操作被发送到leaseholder节点来执行。和一般的MVCC方式类似,CRDB在事务开始的时候获取了一个时间戳(HLC时间戳),但是注意的是Leaseholder操作可能返回一个更大的时间戳ts。这种情况下,需要检查对应的key在ts到返回的ts中间的这段时间也没有改动,如果没有更新这个txnTs,如果有这个事务就被认为是操作失败,可能需要重试操作。
-
一个SQL语句操作可能设计到多个leaseholder节点,一个leaseholder节点的节点在收到这样的写入请求之后,会先创建一个write intent,并将数据发送给follwers。给follwers发送完成请求之后即可以返回,不会等待操作的完成。从SQL的层面来看,需要写入数据的一般为insert、update这类的更新操作的语句,而这里语句要求返回一个结果给client。一般是更新的行数 或者是 数据已经存在之类的错误信息,而对于查询语句显然是需要返回数据的。所以这里的Transaction Pipelining操作,还是需要给出这样的结果给client,Transaction Pipelining的操作更多的是分布式的一些操作不用等待结构,SQL的操作还是需要返回结构的。
可以以一个阶段的添加操作失误为例说明这几个优化的优化点:在一个有n个顺序执行的简单添加操作的语句的事务,在CRDB朴素的分布式事务方式下面,会有N+2次的Raft流程,+2中一次来自于事务状态记录的创建,一次来自修改为committed的状态,而n次即为每次的添加操作。Lazy Transaction Record Creation可以使得其减少1次,即第一次创建事务状态的记录。在Transaction Pipelining之后,可以让写入数据的操作都重叠,加上事务状态修改的一次,事务完成需要的raft操作优化到2次。Parallel Commit的优化则是在此重叠这两个操作的事件。在事务状态写入这一步,加上staging状态之后,使得其可以不在前面的数据写入的时候同时进行,重叠这些操作的时候。而修改事务状态为committed则异步完成,这样来实现理想情况下1次操作时间的优化。
0x02 Non-blocking Transactions & Transaction Conflicts
在CRDB最近的一个版本中,引入了一个称之为Non-blocking Transactions的优化。这种优化主要是对read-mostly的情况,可以避免和一个写入操作有冲突的读取事务需要等待这个写入操作。在此优化之前,CRDB已经支持follwer read的优化:CRDB使用Follower Reads来实现一些只读事务的操作,满足Follower Reads要满足这样的一些条件:一个是对于一个时间戳为ts的事务,可以读取的数据不会在后面被更新,另外一个就是要去这个non-leaseholder replica已经有了这些数据。也就是要去满足non-leaseholder replica执行一个时间戳为ts的只读事务的时候,leaseholder不能在执行比这个ts还还要小的写入操作,另外就是这个non-leaseholder replica 的raft log的prefix包含了这个ts需要的更新操作。为了满足这些条件,每个leaseholder会记录下进行中的操作,并周期性地通知一个closed timestamp,表示不会在接受小于这个closed timestamp的写入事务。Non-blocking ranges也使用了closed timestamp,另外CRDB还引入了一个non-blocking ranges。在这样的range有这样的一些特性:
- 在这些ranges上面有写入操作的事务,会将其的write timestamp推进到未来的一个时间。No blocking range这里还会涉及到closed timestamp,会讲这个closed timestamp广播出去;
- 写入操作的事务使用一个将来的事务戳写入、提交的时候,需要等到HLC的时间达到了这个事务的 commit timestamp,这个wait操作就是commit wait的操作。另外一个事务因为 future-time的写入在这个事务读取操作的uncertainty窗口内,其读取操作会因为这个future-time的写入也可以将其 commit timestamp推进到未来的一个时间,这样的事务为一个有冲突读取操作的事务,也可能需要commit-wait。
从CRDB这部分的描述来看,其基本思路是为例避免写入操作block了读取操作而将其推进到未来的一个时间,这样应该是会牺牲了一下写入操作了latency,而一般情况下是写入操作会影响到读操作的latency,所以说这里面向read-mostly的情况?另外这里描述的是non-blocking range提供的是transactionally-consistent reads,提供一个到目前的对于读的consistent view:
... all replicas in a non-blocking range are expected to be able to serve transactionally-consistent reads at the present. This means that all follower replicas in a non-blocking range implicitly behave as "consistent read replicas", which are exactly what they sound like: read-only replicas that always have a consistent view of the range's current state.
Transaction Conflicts处理中,CRDB中事务冲突的处理会涉及到concurrency manager,latch manager,lock table等等的部分。另外一个概念为timestamp cache,此何serializability相关:一个读操作的时候,总是会记录一个最大读操作的时间戳到timestamp cache,这个表现为一个读操作的 high-water mark。同样地,一个写入操作也会记录下一个时间戳。这样处理R/W,即读和写冲突的时候。事务操作要求一个读的操作不能被时间戳更靠后的写覆盖。写入操作的时候,会检查 timestamp cache,如果其小于timestamp cache记录的最大的read timestamp,则会尝试讲写入操作的时间戳推进,实际选择的为最大的+1。在一个事务时间戳被推进了之后,这个事务之前的读取操作就需要被重新检查,检查在之前使用的timestamp和被推进之后的timestamp之间有没有冲突的写入,这个操作称之为read refreshing。
- Write intent可以用来处理写写、读写操作直接的冲突,而这里的timestamp cache应该是处理了timestamp逻辑上的冲突。有冲突的操作可以选择一个推大时间戳的操作,但是总是选择推大时间戳也会有问题。CRDB的做法是加入了一个等待的机制,TxnWaitQueue。TxnWaitQueue记录了等待一个事务的事务列表。在被等待的事务commit or abort的时候,会向TxnWaitQueue发送一个信息,通知等待的事务重新运行。在等待的事务也需要不断检查自己的状态,确实自己的事务仍然处于active的状态,否则则讲自己从TxnWaitQueue移除。在实际实现的时候,这个还要处理deadlock、处理事务相关节点crash等等的情况。
- [4]讨论了CRDB中读写时间冲突的处理,对于Write-Read Conflicts则直接使用MVCC机制来解决,读取已经committed的最新版本。对于Read-Write Conflicts的处理,则是使用前面提到的Read Timestamp Cache,通过abort写入或者是推高其时间戳然后重试;Write-Write Conflicts中,前面有更大时间戳的写入,需要abort掉事务 or 使用更大的时间戳来重启事务(前面是更小的时间戳,应该就是使用锁来处理)。
0x03 Something More
另外一个优化是涉及写入的优化。CockroachDB有另外一些可能采用的优化,比如对目前write intent中,lock和intent数据是一次保存,写入write intent的数据写入两条数据。如下面的例子写入Table的key为”b”的数据。这里的一个思路[5]是讲value为事务相关元数据的lock记录改写到一个“lock-table” keyspace,这个思路到是和YugabyteDB的一些做法类似。关于这个优化的讨论比较长[5]。这样会有这样的一些优点: 1. 在scan数据开始之前检查冲突,后面的检查就可以直接简单scan,简化逻辑;2. 避免在底层的kv上生成许多的 deletion tombstones;3. 为一个称之为”blind-write” 的优化创造可能(即讲多个写入合并为一个操作),在和write timestamp cache配合使用可以实现单个key的linearizability,优化write-heavy workloads 的表现;4. 方便支持同时写入多个write intents;5. 使得一些key只会被Put一次,这样就方便使用rocksdb的SingleDelete接口来优化一些删除操作等等。
/Table/"a"/123: {val1}
/Table/"b"/0: {txn: txn1, ts: 999}
/Table/"b"/999: {val2}
/Table/"b"/500: {val3}
/Table/"c"/700: {val4}
这里涉及到的支持一个key多个writite intents的一个提议[7],其思路是优化write-write的冲突,思路来自write snapshot isolation[7]的论文。比如对于如下A的两个事务操作过程。如果允许这种情况下的write-write冲突,两个事务commit的时候。如果两个事务的start ts为commit ts,即Ts(txn1) = Tc(txn1),在事务后面没有遇到到更高时间戳的时候,就会有Ts(txn1) = Tc(txn1)。则这两个事务有Ts(txn1) < Ts(txn2),实际上类似于执行如下B流程的操作。这样允许来一些条件下的write-write冲突。实现WSI这样的思路要求检测read-write的冲突,这个应该就是使用选择CRDB已有的功能。但是实现这个也有不少的麻烦:比如meta key没来的问题(可以利用前面separated lock-table keyspace的思路),比如read读取遇到多个intents如果解决冲突等等
A: r1[x] w2[x] w1[x] c2 c1
B: r1[x] w1[x] c1 w2[x] c2
关于”blind-write” ,Spanner有使用这样的一个优化,在Cloud Spanner的文档上面有记录。写锁止之间的相互冲突限制了多个事务写入操作的并发性,对于这个问题,blind-write的基本思路,是将多次的写入合并为一次写入,当然能够合并的写入操作会有一些条件。比如两个写入之后不能有读取操作,中间没有被读取这样的两个写入实际上和一个写入类似。在Spanner的文档描述如下:
... 在Spanner中,我们可以利用分配给事务的时间戳使写锁在许多情况下得以共享。具体来说,对于单个分片事务中的盲写(在没有预先读取数据的情况下将数据写入同一个事务),我们可以允许写入相同数据的多个事务并行进行。由于从 TrueTime 分配给每个写入操作的时间戳可确保不同,因此我们能够避免形成竞争条件:不同时间戳的数据可以按时间戳顺序分别应用,从而避免数据损坏。我们发现,对于Google内部系统向Spanner执行的盲写而言,这可以大大提升吞吐量。
参考
- CockroachDB: The Resilient Geo-Distributed SQL Database, SIGMOD ‘20.
- Transaction Layer: https://www.cockroachlabs.com/docs/v21.1/architecture/transaction-layer.html.
- Follower Read: https://www.cockroachlabs.com/docs/v21.1/follower-reads#how-follower-reads-work.
- Serializable, Lockless, Distributed: Isolation in CockroachDB, https://www.cockroachlabs.com/blog/serializable-lockless-distributed-isolation-cockroachdb/.
- Separated lock-table keyspace, https://github.com/cockroachdb/cockroach/issues/41720.
- Aallow multiple intents, https://github.com/cockroachdb/cockroach/issues/5861.
- A Critique of Snapshot Isolation, EuroSys ’12.
